机器学习项目-----0-9手写数字识别
lintcode题目数据链接
题目描述
MNIST是计算机视觉领域的“hello world”数据集。 自1999年发布以来,这种手写图像的经典数据集已经成为基准分类算法的基础。 随着新的机器学习技术的出现,MNIST仍然是研究人员和学习者的可靠资源。
这个题目,您的目标是正确识别数以万计的手写图像数据集中的数字。
每一张图片,图片里面写了一个数字可能是0-9,然后需要设计算法判断出这个数字是0-9中哪一个数字。 我们鼓励您尝试不同的算法,以便第一手掌握哪些方法或者技术可行。
问题解决:
这里要求的是用神经网络解决问题,但是我们作为初学者,使用聚类算法knn来实现比较简单。knn具有以下特点。

1. 分析数据:这一步是至关重要的,我们对于不同的问题得到的数据可能千奇百怪,所以一个优秀的数据处理工程师必须掌握数据预处理的技巧。回到正题,注意下输入格式,
{ 每幅图像的高度为28像素,宽度为28像素,总共为784像素。每个像素都有一个与之相关的像素值,表示该像素的亮度或暗度,数字越高意味着越暗。这个像素值是一个0到255之间的整数。
训练数据集(train.csv)有785列。第一列称为“标签”,是用户绘制的数字。其余列包含关联图像的像素值。
训练集中的每个像素列都有一个名称,如pixelx,其中x是0到783之间的整数。为了在图像上定位这个像素,假设我们已经将x分解为x = i * 28 + j,其中i和j是0到27之间的整数。然后,pixelx位于28 x 28矩阵的第i行和第j列(索引为零)。}
输入csv文件的第一列是真实值(标签),后面的若干列就是图像矩阵的值了。
2.读取数据并做预处理: 读取图像的矩阵值后,我们需要构造每张图像的特征向量,这里是28*28。因为我们采用的方法是:俩个向量的欧式距离代表了俩张图的相似程度,所以需要将矩阵转换成为一维的向量。
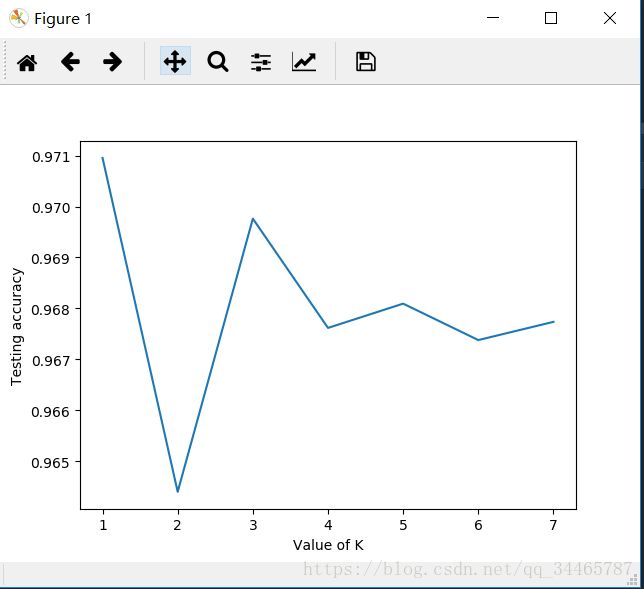
3. 选取合适的k使得knn的评估最优:这里我们用正确率来评估模型的优秀程度,所以枚举k (范围自定义),1-8。这里需要对训练数据做一个划分,原理就是我们不能把所有数据全部训练之后,再从中抽取数据进行检验和评估,所以这里我们做了4:1的划分,4/5的数据做训练,1/5的数据做评估,这样的好处是我们选择的是泛化能力最优的模型。
4.预测和分析结果:找到最优的k之后,就可以将训练数据全部拿来做训练,得到的模型再去预测测试数据即可。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import time
from sklearn.metrics import accuracy_score,classification_report,confusion_matrix
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
# train has 42000 row ,it means 42000 images
train_image = 42000
def load_data(data_dir,data_row):
train = pd.read_csv(data_dir + "train.csv").values
# print(train.shape)
X_train = train[0:data_row,1:] # 因为这里的每一项是一个矩阵,所以用X表示
y_train = train[0:data_row,0] # 每项是一个值,用y表示,区分下大小写
Pre_test = pd.read_csv(data_dir + "test.csv").values
Pre_test = Pre_test[0:data_row]
return X_train,y_train,Pre_test
Origin_X_train,Origin_y_train,Pre_X_test = load_data("./Data/",train_image)
# 测试输入数据的图像
# plt.imshow(Origin_X_train[3].reshape(28,28))
# plt.show()
# 枚举法比较各个不同k使得精度最高,用最终的knn来训练上面的数据
def GetK_With_MaxAccuracy(Origin_X_train,Origin_y_train):
# 对训练数据做划分,用来验证模型的准确率
X_train,X_valid,y_train,y_valid = train_test_split(Origin_X_train,Origin_y_train,test_size=0.2,random_state=0)
# 进行knn训练
ans_k = 0
k_range = range(1,8)
scores = []
for k in k_range:
print("k = ",str(k),"begin:")
start = time.time()
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train,y_train)
y_pre = knn.predict(X_valid)
accuracy = accuracy_score(y_valid,y_pre)
scores.append(accuracy)
end = time.time()
print(classification_report(y_valid,y_pre))
print(confusion_matrix(y_valid,y_pre))
print(scores)
plt.plot(k_range, scores)
plt.xlabel('Value of K')
plt.ylabel('Testing accuracy')
plt.show()
ans_k = scores.index(max(scores))
return ans_k
def Train_And_Test(Origin_X_train,Origin_y_train):
value_k = GetK_With_MaxAccuracy(Origin_X_train,Origin_y_train)
knn = KNeighborsClassifier(n_neighbors=value_k)
knn.fit(Origin_X_train,Origin_y_train)
y_pre = knn.predict(Pre_X_test)
lens = len(y_pre)
pd.DataFrame({"ImageId":list(range(1,lens+1)),"Label":y_pre}).to_csv('Digit_Recognize_Result.csv',index=False,header=True)
Train_And_Test(Origin_X_train,Origin_y_train)
效果截图:
这是对于不同的k值得到的不同精确率。在这个数据中,k=1时的模型是最优的。