Graph Neural Networks (GNN)(二):Spectral-GNN 引言和导入
1. 概述
前面讲了 Spatial-GNN Graph Neural Networks (GNN)(一):Spatial - GNN 的基本原理和一些典型的实现。这一篇主要介绍一下另外一大类:Spectral-GNN。这一类一开始理解起来会比较抽象,因为涉及太多数学、信号处理等方面的内容,我一开始也陷入了这些困境里面。但是通过阅读了几位大牛的知乎或者博客之后,发现其实本质和 Spatial-GNN 是差不多的,只是理解的角度和出发点有些差异。
参考链接:
如何理解 Graph Convolutional Network(GCN)?-- Johnny Richards 的回答
如何理解 Graph Convolutional Network(GCN)?-- superbrother 的回答
本质:图中的每个结点无时无刻不因为邻居和更远的点的影响而在改变着自己的状态直到最终的平衡,关系越亲近的邻居影响越大。
要想理解这一系列的 GNN,最重要的是理解 Laplacian 矩阵的作用和原理。这样这一类的方法无非就是解法的不同 – 傅里叶变换只是将问题从顶点域(空间域)转换到频谱域去处理。上一篇的 Spatial-GNN 其实就是直接在顶点域(空间域)解。
2. 引入 – 热传导
众所周知,没有外接干预的情况下,热量从温度高传播到温度低的地方并且不可逆,根据著名的牛顿冷却定律(Newton Cool’s Law),热量传递的速度正比于温度梯度,直观上也就是某个地方A温度高,另外一个B地方温度低,这两个地方接触,那么温度高的地方的热量会以正比于他们俩温度差的速度从A流向B。
2.1 从一维空间开始
从一维空间开始我们先建立一个一维的温度传播的模型,假设有一个均匀的铁棒,不同位置温度不一样,现在我们刻画这个铁棒上面温度的热传播随着时间变化的关系。预先说明一下,一个连续的铁棒的热传播模型需要列温度对时间和坐标的偏微分方程来解决,我们不想把问题搞这么复杂,我们把空间离散化,假设铁棒是一个一维链条,链条上每一个单元拥有一致的温度,温度在相邻的不同的单元之间传播,如下图:

对于第 i i i 个单元,它只和 i − 1 i - 1 i−1 与 i + 1 i + 1 i+1 两个单元相邻,接受它们传来的热量(或者向它们传递热量,只是正负号的差异而已),假设它当前的温度为 ϕ i \phi_{i} ϕi,那么就有:
d ϕ i d t = k ( ϕ i + 1 − ϕ i ) − k ( ϕ i − ϕ i − 1 ) \frac{d \phi_{i}}{d t}=k\left(\phi_{i+1}-\phi_{i}\right)-k\left(\phi_{i}-\phi_{i-1}\right) dtdϕi=k(ϕi+1−ϕi)−k(ϕi−ϕi−1)
k k k 和单元的比热容、质量有关是个常数。右边第一项是下一个单元向本单元的热量流入导致温度升高,第二项是本单元向上一个单元的热量流出导致温度降低。做一点微小的数学变换可以得到:
d ϕ i d t − k [ ( ϕ i + 1 − ϕ i ) − ( ϕ i − ϕ i − 1 ) ] = 0 \frac{d \phi_{i}}{d t}-k\left[\left(\phi_{i+1}-\phi_{i}\right)-\left(\phi_{i}-\phi_{i-1}\right)\right]=0 dtdϕi−k[(ϕi+1−ϕi)−(ϕi−ϕi−1)]=0
注意观察第二项,它是两个差分的差分,在离散空间中,相邻位置的差分推广到连续空间就是导数,那么差分的差分,就是二阶导数!所以,我们可以反推出铁棒这样的连续一维空间的热传导方程就是:
∂ ϕ ∂ t − k ∂ 2 ϕ ∂ x 2 = 0 \frac{\partial \phi}{\partial t}-k \frac{\partial^{2} \phi}{\partial x^{2}}=0 ∂t∂ϕ−k∂x2∂2ϕ=0
同理,在高维的欧氏空间中,一阶导数就推广到梯度,二阶导数就是我们今天讨论的主角——拉普拉斯算子:
∂ ϕ ∂ t − k Δ ϕ = 0 \frac{\partial \phi}{\partial t}-k \Delta \phi=0 ∂t∂ϕ−kΔϕ=0
其中 Δ \Delta Δ 这个符号代表的是对各个坐标二阶导数的加和,现在的主流写法也可以写作 ∇ 2 \nabla^{2} ∇2。
综上所述,我们发现这样几个事实:
- 在欧氏空间中,某个点温度升高的速度正比于该点周围的温度分布,用拉普拉斯算子衡量。
- 拉普拉斯算子,是二阶导数对高维空间的推广。
2.2 图(Graph)上热传播模型的推广
现在,我们依然考虑热传导模型,只是这个事情不发生在欧氏空间了,发生在一个Graph上面。这个图上的每个结点(Node)是一个单元,且这个单元只和与这个结点相连的单元,也就是有边(Edge)连接的单元发生热交换。例如下图中,结点1只和结点0、2、4发生热交换,更远的例如结点5的热量要通过4间接的传播过来而没有直接热交换。
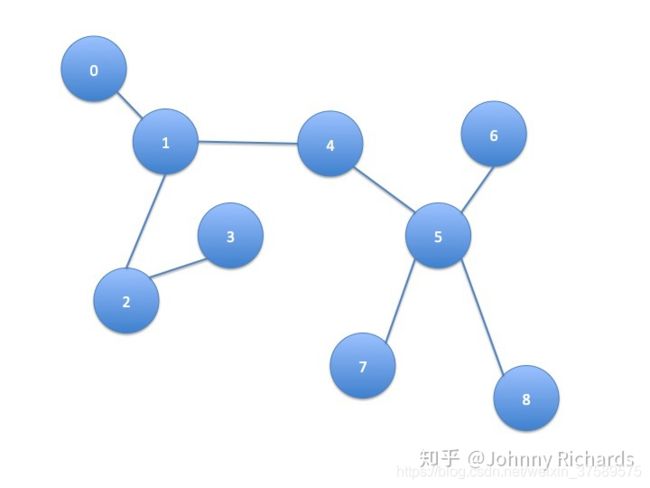
我们假设热量流动的速度依然满足牛顿冷却定律,研究任一结点 i i i ,它的温度随着时间的变化可以用下式来刻画:
d ϕ i d t = − k ∑ j A i j ( ϕ i − ϕ j ) \frac{d \phi_{i}}{d t}=-k \sum_{j} A_{i j}\left(\phi_{i}-\phi_{j}\right) dtdϕi=−k∑jAij(ϕi−ϕj)
其中 A A A 是这个图的邻接矩阵(Adjacency Matrix),定义非常直观: 对于这个矩阵中的每一个元素 A i j A_{i j} Aij ,如果结点 i i i 和 j j j 相邻,那么 A i j = 1 A_{i j}=1 Aij=1 ,否则 A i j = 0 A_{i j}=0 Aij=0。在这里,我们只讨论简单情况:
- 这张图是无向图, i i i 和 j j j 相邻那么 j j j 和 i i i 也相邻,所以 A i j = A j i A_{i j}=A_{j i} Aij=Aji,这是个对称阵。
- 结点自己到自己没有回环边,也就是 A A A 对角线上元素都是 0 0 0。
所以不难理解上面这个公式恰好表示了只有相邻的边才能和本结点发生热交换且热量输入(输出)正比于温度差。我们不妨用乘法分配律稍微对上式做一个推导:
d ϕ i d t = − k [ ϕ i ∑ j A i j − ∑ j A i j ϕ j ] = − k [ deg ( i ) ϕ i − ∑ j A i j ϕ j ] \begin{aligned} \frac{d \phi_{i}}{d t} &=-k\left[\phi_{i} \sum_{j} A_{i j}-\sum_{j} A_{i j} \phi_{j}\right] \\ &=-k\left[\operatorname{deg}(i) \phi_{i}-\sum_{j} A_{i j} \phi_{j}\right] \end{aligned} dtdϕi=−k[ϕij∑Aij−j∑Aijϕj]=−k[deg(i)ϕi−j∑Aijϕj]
先看右边括号里面第一项, deg ( ⋅ ) \operatorname{deg}(\cdot) deg(⋅) 代表对这个顶点求度(degree),一个顶点的度被定义为这个顶点有多少条边连接出去,很显然,根据邻接矩阵的定义,第一项的求和正是在计算顶点 i i i 的度。再看右边括号里面的第二项,这可以认为是邻接矩阵的第 i i i 行对所有顶点的温度组成的向量做了个内积。
为什么要作上述变化呢,我们只看一个点的温度不太好看出来,我们把所有点的温度写成向量形式再描述上述关系就一目了然了。首先可以写成这样:
[ d ϕ 1 d t d ϕ 2 d t ⋯ d ϕ n d t ] = − k [ deg ( 1 ) × ϕ 1 deg ( 2 ) × ϕ 2 ⋯ deg ( n ) × ϕ n ] + k A [ ϕ 1 ϕ 2 ⋯ ϕ n ] \left[\begin{array}{c}\frac{d \phi_{1}}{d t} \\ \frac{d \phi_{2}}{d t} \\ \cdots \\ \frac{d \phi_{n}}{d t}\end{array}\right]=-k\left[\begin{array}{c}\operatorname{deg}(1) \times \phi_{1} \\ \operatorname{deg}(2) \times \phi_{2} \\ \cdots \\ \operatorname{deg}(n) \times \phi_{n}\end{array}\right]+k A\left[\begin{array}{c}\phi_{1} \\ \phi_{2} \\ \cdots \\ \phi_{n}\end{array}\right] ⎣⎢⎢⎡dtdϕ1dtdϕ2⋯dtdϕn⎦⎥⎥⎤=−k⎣⎢⎢⎡deg(1)×ϕ1deg(2)×ϕ2⋯deg(n)×ϕn⎦⎥⎥⎤+kA⎣⎢⎢⎡ϕ1ϕ2⋯ϕn⎦⎥⎥⎤
然后我们定义向量 ϕ = [ ϕ 1 , ϕ 2 , … , ϕ n ] T \boldsymbol{\phi}=\left[\phi_{1}, \phi_{2}, \ldots, \phi_{n}\right]^{T} ϕ=[ϕ1,ϕ2,…,ϕn]T ,那么就有:
d ϕ d t = − k D ϕ + k A ϕ = − k ( D − A ) ϕ \frac{d \phi}{d t}=-k D \phi+k A \phi=-k(D-A) \phi dtdϕ=−kDϕ+kAϕ=−k(D−A)ϕ
其中 D = diag ( deg ( 1 ) , deg ( 2 ) , … , deg ( n ) ) D=\operatorname{diag}(\operatorname{deg}(1), \operatorname{deg}(2), \ldots, \operatorname{deg}(n)) D=diag(deg(1),deg(2),…,deg(n)) 被称为度矩阵,只有对角线上有值,且这个值表示对应的顶点度的大小。整理整理,我们得到:
d ϕ d t + k L ϕ = 0 \frac{d \phi}{d t}+k L \phi=0 dtdϕ+kLϕ=0
回顾刚才在连续欧氏空间的那个微分方程:
∂ ϕ ∂ t − k Δ ϕ = 0 \frac{\partial \phi}{\partial t}-k \Delta \phi=0 ∂t∂ϕ−kΔϕ=0
二者具有一样的形式!我们来对比一下二者之间的关系:
- 相同点:刻画空间温度分布随时间的变化,且这个变化满足一个相同形式的微分方程。
- 不同点:前者刻画拓扑空间有限结点,用向量 ϕ \boldsymbol{\phi} ϕ 来刻画当前状态,单位时间状态的变化正比于线性变换 − L -L −L 算子作用在状态 ϕ \phi ϕ 上。后者刻画欧氏空间的连续分布,用函数 ϕ ( x , t ) \phi(\boldsymbol{x}, t) ϕ(x,t) 来刻画当前状态,单位时间状态变化正比于拉普拉斯算子 Δ \Delta Δ 作用在状态 ϕ \phi ϕ 上。
不难发现,这就是同一种变换、同一种关系在不同空间上面的体现,实质上是一回事!
于是我们自然而然,可以把连续空间中的热传导,推广到图(Graph)上面去,我们把图上面和欧氏空间地位相同变换,以矩阵形式体现的 L L L 叫做拉普拉斯(Laplacian)矩阵。这正是原始形式的拉普拉斯矩阵 L = D − A L=D-A L=D−A
需要多嘴一句的是,本文开头所说的离散链条上的热传导,如果你把链条看成一个图,结点从左到右编号 1,2,3… 的话,也可以用图的热传导方程刻画,此时 D D D 除了头尾两个结点是 1 其他值都是 2(收尾只和一个节点相连), A A A 的主对角线上下两条线上值是 1,其他地方是 0。
2.3 推广到GCN
现在问题已经很明朗了,只要你给定了一个空间,给定了空间中存在一种东西可以在这个空间上流动,两邻点之间流动的强度正比于它们之间的状态差异,那么何止是热量可以在这个空间流动,任何东西都可以!
自然而然,假设在图中各个结点流动的东西不是热量,而是特征(Feature)或者消息(Message),那么问题自然而然就被推广到了 GCN。所以 GCN 的实质是什么,是在一张 Graph Network 中特征(Feature)和消息(Message)中的流动和传播!这个传播最原始的形态就是状态的变化正比于相应空间(这里是Graph空间)拉普拉斯算子作用在当前的状态。
抓住了这个实质,剩下的问题就是怎么去更加好的建模和解决这个问题。
建模方面就衍生出了各种不同的算法,你可以在这个问题上面复杂化这个模型,不一定要遵从牛顿冷却定律,你可以引入核函数、引入神经网络等方法把模型建得更非线性更能刻画复杂关系。解决方面,因为很多问题在频域解决更加好算,你可以通过 Fourier 变换把空域问题转化为频域问题,解完了再变换回来,于是便有了所有 Fourier 变换中的那些故事。
总结一下,问题的本质就是:
- 我们有张图,图上每个结点刻画一个实体,物理学场景下这个实体是某个有温度的单元,它的状态是温度,Graph 中就是一个 embedding 表示的特征向量。
- 相邻的结点具有比不相邻结点更密切的关系。
- 结点可以传播热量/消息到邻居,使得相邻的结点在温度/特征上面更接近。
本质上,这是一种Message Passing,卷积、傅立叶都是表象和解法。
实际解决的过程中,可以发挥机器学习搬砖工懂得举一反三的优良精神,首先,不一定要全局操作,我们可以 batchify 操作一部分结点,大家轮着来,其次,我们可以只考察这个点的一阶和二阶邻居对当前点作 Message Passing,这个思想就是对拉普拉斯算子作特征分解,然后只取低阶的向量,因为矩阵的谱上面能量一般具有长尾效应,头几个特征值 dominate 几乎所有能量。
2.3.1 Laplacian算子的另一个性质
Laplacian 算子的另一个性质:Laplacian 矩阵/算子不仅表现的是一种二阶导数的运算,另一方面,它表现了一种加和性,这个从图上热/消息传播方程最原始的形态就能一目了然:
d ϕ i d t = − k ∑ j A i j ( ϕ i − ϕ j ) \frac{d \phi_{i}}{d t}=-k \sum_{j} A_{i j}\left(\phi_{i}-\phi_{j}\right) dtdϕi=−k∑jAij(ϕi−ϕj)
可见,每个结点每个时刻的状态变化,就是所有邻居对本结点差异的总和,也就是所有的邻居把message pass 过来,然后再 Aggregate 一下,这正是 GraphSage 等空域算法的关键步骤 Aggregate 思想的滥觞。
在实际建模中,我们的 Aggregate 不一定是加和,作为一个熟练的机器学习搬砖工,我们懂得可以把 Aggregate 推广成各种操作例如 Sum Pooling,例如 LSTM,例如 Attention,以求刷效果,发 paper
这里可以再次参考上一篇博客的讲解 Graph Neural Networks (GNN)(一):Spatial - GNN
2.3.2 两种空间下的Fourier分解/ 特征分解对比(卷积为什么能从欧氏空间推广到Graph空间)
最后,因为有以上分析作基础,我们可以解释一下傅立叶变换是怎么推广到图空间的。
首先,在欧氏空间上,迭代求解的核心算子 Δ \Delta Δ 算子的特征函数是: e − j ω t e^{-j \omega t} e−jωt,因为:
Δ e − j ω t = ω 2 e − j w t \Delta e^{-j \omega t}=\omega^{2} e^{-j w t} Δe−jωt=ω2e−jwt
其次,在图空间上,对应地位的 L L L 对应的不是特征函数,而是它的特征值和特征向量,分别对应上面的 ω 2 \omega^{2} ω2 和 e − j w t e^{-j w t} e−jwt。
唯一的区别是, e − j w t e^{-j w t} e−jwt 是定义内积为函数积分的空间上的一组基,有无穷多个,当然这无穷多个是完备的。而 L L L 的特征空间是有限维的,因为 L L L 的对称性和半正定性,所有特征值都是实数且特征向量都是实向量,特征空间维度等于图中的节点数也就是 L L L 的阶。
注意,实对称矩阵的特征空间的所有基能够张出整个线性空间且它们两两正交,所以无论是拉普拉斯算子 Δ \Delta Δ 还是拉普拉斯矩阵 L L L,它们的特征空间是一个满秩且基两两正交的空间,所以把欧氏空间的 e − j ω t e^{-j \omega t} e−jωt 推广到图空间的 L L L 的这一组特征向量。正是同一个关系(Message Passing),同一种变换,在不同空间下的体现罢了!
2.3.3 宇宙热寂说、恒温热源和半监督学习
如果你仔细的思考,你会本文常挂在嘴边的热力学传导模型有个宿命论的结论:假设这个图是个连通图,每个结点到任一其他结点都有路可走,那么这样的事情肯定会发生:如果一个结点温度高于周围邻居,那么它的热量会持续流出到邻居,此间它自己的热量流失,温度就会降低,直到它和周围邻居一样,最终所有结点都达到一个平衡的、一样的温度。
你的猜想非常正确而且能够经过严格的数学证明,只要解上面这个方程(并不难)就能验证你的结论。
问题的本质在于,我们之前所讨论的热传导场景是一个孤立系统的无源场景,每一个结点的热量都有一个初始禀赋,没有外界干预它、给它热量,它每传给周围一些热量,自己就要减少,伴随自身温度的降低。那么根据能量守恒定律,整个系统的能量是定值,并且随着热传导,系统的热量被均匀分配到每个参与其中的结点。这正是热力学第一定律和热力学第二定律在这张图上的完美体现。这也是这张图上的“宇宙热寂说”,这个孤立的小宇宙,最终处处温度一样,平衡状态下没有热量的流动。
如果我们在这张图上引入一个东西叫做恒温热源,事情就会发生改变。所谓恒温热源,就是这样一个存在,系统中有些点开了外挂,它们接着系统外面的某些“供热中心”,使得它们温度能够保持不变。这样,这些结点能够源源不断的去从比它温度高的邻居接受热量,向温度比它低的邻居释放热量,每当有热量的增补和损失,“供热中心”便抽走或者补足多余或者损失的热量,使得这个结点温度不发生变化。
那么最终的平衡的结果不是无源情况下所有结点温度一样,而是整个图中,高温热源不断供热给周围的邻居,热量传向远方,低温热源不断持续吸收邻居和远方的热量,最终状态下每条边热量稳恒流动(不一定为 0 ),流量不再变化,每个结点都达到终态的某个固有温度。这个温度具体是多少,取决于整张图上面恒温热源的温度和它们的分布。
恒温热源的存在,正是我们跨向半监督学习的桥梁。
我们把问题向 Graph 去类比,在这个场景下,某些结点有着明确的 label,这些带着 label 的结点有着相对的确定性——它们可以被看作是这个节点的温度,这些有标签的结点正是恒温热源。那么,这些图的其他参与者,那些等待被我们预测的结点正是这张图的无源部分,它们被动的接受着那些或近或远的恒温热源传递来的 Feature,改变着自己的 Feature,从而影响自己的 label。
让我们做个类比:
- 温度 好比 label 是状态量
- 恒温热源 好比 有明确 label的结点,它们把自己的 Feature 传递给邻居,让邻居的 Feature 与自己趋同从而让邻居有和自己相似的 label。
- 结点的热能就是 Feature,无标签的、被预测的结点的 Feature 被有明确 label 的结点的 Feature 传递并且影响最终改变自己 label。
2.3.4 关于优化过程和优化结果的讨论
从物理和从机器学习角度去看拉普拉斯热传导微分方程注定是不一样的。
- 从物理学角度去研究它,更多的是在搞明白边界条件和初始条件的情况下,探索和了解后续状态的演化过程。
- 而机器学习更多关心的是结果,毕竟我们要的是最终的参数和特征,用来使用和预测结果。然而,关注一些过程方面的东西,能够帮助我们更加深入的建立起原始热传导和前沿的 GNN 算法的联系。
为求简单,我们研究上文所说的原始的无源热传导方程:
d ϕ d t = − k L ϕ \frac{d \phi}{d t}=-k L \phi dtdϕ=−kLϕ
为了好解,我们把时间也离散化,微分变差分近似是这样:
ϕ t + 1 − ϕ t = − k L ϕ t \phi_{t +1}-\phi_{t}=-k L \phi_{t} ϕt+1−ϕt=−kLϕt
ϕ t + 1 = ϕ t − k L ϕ t \phi_{t +1} = \phi_{t}-k L \phi_{t} ϕt+1=ϕt−kLϕt
这实质上是一个机器学习,或者优化问题中常见的样子:
w t + 1 = w t − α ∇ f ( w t ) \boldsymbol{w}_{t+1}=\boldsymbol{w}_{t}-\alpha \nabla f\left(\boldsymbol{w}_{t}\right) wt+1=wt−α∇f(wt)
只是状态的变化量从梯度算子(可能还有动量、历史状态、Hessian 矩阵、正则化操作等等,这里不赘述)作用于 loss function 变成了拉普拉斯算子作用于当前状态。
我们这回先不整体的考察状态向量 ϕ \phi ϕ 的演化,倒退到早些时候所说的每个结点 i i i 的状态 ϕ i \phi_{i} ϕi 的变化,有:
ϕ t + 1 ( i ) = ϕ t ( i ) − k ∑ j A i j ( ϕ t ( i ) − ϕ t ( j ) ) \quad \phi_{t+1}^{(i)}=\phi_{t}^{(i)}-k \sum_{j} A_{i j}\left(\phi_{t}^{(i)}-\phi_{t}^{(j)}\right) ϕt+1(i)=ϕt(i)−k∑jAij(ϕt(i)−ϕt(j))
= ( 1 − k × deg ( i ) ) ϕ t ( i ) − k ∑ j A i j ϕ ( j ) =(1-k \times \operatorname{deg}(i)) \phi^{(i)}_{t}-k \sum_{j} A_{i j} \phi^{(j)} =(1−k×deg(i))ϕt(i)−k∑jAijϕ(j)
= ( 1 − k × deg ( i ) ) ϕ t ( i ) − k ∑ j ∈ N e i g h b o r ( i ) ϕ t ( j ) =(1-k \times \operatorname{deg}(i)) \phi_{t}^{(i)}-k \sum_{j \in N e i g h b o r(i)} \phi^{(j)}_{t} =(1−k×deg(i))ϕt(i)−k∑j∈Neighbor(i)ϕt(j)
到这里已经很明了了,每个结点的下一个状态,是当前状态的常数倍(第一项),和所有邻居的加和(第二项)的融合。
我们来看看 GraphSage 核心算法的过程,会发现原理上二者的惊人相似性:

看最里面的循环节,就是迭代过程,核心两步:
- Aggregate邻居结点的状态,作为邻居结点的一个“和”状态。
- 将这个“和”状态和当前结点的状态通过 Concat 操作和带非线性激活的全连接层融合到一起更新当前结点的状态。
原文中的配图很好的解释了这个过程:
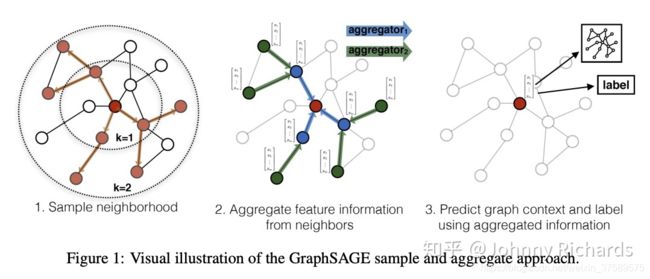
GraphSage 这个过程和原始的热传导过程是这么的相似,我们可以发现:
- 原始的热传导用所有直接相邻的邻居的简单加和作为邻居“和”状态,GraphSage 用一个 Aggregator 作用于所有采样邻居(可以是二阶)得到“和”状态。本质是 Aggregate,只是后者更加非线性,建模能力更强。
- 原始的热传导把邻居“和”状态和当前结点状态简单加权叠加作为融合态,GraphSage 使用 Concat 操作加上神经网络非线性融合一把。本质是把邻居的“和”和本地的现有状态糅合得到本地新状态,依然只是后者更加非线性,建模能力更强。
- 原始热传导使用所有一阶邻居。GraphSage 会采样邻居,因为实际上邻居可能很多全部算很慢,同时它还会采样高阶邻居。本质是主动融合几何上相近的单元。这里可能存在一个隐患,在高度非线性下,对周围邻居的采样的 Aggregate 是不是对周围所有邻居的 Aggregate 的无偏估计,本人知识有限,有待进一步考证。
所有的所有,还是“相邻”、“叠加”与“融合”三个关键词,只是解法更新、迭代、升级了。理解了 Laplacian 变换和图上的热传播的关系,搞明白了 Message Passing 和有源无源状态下的均衡状态,再去看浩如烟海的 paper、知乎回答、博客,相信一定会有更深刻的理解!祝你好运~