Channel.write() 和 ChannelHandlerContext.write() 的区别
看了下netty 源代码, 终于明白了
Channel.write() 和 ChannelHandlerContext.write() 的区别了
网上说的都不是很清楚
Channel.write() 和 ChannelHandlerContext.write() 的区别了
网上说的都不是很清楚
首先注明我的netty版本
io.netty
netty-all
4.0.36.Final
ChannelPipeline处理ChannelHandler的顺序:
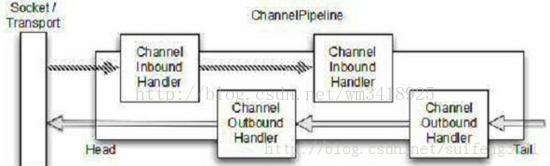
pipeline中的handler 处理的请求分为两类: 读 和 写
对于读请求 : 从handler链表的 head 到 tail 挨个的处理, 跳过 ChannelOutboundHandler
对于写请求 : 从handler链表的 tail 到 head 挨个的处理, 跳过 ChannelInboundHandler
1 调用
Channel.write(), 会直接调用ChannelPipeline.write()
@Override
public ChannelFuture write(Object msg) {
return pipeline.write(msg);
}
@Override
public ChannelFuture write(Object msg, ChannelPromise promise) {
return pipeline.write(msg, promise);
}
@Override
public ChannelFuture writeAndFlush(Object msg) {
return pipeline.writeAndFlush(msg);
}
@Override
public ChannelFuture writeAndFlush(Object msg, ChannelPromise promise) {
return pipeline.writeAndFlush(msg, promise);
}而 ChannelPipeline .write() 直接调用 tail指向的 最后一个handler的 write
@Override
public ChannelFuture write(Object msg) {
return tail.write(msg);
}
@Override
public ChannelFuture write(Object msg, ChannelPromise promise) {
return tail.write(msg, promise);
}
2 调用ChannelHandlerContext.write()
首先通过findContextOutbound找到当前ChannelHandlerContext的上一个OutboundContext
再调用它执行具体的写入逻辑
private void write(Object msg, boolean flush, ChannelPromise promise) {
AbstractChannelHandlerContext next = findContextOutbound();
EventExecutor executor = next.executor();
if (executor.inEventLoop()) {
next.invokeWrite(msg, promise);
if (flush) {
next.invokeFlush();
}
} else {
AbstractWriteTask task;
if (flush) {
task = WriteAndFlushTask.newInstance(next, msg, promise);
} else {
task = WriteTask.newInstance(next, msg, promise);
}
safeExecute(executor, task, promise, msg);
}
} private AbstractChannelHandlerContext findContextOutbound() {
AbstractChannelHandlerContext ctx = this;
do {
ctx = ctx.prev;
} while (!ctx.outbound);
return ctx;
}
Channel.write() : 从 tail 到 head 调用每一个outbound 的
ChannelHandlerContext.write
ChannelHandlerContext.write() : 从当前的Context, 找到上一个outbound, 从后向前调用 write