MCTS学习笔记
MCTS树学习
MCTS,即蒙特卡罗树搜索,是一类搜索算法树的统称,可以较为有效地解决一些搜索空间巨大的问题。
如一个8*8的棋盘,第一步棋有64种着法,那么第二步则有63种,依次类推,假如我们把第一步棋作为根节点,那么其子节点就有63个,再往下的子节点就有62个……
如果不加干预,树结构将会繁杂,MCTS采用策略来对获胜性较小的着法不予考虑,如第二步的63种着法中有10种是不可能胜利的,那么这十个子节点不予再次分配子节点。
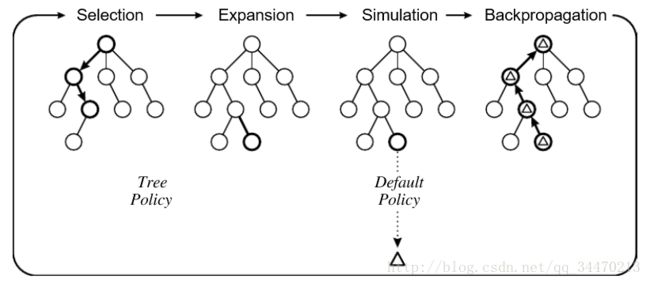
MCTS的主要步骤分为四个:
1, 选择(Selection)
即找一个最好的值得探索的结点,通常是先选择没有探索过的结点,如果都探索过了,再选择UCB值最大的进行选择(UCB是由一系列算法计算得到的值,这里先不详细讲,可以简单视为value)
2, 扩展(Expansion)
已经选择好了需要进行扩展的结点,那么就对其进行扩展,即对其一个子节点最为下一步棋的假设,一般为随机取一个可选的节点进行扩展。
3, 模拟(Simulation)
扩展出了子节点,就可以根据该子节点继续进行模拟了,我们随机选择一个可选的位置作为模拟下一步的落子,将其作为子节点,然后依据该子节点,继续寻找可选的位置作为子节点,依次类推,直到博弈已经判断出了胜负,将胜负信息作为最终得分。
4, 回溯更新(Backpropagation)
将最终的得分累加到父节点,不断从下向上累加更新。
对于UCB值,计算方法很简单,公式如下:
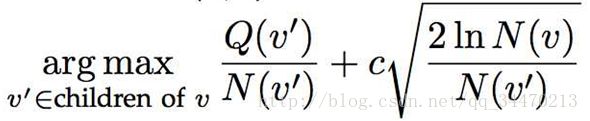
其中v'表示当前树节点,v表示父节点,Q表示这个树节点的累计quality值,N表示这个树节点的visit次数,C是一个 常量参数,通常值设为1/√2
接下来再讨论怎么使用Python实现MCTS树。
首先树的每个节点Node需要记录其父节点Node parent,和子节点Node children[],用于计算UCB的这个节点的quality值和visit次数。
def __init__(self):
self.parent = None
self.children = []
self.visit_times = 0
self.quality_value = 0.0
self.state = None
class State(object):
def __init__(self):
self.value = 0
self.round = 0
self.choices = []
整棵树需要实现的功能则是,在一个环境下,选择出一个最有可能获胜的策略。选择的方法则是通过以上介绍的四个步骤不停模拟得到每个选择的value。
其中,tree_policy函数实现了Selection和Expansion,default_poliy函数实现的是Simulation过程,backup函数是BackPropagation的实现。
def MCTS(node):
computation_budget = 3
for i in range(computation_budget):
# 1\. 找到最合适的可扩展子节点
expand_node = tree_policy(node)
# 2\. 随机选择下一步策略对此子节点进行模拟
reward = default_policy(expand_node)
# 3\. 将模拟结果向上回传
backup(expand_node, reward)
# 最终得到胜利的可能性最大的子节点
best_next_node = best_child(node, False)
return best_next_node
tree_policy:选择最合适的子节点,选择策略如下:
1,如果当前的根节点是叶子节点,即没有子节点可以扩展,以开头下棋的例子来讲,即是已经判断出了胜负或者棋盘已满的情况下,则直接返回当前节点。
2,如果还有没有选择过的叶子节点(下一步的某个位置的着法还没有被模拟过),就在没有选择过的方法中选择一个返回。
3,如果所有可选择的结点都已经选择过(当前环境下所有的着法都已经试过),那么往下选择UCB值最大的子节点,直到满足1或2的情况,到达叶子节点或者出现未选择过的结点。
def tree_policy(node):
# 是否是叶子节点
while not node.get_state().is_terminal():
# 如果全部可选的结点都选择过
if node.is_all_expand():
# 选择UCB最大的值
node = best_child(node, True)
else:
# 随机选择一个节点返回
sub_node = expand(node)
return sub_node
# 返回找到的最佳子节点
return node
default_policy:对当前情况进行模拟,直到判断出胜负。
策略为:输入需要扩展的结点,随机操作后 创建新的结点,直到最后遇到叶子节点,得到该次模拟的reward,然后将reward返回。
def default_policy(node):
# 获取当前点的环境状态
current_state = node.get_state()
# 如果没有遇到叶子节点,就一直循环
while current_state.is_terminal() == False:
# 随机选取一个子节点,返回新的环境参数
current_state = current_state.get_next_state_with_random_choice()
# 结束后,根据当前的环境判断胜负,即获得的reward值,并将其返回
final_state_reward = current_state.compute_reward()
return final_state_reward
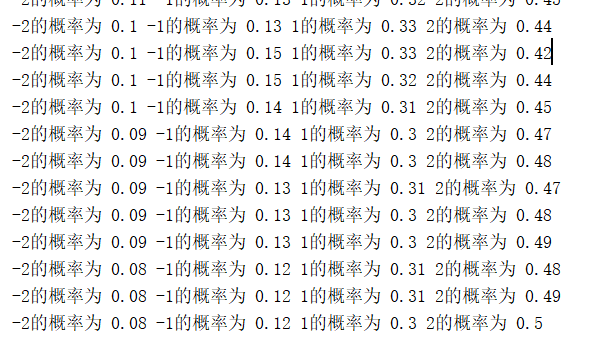
关于这个算法,我简单做了一个实现,每次从数组[1, -1, 2, -2]之间随机取一个数做累加,共累计MAX_DEPTH层,使最终的和最大,我们根据运行结果可以看到,开始-1, -2的概率比较大,但是随着训练层数的增大,越来越小,而1,2的比例会越来越大。
import sys
import math
import random
MAX_CHOICE = 4
MAX_DEPTH = 50
CHOICES = [1, -1, 2, -2]
class State(object):
def __init__(self):
self.value = 0
self.round = 0
self.choices = []
def new_state(self):
choice = random.choice(CHOICES)
state = State()
state.value = self.value + choice
state.round = self.round + 1
state.choices = self.choices + [choice]
return state
def __repr__(self):
return "State: {}, value: {}, choices: {}".format(
hash(self), self.value, self.choices)
class Node(object):
def __init__(self):
self.parent = None
self.children = []
self.quality = 0.0
self.visit = 0
self.state = None
def add_child(self, node):
self.children.append(node)
node.parent = self
def __repr__(self):
return "Node: {}, Q/N: {}/{}, state: {}".format(
hash(self), self.quality, self.visit, self.state)
def expand(node):
states = [nodes.state for nodes in node.children]
state = node.state.new_state()
while state in states:
state = node.state.new_state()
child_node = Node()
child_node.state = state
node.add_child(child_node)
return child_node
# 选择, 扩展
def tree_policy(node):
# 选择是否是叶子节点,
while node.state.round < MAX_DEPTH:
if len(node.children) < MAX_CHOICE:
node = expand(node)
return node
else:
node = best_child(node)
return node
# 模拟
def default_policy(node):
now_state = node.state
while now_state.round < MAX_DEPTH:
now_state = now_state.new_state()
return now_state.value
def backup(node, reward):
while node != None:
node.visit += 1
node.quality += reward
node = node.parent
def best_child(node):
best_score = -sys.maxsize
best = None
for sub_node in node.children:
C = 1 / math.sqrt(2.0)
left = sub_node.quality / sub_node.visit
right = 2.0 * math.log(node.visit) / sub_node.visit
score = left + C * math.sqrt(right)
if score > best_score:
best = sub_node
best_score = score
return best
def mcts(node):
times = 5
for i in range(times):
expand = tree_policy(node)
reward = default_policy(expand)
backup(expand, reward)
best = best_child(node)
return best
def main():
init_state = State()
init_node = Node()
init_node.state = init_state
current_node = init_node
for i in range(MAX_DEPTH):
a = 0.0
b = 0.0
c = 0.0
d = 0.0
current_node = mcts(current_node)
for j in range(len(current_node.state.choices)):
if current_node.state.choices[j] == -2:
a += 1
if current_node.state.choices[j] == -1:
b += 1
if current_node.state.choices[j] == 1:
c += 1
if current_node.state.choices[j] == 2:
d += 1
print("-2的概率为", round(a/(i + 1.0), 2),
"-1的概率为", round(b/(i + 1.0), 2),
"1的概率为", round(c/(i + 1.0), 2),
"2的概率为", round(d/(i + 1.0), 2))
if __name__ == "__main__":
main()
运行结果: