第四篇:基于深度学习的人脸特征点检测 - 数据预处理
在上一篇博文中,我们整理了300-W、LFPW、HELEN、AFW、IBUG和300-VW这6个数据集,使用Python将特征点绘制在对应的图片上,人工验证了数据集的正确性,最终获得了223034个人脸特征点数据样本。但是这些样本不能直接送入神经网络处理,接下来我们将讨论造成这种问题的原因以及对应的解决办法。
两步走的策略
深度神经网络的确很强大,但是在当前的技术条件下,合适的操作策略可以降低网络的学习负担,获得更好的检测效果。如果你仔细查阅第二篇博文中的引用文献[1],不难发现论文中神经网络的输入层存在一个固定的大小为:128 × 128 × 3(其中3代表彩色图像的通道数)。这里输入的128×128大小并非类似之前数据库中完整的图像,而是图像中仅仅包含人脸的一小块区域。为何这样做?
想象一下,如果我们要手工从图像中标记68个特征点,大致可以分为两步:
- 从一张完整的图像中找到人脸。
- 从找到的人脸区域中标记出特征点。
如果在动手前,有其他人提前把图像中的人脸找到,并将对应区域裁剪出来给你,工作量一下少了很多,我们就可以专心的聚焦在特征点提取这项任务上来。神经网络的训练过程正是一个学习的过程。人脸的检测与特征定的标记可以看做是两项不太相关的任务。如果强迫一个神经网络去同时学习这两种规则,必然会要求神经网络的学习能力足够强大。学习能力强大的神经网络通常情况下会需要更多的参数,这样会使得神经网络的训练与应用变得更加的复杂。这个时候将这两步拆分开来处理,让神经网络去专心的学习第二项规则,看起来是个更好的方法。至于第一项任务,现在有众多的开源或者商业化的方案可以选择。在这里我们将利用OpenCV中同样是基于深度神经网络的开源实现[2]。
按照这种思路,将来的检测行为将会是:
- 使用人脸检测器从图片中检测到人脸区域。
- 仅仅将人脸区域送入神经网络进行处理,获得特征点位置。
因此在训练的时候,送入神经网络的也必须是仅仅包含人脸的区域。那这部分人脸区域又应该如何去获得呢?
人脸区域的两种获取策略
一个稳定的,规律的获取人脸区域边界框的方法有助于生成优质的数据供神经网络学习,且该区域最好满足以下条件:
- 外观为正方形。
- 包含全部人脸特征点。
- 合适的尺寸:边界框与特征点之间的距离合适,既不交叠,也不特别远离。
- 与上一级人脸检测器的边界框之间存在相关性。
从这一点出发,我暂时想到了两种区域提取策略。
策略0
最为直观的区域提取策略是从已知的68个特征点出发,确定一个包含这68个特征点的矩形框作为人脸区域。这样做的难点在于:矩形框的具体确立规则是怎样的。例如,最简单的方法是选择这样一个矩形,使它刚好包含所有特征点。

但是这样子做意味着至少有两个点会处矩形框的边缘这种极端情况。如果在这个基础上扩大一点范围可能会好一点,但是这个“一点”又是多少呢?太小可能不足以覆盖足够的图像范围,神经网络无法获得足够的学习区域;太大有可能会产生冗余数据,对于训练检测都是不利的。
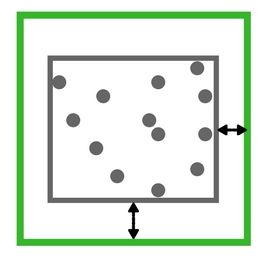
所以这里需要人为的设定扩张范围的数值,即引入了一个经验值。这种方法看上去简单而已,但是扩张范围的经验值判定方法与依据需要研究,为了方便讨论,将其命名为Method 0。
策略1
另一种思路是从特征点检测的上一级入手,即根据人脸检测算法输出的人脸区域来确认神经网络接收输入区域的大小。这种方式的好处在于保证了训练过程与检测过程输入数据的一致性,减少了偏差,让神经网络在推演时看到的输入数据区域“似曾相识”。该方法出发点与Method 0截然不同,为方便讨论将其命名为Method 1。
两种提取策略的细节
这两种策略都能够生成包含人脸的矩形区域,在实际应用中要配合起来使用,总流程图如下所示。
从原理上看策略0比策略1简单;策略1由于考虑到了前置的人脸检测模块,我个人感觉效果会比策略0要好,只是实现起来更加复杂一点。
策略0:根据特征点推算人脸区域
若直接采用特征点群的边缘一定能得到人脸区域边界框,但是它的形状不一定是方形。最为简单的方法是将该边界框较长的一条边作为边长,重新划定区域。之后为了让边缘特征点位于边界框内,需要对该区域做缩放操作,放大的范围我选择为矩形边长的1/5。
这样的操作过程会遇到意外情况,主要是变更边界框之后边界框可能会超出图像范围,此时需要通过移动或者缩小边界框的方式进行调节。
策略1:根据人脸检测结果推算人脸区域
策略1的第一步是要从图片中检测出人脸,你可以自己写代码实现这两项功能。为了方便后续使用,我对OpenCV的人脸检测开源实现做了一些修改,具体的内容可以参考我Github上的repo[3]。修改之后的detect_face.py可以作为模块导入其它Python脚本。在我们上一篇博文中的示例代码[4]的对应位置里加入如下三行,即可将人脸检测区域标记到图像中。
import detect_face as fd
conf, facebox = fd.get_facebox(img, threshold=0.5)
fd.draw_result(img, conf, facebox)
之后就可以在图像中看到人脸边界框与特征点之间的关系了。这里放几张样本图片。


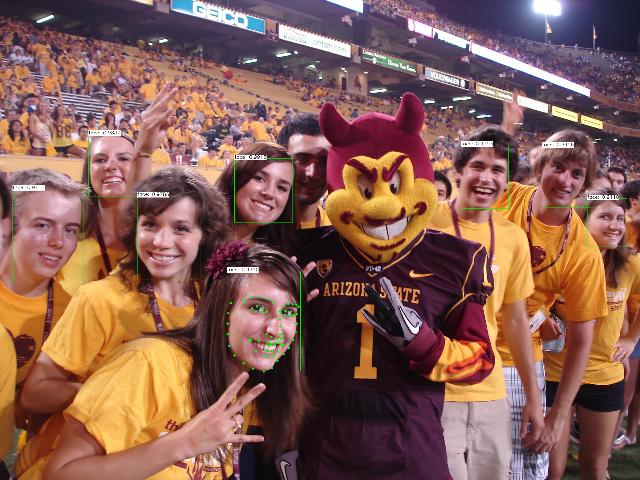

如果把所有样本图片大致浏览一遍就会发现,OpenCV这款人脸检测器可以检测到大部分人脸,包括大侧脸与部分遮挡的情形;坏消息则是:
- 大部分的特征点都没有在人脸边界框的矩形区域内。
- 人脸边界框的形状不是正方形,总体上看呈现出竖直的长方形,且偏向额头的方向。
- 人脸检测器会检测出未标记特征点的人脸。
这三点是必须要解决的问题。
通过对人脸边界框的大量观察,我发现边界框的高度总是大于宽度,所以将边界框的宽度直接扩展到与高度相同便可满足外观为方形这一条件。同时宽度的扩展还将原本位于边界框外部的特征点包含了进来,带来了额外的好处。
由于边界框的位置总是偏上,导致下颚处的特征点总是处于边界框外部。为此我将边界框的位置总体向下移动,移动的大小为边界框的高度与宽度之差的一半,即(height - width)/2。
至于未标记的人脸,只需要结合特征点来判断,将包含所有特征点的边界框作为有效边界框即可。
修正后的边界框的尺寸其实来自于人脸检测器的输出,所以第4个条件蕴含其中。接下来我们在原来的detect_face.py基础上进行修正,添加了两个函数分别负责实现以上功能并将将结果绘制在图片上。你可以参考我在Github上的开源实现[3:1]。
最终的结果示例如下,其中的白色外框代表扩张后的区域:


单从肉眼看起来还不错,边界框没有与特征点交叠,两者之间的距离也不算太远,所以第三个条件勉强算是满足吧。不过也有一些例外:
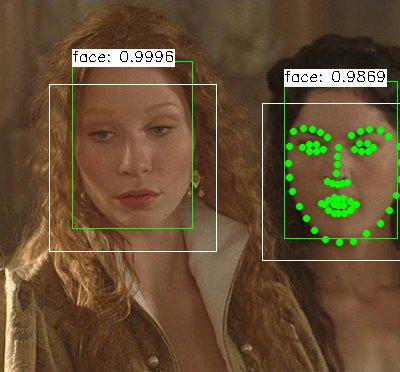
由于人脸位于图片的边缘,扩张后的人脸区域跑到了图像外部。
应对意外情况的出现
策略0与策略1都会遇到边界框超出图片范围这类情况,在将来应用的时候也许会经常出现。例如人从外部移动到摄像机画面内或者从画面内移出。因此当边界框的某一边或者多个边超出了图像范围时,需要进行特殊的处理。这里我把自己的处理思路列出来,你也许会有更好的方法,欢迎交流。
当边界框的两个对角顶点有任一位于图像外部时:
- 首先采取移动策略,判断边界框是否可以完整平移到画面范围内。
- 若移动条件不满足,则采取缩放策略,尝试缩小边界框。
- 若缩放条件不满足,则采取最终策略,将全部特征点的最小包围框作为人脸区域。
平移边界框
平移的逻辑较为简单,首先计算边界框相对图像边界的偏移程度,然后向相反的方向移动对应点坐标即可。下图为平移后的结果示例,绿色框为初始边界框;白色为扩张为正方形后的区域,可见下方已经超出图像区域;蓝色为平移后的边界框,已经全部移入画面内。

要留意的地方是当边界框大于图像的任意边长时,平移策略是无效的,这需要使用缩放策略。
缩放边界框
缩放边界框要稍微复杂一点,我的逻辑如下。
- 首先计算边界框与图片的相交区域,获得一个矩形。
- 以较小的边为基准,将矩形区域裁切为正方形。
- 如果被裁切的矩形正好位于图片中间,则从两侧对称裁切。如果有一边与图像边缘重合,则裁切另一边。
经过裁切后,对于特别宽或者特别高的图像,我们也可以获得一个可用的人脸区域了,如下图。

最最最极端的情况
如果以上两种方法都无法获得一个有效的人脸区域,则被归类为极端情况,直接将包围全部特征点的最小边界框作为人脸区域。不过要小心的是,由于我们会将人脸区域提取为单独的文件,一定要对这些特征点进行检查。例如下列图片中部分特征点的坐标已经跑到了图片的外侧,如果不进行坐标检查的话可能会引发程序错误。。

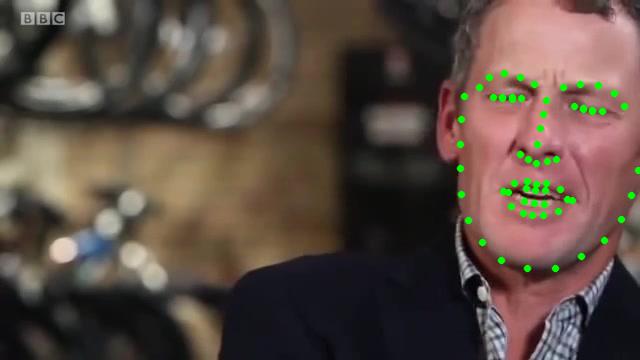

为了方便神经网络学习,我将特征点坐标位于图像外部的点归类为无效数据,直接丢弃处理。这一类数据共有1469个,主要集中在300-VW数据库中,尤其是编号007和044两段视频,你可以打开检查下。
结果验证
经过以上的处理,原始数据库中的可提取出的有效样本数量为221565。随机挑选几张如下图所示。

结果并不完美,不过考虑到我们有22万多个样本,希望大样本数量能够弥补这些不足吧。
下一步计划
目前为止,从数据集图片中提取有效人脸区域这一目标已经完成,获得了适用于深度神经网络的有效样本。不过从计算效率的角度出发,这些数据不适合直接用在神经网络的训练过程中。在下一篇博文中,我们将利用TensorFlow这一深度学习框架,将提取出来的有效人脸区域以及对应的68个特征点坐标打包成为TensorFlow可以直接读取利用的TFRecord文件。使用TFRecord文件可以极大的简化神经网络训练过程中的IO操作,如果您不熟悉可以参考我写的这篇文章[5],或者TensorFlow的官方文档[6]。
PS. 本文的实现已在Gitbub上开源,地址是:
https://github.com/yinguobing/image_utility/blob/master/pts_tools.py
-
Approaching Human Level Facial Landmark Localization by Deep Learning ↩︎
-
https://github.com/opencv/opencv/blob/master/samples/dnn/resnet_ssd_face_python.py ↩︎
-
https://github.com/yinguobing/image_utility/blob/master/detect_face.py ↩︎ ↩︎
-
基于深度学习的人脸特征点检测 - 数据集整理 ↩︎
-
TensorFlow中的TFRecord文件 ↩︎
-
https://tensorflow.google.cn/api_docs/python/tf/data/TFRecordDataset ↩︎