【知识图谱】Neo4j 导入数据构建知识图谱的三种方法
目录
Neo4j数据导入5种方式
1、使用Cypher语言创建
1.1 创建节点【create】
1.2 修改节点的属性
1.3 创建带属性值的节点
1.4 创建节点间的关系
1.5 其他操作命令
1.6 cypher查询语言的使用规律
2、使用load csv导入数据
2.1 构建容器(非必须)
2.2 导入节点csv文件
2.3 创建索引并删除重复节点
2.4 导入关系csv文件
3、使用neo4j-admin导入数据
3.1 数据导入前的准备工作
3.2 数据预处理
3.3 数据导入
3.4 查看知识图谱
4、总结
Neo4j数据导入5种方式
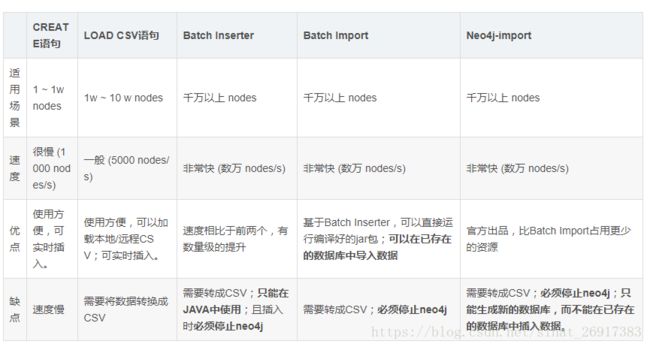
neo4j的数据导入方式有很多,总结起来总共分为以下5种:
- Cypher CREATE 语句,为每一条数据写一个CREATE
- Cypher LOAD CSV 语句,将数据转成CSV格式,通过LOAD CSV读取数据。
- 官方提供的Java API —— Batch Inserter
- 大牛编写的 Batch Import 工具
- 官方提供的 neo4j-import 工具
物种方式的优缺点对比:
1、使用Cypher语言创建
1.1 创建节点【create】
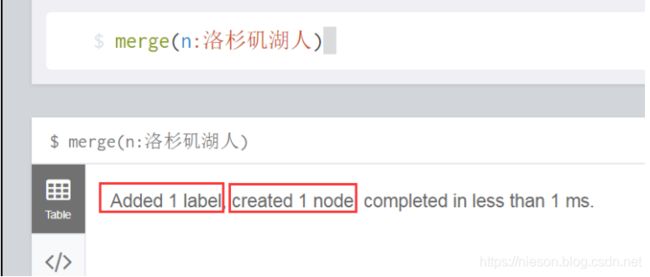
第一种方式: merge(n:洛杉矶湖人) # 节点不存在,则创建,存在,则忽略。
第二种方式: create(n:洛杉矶湖人) # 不管节点存不存在,创建
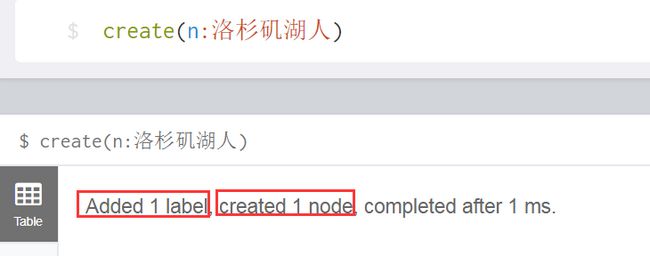
效果就是,洛杉矶湖人这类的节点,一共被创建了两次,因此,查询的时候,会出现两个Node。虽然上面我们创建了两个节点,但是这两个节点除了系统给的唯一id外,没有其他属性,下面我就基于这两个节点,分别对它们进行“update”,赋予节点意义。
1.2 修改节点的属性
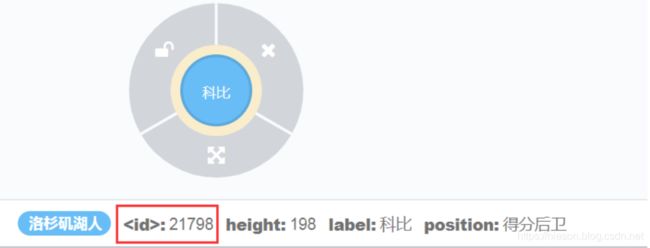
首先:查询ID等于21798的Node
match(n) where ID(n) = 21798 return n
# 别忘了查询节点,最后要return n返回节点.其次:给该Node添加三个属性,分别是label(节点标签名),height(身高),position(场上位置)
neo4j查询节点用:match == 相当于关系型数据库的select,相当于非关系数据库mongodb的find
neo4j修改节点属性用:set == 相当于关系型数据库的update...set...
match(n) where ID(n) = 21798 set n.label='科比',n.height=198,n.position='得分后卫' return n类似sql语句: update n set label = ‘科比’,height=198,position='得分后卫' where id = 21798
区别:关系型数据库如果字段不存在的话会报错,而NoSql数据库neo4j,如果属性字段不存在的话,就添加
执行后,效果如下:
1.3 创建带属性值的节点
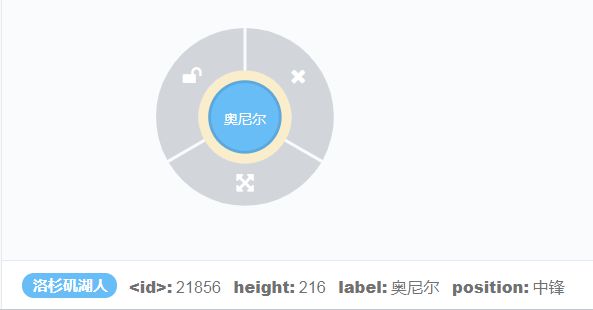
我们使用create创建另一位湖人传奇巨星奥尼尔这个节点,语句如下:
create(n:洛杉矶湖人{label:'奥尼尔',height:216,position:'中锋'}) return n效果如下:
1.4 创建节点间的关系
构成一条关系最基本的要素是要有两个对象,放在neo4j图库中就是,两个节点,一条边,才能称作是一个完整的关系。创建统一用create命令,而关系的创建,实际上和创建节点差不多,唯一区别就是,关系是有方向的,而且关系用‘[]’表示,而节点用'()'表示。
下面我给目前尚存在的两个节点,科比和奥尼尔创建一条关系,关系的name叫“搭档”,这种关系,不区分方向,因此,无所谓谁是startNode,谁是endNode。
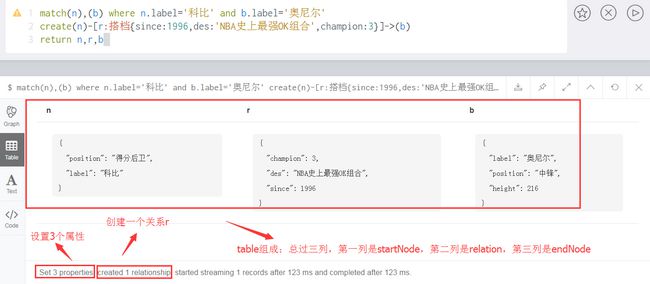
match(n),(b) where n.label='科比' and b.label='奥尼尔'
create(n)-[r:搭档{since:1996,des:'NBA史上最强OK组合',champion:3}]->(b)
return n,r,b解释一下:
1、首先匹配找到节点n和b,也就是科比和奥尼尔代表的节点Node;
2、然后创建节点n到节点b的关系r,r有三个属性,一个是从哪一年开始since,一个是关系描述des,另一个是合作拿过的冠军数量champion;
3、最后返回n,r,b 完整节点之间的关系结果,table数据如下,总过三列:
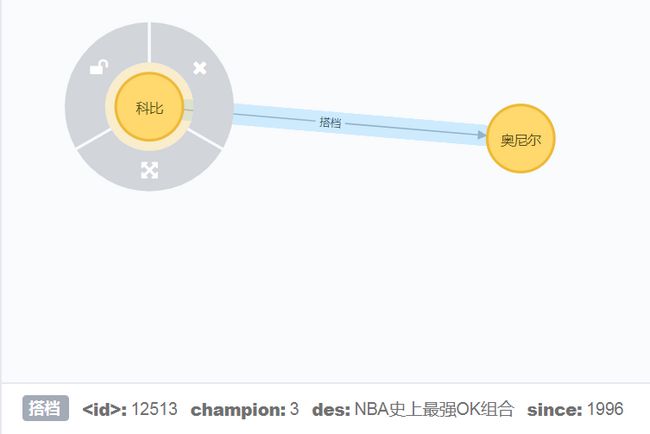
最终,创建的graph图效果如下:
1.5 其他操作命令
如果要修改关系的属性,和修改节点的属性一样,修改关系的属性也用set,如修改id等于12513的关系的属性des为“小飞侠&大鲨鱼”的语句如下:
match(n)-[r]-(b) where ID(r) = 12513 set r.des='小飞侠&大鲨鱼' return n,r,b如果要删除节点间的关系,删除统一用命令delete,和删除节点一样,删除关系的语句如下:
match(n)-[r]-(b) where n.label='科比' and b.label='奥尼尔' delete r return r如果要查询科比和奥尼尔之间的关系,则语句如下:
match(n)-[r]-(b) where n.label='科比' and b.label='奥尼尔' return n,r,b如果要创建索引,语法:
CREATE INDEX ON : () 为节点标签洛杉矶湖人基于属性label创建索引,语句如下:
create index on:洛杉矶湖人(label)删除索引:
DROP INDEX ON : () drop index on:洛杉矶湖人(label)1.6 cypher查询语言的使用规律
其实使用cypher语言来查询还是非常简单的,因为不管你查什么,查的无外乎节点、关系、节点间的关系,用表达式表示就是:(n)-[r]-(b),掌握以下规律,你就可以快速掌握如何使用Cypher语言。
结合表达式: match(n)-[r] -(b)
如果查询节点n 就 return n
如果查询关系r 就 return r
如果查询节点b 就 return b
如果查询节点n和b之间的关系r 就 return n,r,b
如果查询带条件 就 where n.x = x,r.xx = xx,b.xxx = xxx
如果修改属性 就 where..... set ....
如果删除属性 就 where..... remove .....
如果删除节点或关系 就 where..... delete n 或者 delete r 或者 delete b 或者 delete n , r , b
2、使用load csv导入数据
2.1 构建容器(非必须)
docker环境下安装:这里说明下,默认将容器的/data,/var/lib/neo4j/import目录映射到宿主机。/data存储的是数据,/var/lib/neo4j/import存储的是你想要导入数据的
docker run \
--publish=7474:7474 --publish=7687:7687 \
--volume=/data/neo4j/data:/data \
--volume=/data/neo4j/import:/var/lib/neo4j/import \
--env=NEO4J_dbms_memory_pagecache_size=2G \
--env=NEO4J_dbms_memory_heap_max__size=8G \
--name=neo4j \
-d neo4j 初次进行大批量数据的导入有很多方式,但是每种方式都会有自己的局限性。这里是官网文档。
2.2 导入节点csv文件
通过cypher-shell命令行直接导入数据。这样的方式,可以不停用neo4j服务,直接导入到库中。
#load node csv
USING PERIODIC COMMIT 1000
LOAD CSV WITH HEADERS FROM "file:/nodes.csv" AS csvLine
CREATE (c:Contact { mobile:csvLine.mobile, name:csvLine.name, updateTime:csvLine.updateTime, createTime:csvLine.createTime });USING PERIODIC COMMIT 1000,是满足1000条之后,提交一个事务,这样能够提高效率。
2.3 创建索引并删除重复节点
导入节点之后,我们必然会导入关系。这里就有个坑,如果你在node节点的库里,没有创建index,那么导入关系的时候,将会慢的要死。
# 创建索引之前,我们插入的节点数据有可能会有重复的情况,我们需要先清除一下重复数据。
MATCH (n:Contact)
WITH n.mobile AS mobile, collect(n) AS nodes
WHERE size(nodes) > 1
FOREACH (n in tail(nodes) | DETACH DELETE n);#创建索引
CREATE CONSTRAINT ON (c:Contact) ASSERT c.mobile IS UNIQUE;
CREATE INDEX ON :Contact(mobile);2.4 导入关系csv文件
USING PERIODIC COMMIT 1000
LOAD CSV WITH HEADERS FROM "file:/rels.csv" AS csvLine
MATCH (c:Contact {mobile:csvLine.mobile1}),(c1:Contact {mobile:csvLine.mobile2})
CREATE (c)-[:hasContact]->(c1);3、使用neo4j-admin导入数据
通过neo4j-admin方式导入的话,需要暂停服务,并且需要清除graph.db,这样才能导入进去数据。而且,只能在初始化数据时,导入一次之后,就不能再次导入了。所以这种方式,可以在初次建库的时候,导入大批量数据,等以后如果还需要导入数据时,可以采用上边的方法。
3.1 数据导入前的准备工作
对于大规模的数据集,使用语句插入和load csv的时候往往非常缓慢,当需要插入大量三元组时,可以考虑使用Neo4j-import的方式。这种方式有许多注意点:
# 三元组数据导入前的准备工作
1、传入文件名的时候务必使用绝对路径。
2、在执行指令之前务必保证Neo4j处于关闭状态,如果不确定可以在Neo4j根目录下运行./bin/neo4j status 查看当前状态。
3、使用neo4j-admin import指令导入之前先将原数据库从neo4j_home/data/databases/graph.db/中移除。
4、写CSV文件的时候务必确保所有的节点的CSV文件的ID fileds的值都唯一、不重复。并且确保所有的边的CSV文件的START_ID 和 END_ID都包含在节点CSV文件中。3.2 数据预处理
neo4j-import官方要求的数据格式为csv文件,主要就是分成两个文件entity.csv 和relationship.csv。
其中entity.csv中包含了实体的id,实体的name,以及标签LABEL,具体格式如下:
entity:ID,name,:LABEL
e0,GDP,my_entity
e1,PHP,my_entity
e2,李冲,my_entity
e3,perimenopausal syndrome,my_entity
e4,雁荡山景区分散,东起羊角洞,西至锯板岭;南起筋竹溪,北至六坪山。,my_entity
e5,词条(拼音:cí tiáo)也叫词目,是辞书学用语,指收列的词语及其释文。,my_entity
e6,芦苇茂密,结草为荡,my_entity
e7,面粉,水,酵母,苏打,my_entity
e8,先注册先得的原则,my_entity
e9,解压缩软件,my_entity
e10,华硕电脑股份有限公司,my_entityrelationship.csv文件包含了起始节点id,结束节点id,关系的name,以及标签LABEL,具体格式如下:
:START_ID,:END_ID,name,:TYPE
e48,e799,属性,属性
e191,e479,描述,描述
e641,e5,描述,描述
e641,e182,标签,标签
e237,e575,描述,描述
e237,e237,中文名,中文名
e237,e533,是否含防腐剂,是否含防腐剂
e237,e264,主要食用功效,主要食用功效
e237,e405,适宜人群,适宜人群需要将导入的数据转换成这样的两个格式的csv文件,才能够导入Neo4j中。
3.3 数据导入
csv数据文件准备好后,可以通过执行以下脚本来实现数据导入:
#导入命令
# 停止neo4j服务
neo4j stop
# 如果是Linux可以进入到databases目录下删除数据库,windows直接删除即可
cd /usr/local/Cellar/neo4j/3.5.0/libexec/data/databases
rm -rf graph.db
# 执行数据导入命令neo4j-admin
neo4j-admin import \
--database=graph.db
--nodes:phone="../phone_header.csv,phones.csv \
--ignore-duplicate-nodes=true \
--ignore-missing-nodes=true \
--relationships:call="../call_header.csv,call.csv"
# 重启neo4j服务
neo4j start出现类似于如下结果,表示导入成功:
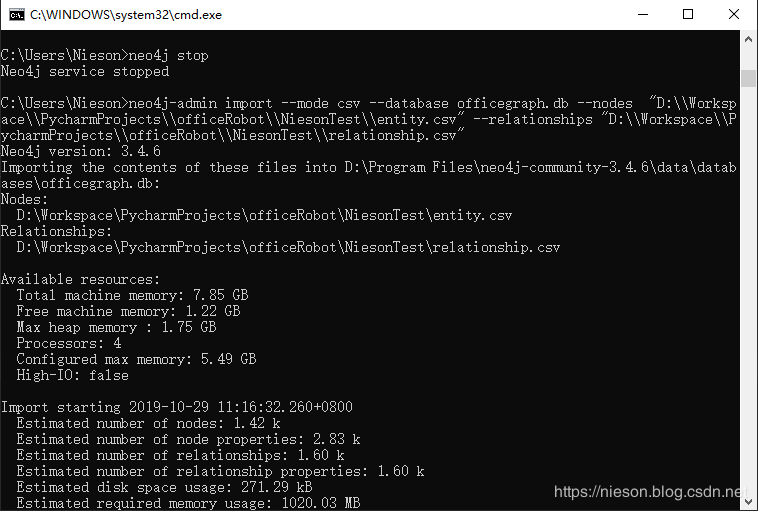
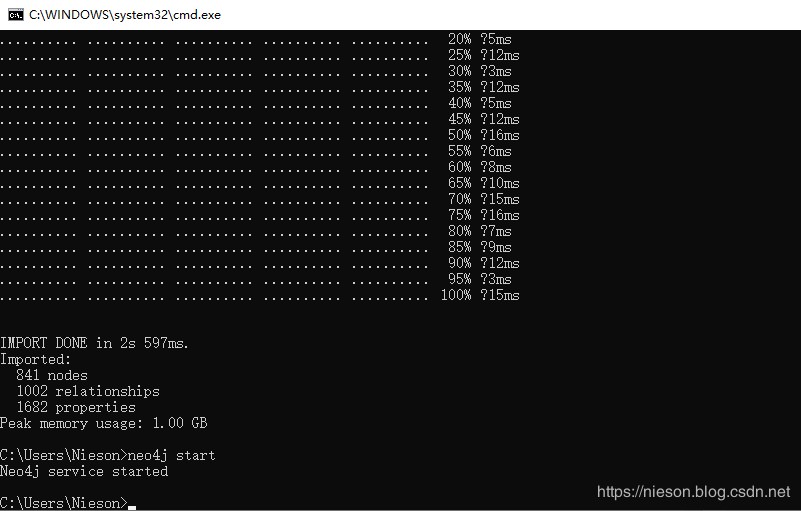
结果显示导入了841个节点(因为1000原数据中的节点有重复的),1002个关系(实际数据条数为1002),1682个属性值。
3.4 查看知识图谱
查看结果:导入完成之后,我们可以打开neo4j浏览器查看一下导入后的结果,打开http://localhost:7474/browser/
知识图谱生成后,重启Neo4j服务:
neo4j start查看整个知识图谱,使用查询命令:
match(n) return n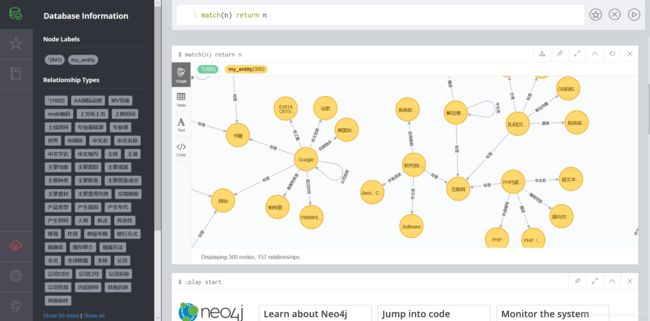
查询实体节点为Google的所有对应的关系:
match(n:my_entity)-[r]->(b) where n.name='Google' return n,r,b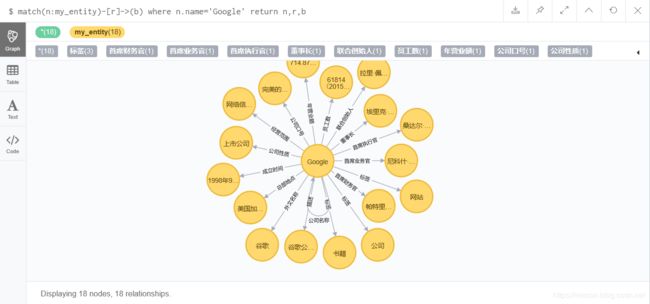
至此,neo4j-import导入大量数据就成功了。
4、总结
以上介绍了create、load csv、neo4j-admin三种主要的数据导入方式,Batch Inserter和 Batch Import相对用的不多,Batch Inserter是需要在Java中使用,Batch Import可以参考该链接,本文介绍的三种方式基本满足了各种数量级别的数据导入构建知识图谱的要求,总有一款适合你!