模型优化、正则化、损失函数
一、前言
对于理解机器学习或者深度学习的人来说,需要了解基本的学习框架是什么?无论是聚类、回归,对于参数的求解以及参数的正则化(防止过拟合的措施)来源于什么原理或者基于什么?,这是需要我们理解的。一般而言从误差出发,有式子:
Loss_function=Est_error+Regularization of parameters
下面我们来说说估计误差中的损失函数以及模型优化的手段。
二、常见的损失函数以及应用


三、train_data、validation_data、test_data之间的联系与区别
对应某个问题,我们获得样本集合data={(x(i),y(i)),i=1…n},备选的模型有很多,分类问题就可以使用决策树、LR、RF、gbdt等,先假设有备选模型的集合为{M1,M2…Mk}.现在问题是选择哪个模型?该模型对应的参数是多少?模型效果怎样?
一般地,data分为两个部分(7:3),一部分作为模型的训练,通常叫做train_data;另外一部分作为模型的测试,通常叫做 test_data。
但是对于多个模型比较或者某个模型它本身具有超参数,此时就需要validation_data,也叫做验证数据,比如神经网络模型,超参数就是隐层层数与隐层节点数。其实就是将原来的 train_test分成了两个部分,训练集合new_train_test(为了区分)以及validation_data。有时候因为前人的多次实践,我们已经知道了最优的超参数,此时就不需要 validation_data来验证,这就是我们常见的只有train_data,test_data。
一般的过程为:


四、模型过拟合与欠拟合
1.过拟合与欠拟合
假设需要拟合下面的点,得到两个拟合结果:

左图欠拟合,高偏差,是指模型未训练出数据集的特征,导致模型在训练集、测试集上的精度都很低。
右图过拟合,高方差(high variance),是指模型训练出包含噪点在内的所有特征,导致模型在训练集的精度很高,但是应用到新数据集时,精度很低。
2.如何判断过拟合与欠拟合------绘制损失函数随数据集增加的学习曲线

3.模型欠拟合与过拟合的优化方法
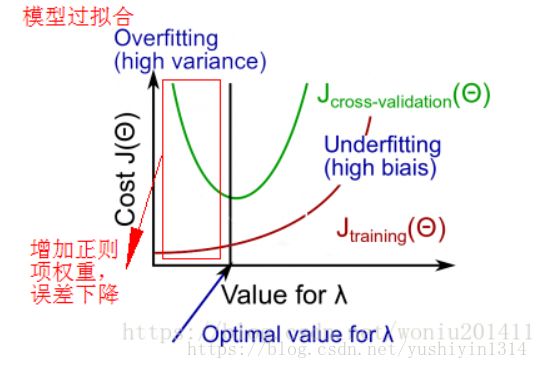
欠拟合:增加特征、提升模型复杂度、减少正则项权重
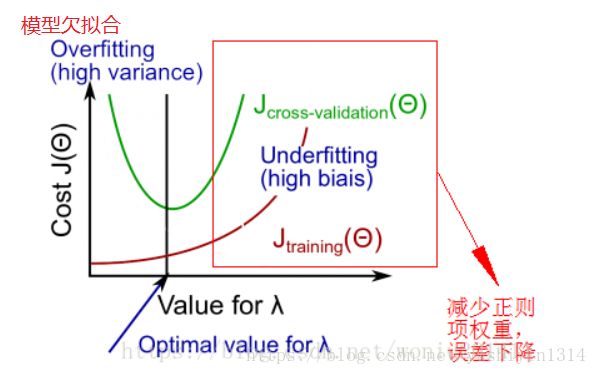
过拟合:增加样本数量、减少特征数目、增加正则项权重
五、模型优化的方法
无论是回归还是分类问题,目的都是找到最好或者说比较好的模型去拟合原来的问题,这里的好就就是使得损失函数的值较小且模型的泛化能力好。
(1)交叉验证
上面已经介绍了主要思想,这个主要是选择最优的模型以及最优的超参数,对于某个模型来说,最优参数与默认参数对模型的提高不会很大。
(2)特征选择
特征工程是建模的核心,如果特征选择好,那么模型的效果至少好了一半,模型准确率提高特征工程是占绝对作用的。常见的特征选择,我们可以从两个方面去考虑:
1)从已有的特征中选择-----特征选择
基于AIC\BIC\CP值等统计指标:前进法、后退法、前进后退法
基于信息熵:决策树(ID3、CD4.5、CART)
基于编码分箱:woe与iv
2)获取新的特征--------特征提取
常见方法:PCA(主成分分析)、ICA(独立成分分析)\CCA(典型相关分析)、LDA(判别分析)、plsr(偏最小二乘回归)、神经网络
(3)正则化以及常见正则化手段

六、为何正则化可以避免过拟合?
1.Dropout为什么可以减少overfitting?
一般情况下,对于同一组训练数据,利用不同的神经网络训练之后,求其输出的平均值可以减少overfitting。Dropout就是利用这个原理,每次丢掉一定比率的隐藏层神经元,相当于在不同的神经网络上进行训练,这样就减少了神经元之间的依赖性,即每个神经元不能依赖于某几个其他的神经元(指层与层之间相连接的神经元),使神经网络更加能学习到与其他神经元之间的更加健壮robust的特征。在Dropout的作者文章中,测试手写数字的准确率达到了98.7%!所以Dropout不仅减少overfitting,还能提高准确率。
2.L1、L2正则化为何可以减少overfitting?


回到为什么会减少overfitting这个问题,两个解释:
1.从上面可以看出,正则化后效果是均能够使得权值减小。更小的权值w,从某种意义上说,表示网络的复杂度更低,对数据的拟合刚刚好(这个法则也叫做奥卡姆剃刀)
2.过拟合的时候,拟合函数的系数往往非常大,为什么?因为拟合函数需要顾忌每一个点,最终形成的拟合函数波动很大。在某些很小的区间里,函数值的变化很剧烈。这就意味着函数在某些小区间里的导数值(绝对值)非常大,由于自变量值可大可小,所以只有系数足够大,才能保证导数值很大。而正则化是通过约束参数的范数使其不要太大,所以可以在一定程度上减少过拟合情况。
参考:
吴恩达机器学习视频
The Elements of statistical learning 第二版
统计学习方法—李航
机器学习–周志华
https://hit-scir.gitbooks.io/neural-networks-and-deep-learning-zh_cn/content/chap3/c3s5ss1.html
https://blog.csdn.net/Mona_yang/article/details/80937802
https://blog.csdn.net/woniu201411/article/details/80696711