Boyer-Moore算法
一.简述
在当前用于查找子字符串的算法中,BM(Boyer-Moore)算法是当前有效且应用比较广的一中算法,各种文本编辑器的“查找”功能(Ctrl+F),大多采用Boyer-Moore算法。比我们在学习的KMP算法快3~5倍。
Boyer-Moore算法不仅效率高,而且构思巧妙,容易理解。1977年,德克萨斯大学的Robert S. Boyer教授和J Strother Moore教授发明了这种算法。
二.算法思想
我们知道常规的字符串匹配算法是从左往右的,这也比较符合我们一贯的思维,但是BM算法是从右往左的。一般匹配我们用的是蛮力匹配,而经典的BM算法其实是对后缀蛮力匹配算法的改进,下面我们给出蛮力后缀匹配的伪代码。
j = 0;
while (j <= strlen(T) - strlen(P)) {
for (i = strlen(P) - 1; i >= 0 && P[i] ==T[i + j]; --i)
if (i < =0)
match;
else
++j;
}从上面的伪代码中我们可以看出每当失匹的时候,就会往后移一位,也就是上面++j这一行代码;而BM算法所做的就是改进这一行代码,即模式串不在每次只移动一步,而是根据已经匹配的后缀信息,来判断移动的距离,通常80%左右能够移动模式串的长度,从而可以跳过大量不必须比较的字符,大大提高了查找效率。
为了实现更快的移动模式串,BM定义了两个规则,坏后缀规则和好后缀规则。这两个规则分别计算我们能够向后移动模式串长度,然后选取这两个规则中移动大的,作为我们真正移动的距离。也就是上述伪代码中j不在每次加一,而是加上上面两个规则中移动长度大的。
假定字符串为”HERE IS A SIMPLE EXAMPLE”,模式串为”EXAMPLE”。下面我将阐述几个概念,坏字符和好后缀。

上图中我们看到,”S”与”E”不匹配。这时,“S”就被称为”坏字符”(bad character),即不匹配的字符。

上图中 ”MPLE”与”MPLE”匹配。我们把这种情况称为”好后缀”(good suffix),即所有尾部匹配的字符串。注意,”MPLE”、”PLE”、”LE”、”E”都是好后缀,这点后面我们会用到。
坏字符算法
当出现一个坏字符时, BM算法向右移动模式串, 让模式串中最靠右的对应字符与坏字符相对,然后继续匹配。坏字符算法有两种情况。
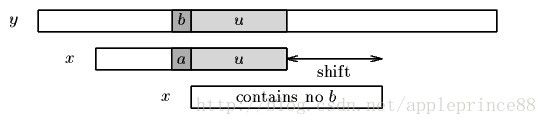
- 模式串中有对应的坏字符时,y为字符串,x为模式串,见下图

坏字符出现在模式串中,这时可以把模式串第一个出现的坏字符和母串的坏字符对齐,也就是上面所说的最靠右。当然,这样可能造成模式串倒退移动,因为坏字符可能出现在与模式串失匹位置的右面,不过由于我们移动不光看坏后缀还看好后缀,所以不会后退。
- 模式串中不存在坏字符,这时可以把模式串移动到坏字符的下一个字符,继续比较。如下图所示
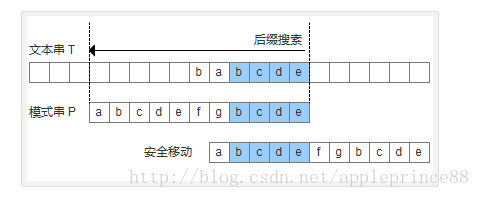
好后缀算法
好后缀算法分为三种情况
- 模式串中有子串匹配上好后缀,此时移动模式串,让该子串和好后缀对齐即可,如果超过一个子串匹配上好后缀,则选择最靠右边的子串对齐,防止有漏匹配的。
- 模式串中没有子串匹配上后后缀,此时需要寻找模式串的一个最长前缀,并让该前缀等于好后缀的后缀,寻找到该前缀后,让该前缀和好后缀对齐即可。

- 模式串中没有子串匹配上后后缀,并且在模式串中找不到最长前缀,让该前缀等于好后缀的后缀。此时,直接移动模式到好后缀的下一个字符。

BM算法的大体思想到这里我们基本介绍结束了,下面我们通过一个例子来具体感受一下
三.例子
下面,我根据Moore教授自己的例子来解释这种算法。希望通过例子大家能有一个感性的认识。
1.

假定字符串为”HERE IS ASIMPLE EXAMPLE”,搜索词为”EXAMPLE”。搜索词我们下面都称为模式串。
2.

首先,”字符串”与”模式串”头部对齐,从尾部开始比较。
我们看到,”S”与”E”不匹配。这时,“S”就被称为”坏字符”(badcharacter),即不匹配的字符。我们还发现,”S”不包含在模式串”EXAMPLE”之中,这意味着可以把模式串直接移到”S”的后一位。这里适用坏规则。
3.

依然从尾部开始比较,发现”P”与”E”不匹配,所以”P”是”坏字符”。但是,”P”包含在模式串”EXAMPLE”之中。所以,根据坏规则将模式串中的最右的“P”与字符串中的”P”对齐,模式串后移两位。
4.

我们由此总结出“坏字符规则”:
后移位数 = 坏字符的位置 – 搜索词中的上一次出现位置
如果”坏字符”不包含在搜索词之中,则上一次出现位置为 -1。
以”P”为例,它作为”坏字符”,出现在搜索词的第6位(从0开始编号),在搜索词中的上一次出现位置为4,所以后移 6 – 4 = 2位。再以前面第二步的”S”为例,它出现在第6位,上一次出现位置是 -1(即未出现),则整个搜索词后移 6 – (-1) = 7位。
5.

E和E匹配,继续匹配

比较前一位,LE和LE匹配

比较前一位,PLE与PLE匹配

比较前面一位,”MPLE”与”MPLE”匹配。我们把这种情况称为”好后缀”(good suffix),即所有尾部匹配的字符串。注意,”MPLE”、”PLE”、”LE”、”E”都是好后缀。
6.

比较前一位,发现”I”与”A”不匹配。所以,”I”是”坏字符”。根据”坏字符规则”,此时模式串应该后移 2 –(-1)= 3 位。问题是,此时有没有更好的移法?
我们知道,此时存在”好后缀”。所以,可以采用“好后缀规则”:
后移位数 = 好后缀的位置 – 模式串中的上一次出现位置
计算时,位置的取值以”好后缀”的最后一个字符为准。如果”好后缀”在模式串中没有重复出现,则它的上一次出现位置为 -1。
所有的”好后缀”(MPLE、PLE、LE、E)之中,只有”E”在”EXAMPLE”之中出现两次,所以后移 6 – 0 = 6位。取坏规则和好规则的最大的那个值,也就是我们要后移6位。后移后如下图所示。

7.

继续从尾部开始比较,”P”与”E”不匹配,因此”P”是”坏字符”。根据”坏字符规则”,后移 6 – 4 = 2位。
8.

从尾部开始逐位比较,发现全部匹配,于是搜索结束。如果还要继续查找(即找出全部匹配),则根据”好后缀规则”,后移 6 – 0 = 6位,即头部的”E”移到尾部的”E”的位置。
更多的例子,点这里。
四.算法详解
通过了一个例子后,相信大家对这个算法基本了解了,那么下面我们将通过具体实现来深入解释算法的一些细节。具体实现与上面那个例子稍微有点不一样,但原理是一样的。
首先我们要设计一个数组bmBc[],比如说bmBc[‘K’]表示坏字符‘k’在模式串中最右出现的位置距离模式串末尾的长度,那么当遇到坏字符的时候,模式串可以移动距离为: shift(坏字符) = bmBc[T[i]]-(m-1-i) (其中T[i]指的是在i位置上坏字符,(m-1-i)指的是坏字符位置到模式串末尾的长度),这个移动的距离与我们上面例子讨论的移动距离的方式虽然不一样,但原理是一样的,都是求坏字符位置与在模式串出现坏字符位置的距离,当然这个距离有可能是负的,但是没关系,遇到这种情况模式串就直接向后一位,重新开始匹配,但是由于有好后缀规则,我们选取大的进行移动,所以也可以不处理。如下图:

数组bmBc的创建非常简单,直接贴出伪代码代码如下:
void preBmBc(char *x, int m, int bmBc[]) {
int i;
for (i = 0; i 上面ASIZE为该字符集词的个数,但是上述伪代码存在一个问题如果是像中文这样字符集的话会是bmBc数组非常大,所以我实现采用了如下的方法,就是通过键值对来取代数组,然后用一个专门的函数来查看键值对的值,如果存在就返回相应的值,不存在就返回模式串的长度。具体看代码
private void preBmBc(String pattern,int patLength,Map bmBc)
{
System.out.println("bmbc start process...");
for(int i=patLength-2;i>=0;i--)
{
if(!bmBc.containsKey(String.valueOf(pattern.charAt(i))))
{ bmBc.put(String.valueOf(pattern.charAt(i)),(Integer)(patLength-i-1));
}
}
}
private int getBmBc(String c,Map bmBc,int m)
{
//如果在规则中则返回相应的值,否则返回pattern的长度
if(bmBc.containsKey(c))
{
return bmBc.get(c);
}else
{
return m;
}
}
为了实现好后缀规则,需要定义一个数组suffix[],其中suffix[i] = s 表示以i为边界,与模式串后缀匹配的最大长度,如下图所示,用公式可以描述:满足P[i-s, i] == P[m-s, m]的最大长度s。

构建suffix数组的伪代码如下:
suffix[m-1]=m;
for (i=m-2;i>=0;--i){
q=i;
while(q>=0&&P[q]==P[m-1-i+q])
--q;
suffix[i]=i-q;
}
有了suffix数组,就可以定义bmGs[]数组,bmGs[i] 表示遇到好后缀时,模式串应该移动的距离,其中i表示好后缀前面一个字符的位置(也就是坏字符的位置),构建bmGs数组分为三种情况,分别对应上述的移动模式串的三种情况
模式串中没有子串匹配上好后缀,但找不到一个最大前缀

模式串中有子串匹配上好后缀
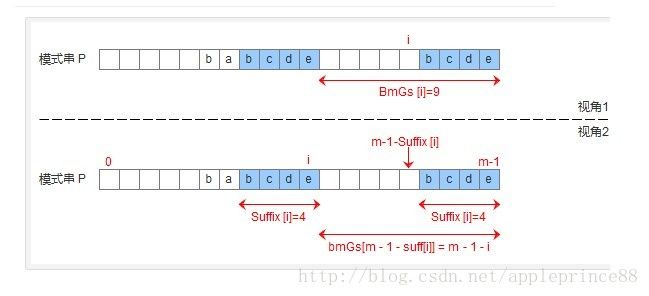
模式串中没有子串匹配上好后缀,但找到一个最大前缀

构建bmGs数组的伪代码如下:
void preBmGs(char *x, int m, int bmGs[]) {
int i, j, suff[XSIZE];
suffixes(x, m, suff);
//模式串中没有子串匹配上好后缀,也找不到一个最大前缀
for (i = 0; i < m; ++i)
bmGs[i] = m;
j = 0;
//模式串中没有子串匹配上好后缀,但找到一个最大前缀
for (i = m - 1; i >= 0; --i)
if (suff[i] == i + 1)
for (; j < m - 1 - i; ++j)
if (bmGs[j] == m)
bmGs[j] = m - 1 - i;
//模式串中有子串匹配上好后缀
for (i = 0; i <= m - 2; ++i)
bmGs[m - 1 - suff[i]] = m - 1 - i;
}
在计算完bmBc,BmGs数组后,BM算法伪代码实现如下:
j = 0;
while (j <= strlen(T) - strlen(P)) {
for (i = strlen(P) - 1; i >= 0 && P[i] ==T[i + j]; --i)
if (i < 0)
match;
else
j += max(bmGs[i], bmBc[T[i]]-(m-1-i));
}
BM算法一般情况下的算法复杂度为O(M/N),M为字符串长度,N为模式串长度。对于算法复杂度感兴趣的,点这里
参考文献:
- Computer Algorithms: Boyer-Moore String Searching
- 字符串匹配那些事(一)
- 字符串匹配的Boyer-Moore算法
- A Fast String Searching Algorithm
JAVA实现源码
import java.util.*;
public class BoyerMoore {
public static void main(String[] args) {
// TODO Auto-generated method stub
// String text="HERE IS A SIMPLE EXAMPLE";
// String pattern="EXAMPLE";
// String pattern="GCAGAGAG";
// String text="WOWOWO!";
// String pattern="WOWO";
String text="中国是一个伟大的国度;伟大的祖国啊";
String pattern="伟大的国度";
BoyerMoore bm=new BoyerMoore();
bm.boyerMoore(pattern, text);
}
private void preBmBc(String pattern,int patLength,Map bmBc)
{
System.out.println("bmbc start process...");
for(int i=patLength-2;i>=0;i--)
{
if(!bmBc.containsKey(String.valueOf(pattern.charAt(i))))
{
bmBc.put(String.valueOf(pattern.charAt(i)),(Integer)(patLength-i-1));
}
}
}
private void suffix(String pattern,int patLength,int [] suffix)
{
suffix[patLength-1]=patLength;
int q=0;
for(int i=patLength-2;i>=0;i--)
{
q=i;
while(q>=0&&pattern.charAt(q)==pattern.charAt(patLength-1-i+q))
{
q--;
}
suffix[i]=i-q;
}
}
private void preBmGs(String pattern,int patLength,int []bmGs)
{
int i,j;
int []suffix=new int[patLength];
suffix(pattern,patLength,suffix);
//模式串中没有子串匹配上好后缀,也找不到一个最大前缀
for(i=0;i=0;i--)
{
if(suffix[i]==i+1)
{
for(;j bmBc,int m)
{
//如果在规则中则返回相应的值,否则返回pattern的长度
if(bmBc.containsKey(c))
{
return bmBc.get(c);
}else
{
return m;
}
}
public void boyerMoore(String pattern,String text )
{
int m=pattern.length();
int n=text.length();
Map bmBc=new HashMap();
int[] bmGs=new int[m];
//proprocessing
preBmBc(pattern,m,bmBc);
preBmGs(pattern,m,bmGs);
//searching
int j=0;
int i=0;
int count=0;
while(j<=n-m)
{
for(i=m-1;i>=0&&pattern.charAt(i)==text.charAt(i+j);i--)
{ //用于计数
count++;
}
if(i<0){
System.out.println("one position is:"+j);
j+=bmGs[0];
}else{
j+=Math.max(bmGs[i],getBmBc(String.valueOf(text.charAt(i+j)),bmBc,m)-m+1+i);
}
}
System.out.println("count:"+count);
}
}