【论文阅读笔记】Instance Segmentation of Visible and Occluded Regions for Finding and Picking Target(写不开了,,)
Instance Segmentation of Visible and Occluded Regions for Finding and Picking Target from a Pile of Objects
- (一)论文地址:
- (二)核心思想:
- (三)实例遮挡分割神经网络:
-
- 3.1 Mask R-CNN:
- 3.2 Relook 结构:
-
- 3.2.1 Parallel for ROIs:
- 3.2.2 Connections for ROIs:
- (四)训练细节:
- (五)数据生成:
- (六)实例分割的新度量:
- (七)实验结果:
i n s t a n c e instance instance o c c l u s i o n occlusion occlusion s e g m e n t a t i o n segmentation segmentation
(一)论文地址:
https://arxiv.org/abs/2001.07475
(二)核心思想:
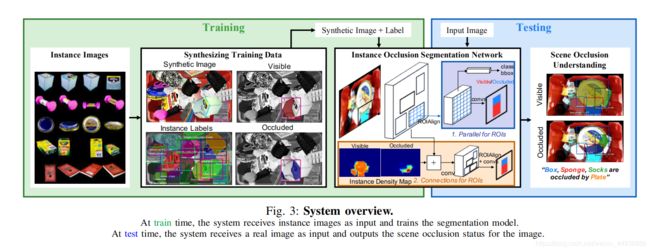
作者在原有的 Mask R-CNN 的基础上,添加了一个 r e l o o k relook relook 结构,并通过三维点云数据合成图像,使得网络能够在无需人工标注数据的情况下,对物体进行实例分割并识别物体之间的关系(指的是 visible 和 occluded 两种状态)并预测被遮挡部分,从而使得机械臂能够准确地判断抓取物体的顺序;
并且作者还在真实的机器人系统上测试了模型抓取目标物体的性能:

论文的主要贡献有:
- 提出了一个用于学习包含遮挡的实例分割的图像生成框架;
- 设计了一个新的网络结构,用于预测物体的遮挡情况;
- 提出了一个实例分割的新度量;
- 设计了上述组件的集成系统和在捡堆任务中的演示;
(三)实例遮挡分割神经网络:
3.1 Mask R-CNN:
Mask R-CNN 是 Faster-RCNN 的一个延伸,通过 ROI Align 对每个 ROI 进行分割:
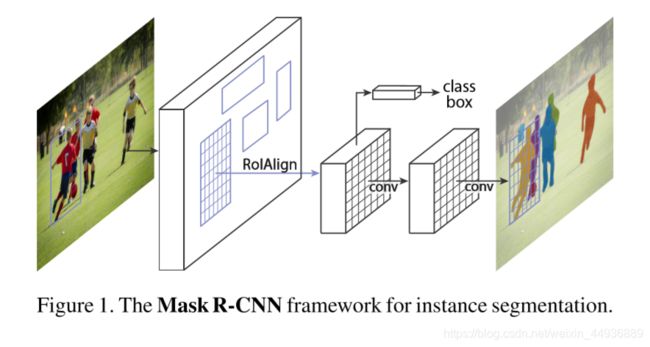
虽然 Mask R-CNN 在实例分割上取得了比较好的效果,但是它并不能识别物体间的关系;
3.2 Relook 结构:
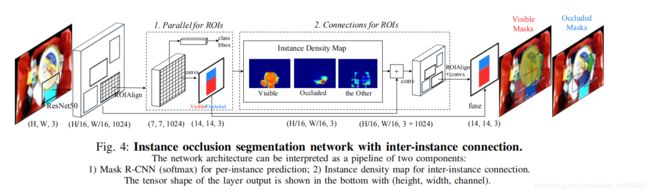
为了使得网络能够区分物体遮掩情况,作者设计了 Relook 结构(感觉后面那部分有点多余啊,,,可能不加上就完全是 Mask RCNN 了);
3.2.1 Parallel for ROIs:

这一部分跟 Mask RCNN 的结构基本相同,唯一不同的一点就是,原本 Mask RCNN 是对 7×7×1024 大小的经过 ROI Align 的特征图进行反卷积操作,得到 14×14×28(28 是类别数)每点的类别概率;
这里将 28 个类别替换成 3,表示物体遮掩的三种状态的概率(Visible,Occluded 和 the Other),再 resize 到原来的 ROI 大小,得到 ( H / 16 , W / 16 , 3 ) (H/16,W/16,3) (H/16,W/16,3) 大小的遮掩状态概率特征图;
(感觉稍微有点问题,对于重叠的 ROI 区域,无法区分两个区域代表不同物体的遮掩状态,改成 28 × 3 会不会好一点?)
3.2.2 Connections for ROIs:
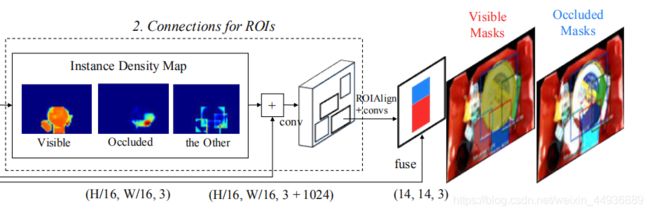
这里通过 resize 操作将每个 ROI 得到的 (14,14,3) 的概率图映射回原特征图大小,得到 ( H / 16 , W / 16 , 3 ) (H/16,W/16,3) (H/16,W/16,3) 大小的概率图,再作为新的特征图与最初的特征图 stack(不知为何图上画的是+号,,,),得到大小为 (14,14,3+1024) 新的特征图;
再做一次 ROI Align+Convs 操作,得到对 ROI(注意 ROI 还是原来的没有变)双线性插值得到的新的特征图的遮掩状态概率图 (14,14,3),将这个概率图再与第一次得到的概率图(也是同样大小)求和,最后 resize 到原来的 ROI 大小,再通过 FCN 的反卷积结构映射到原图大小上,就得到了最后的输出;
(四)训练细节:
使用了 600 输入边最小长度,512 作为 RPN 网络的隐藏层数,使用了 512 个建议区域(proposals),其中前景和背景比率为 1:4;
(五)数据生成:
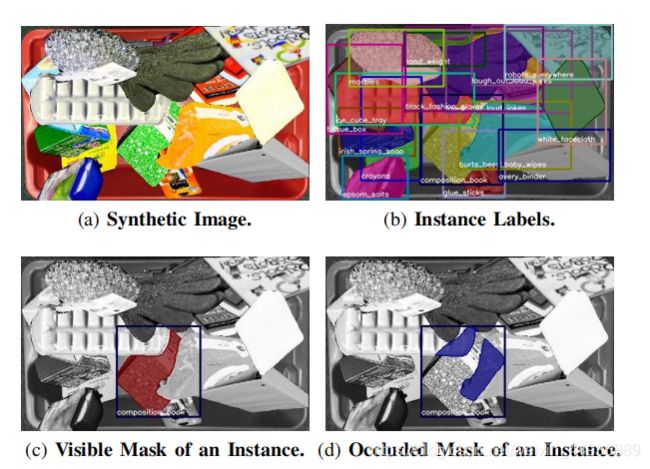
作者使用了 Amazon Robotics Challenge 提供的 3D 数据作为数据集,通过堆叠物体来生成特定的 2D 图像作为训练集;
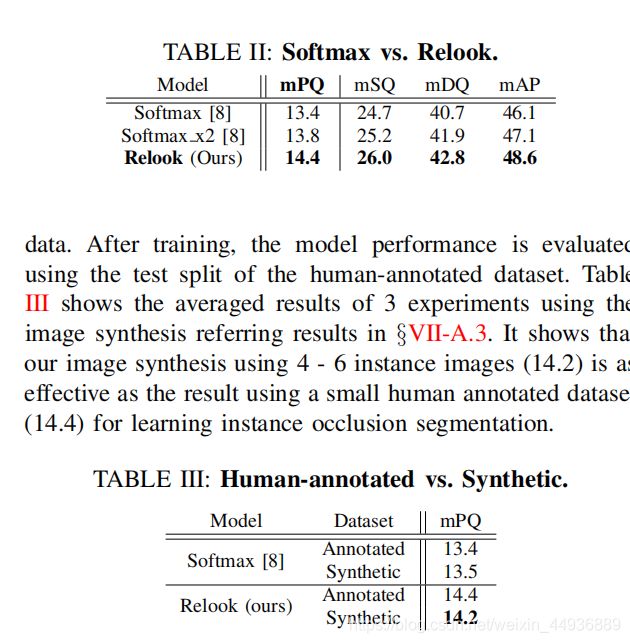
(六)实例分割的新度量:
之前没有考虑遮掩状态的实例分割度量为:
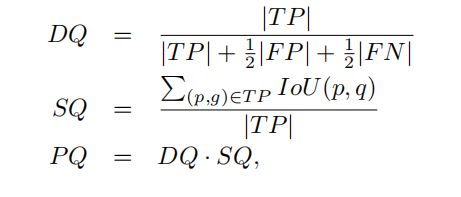
其中 TP 代表正确分类的正样本, FP 代表错误分类的正样本,FN 代表错误分类的负样本,p 是预测的物体框,g 是真值框;
作者在这里提出了新度量 SQ:

M 代表遮掩状态;
(七)实验结果: