小白循环神经网络RNN LSTM 参数数量 门单元 cell units timestep batch_size
小白循环神经网络RNN LSTM 参数数量 门单元 cell units timestep batch_size
- RNN循环神经网络 timestep batch_size
- LSTM及参数计算
- keras中若干个Cell例如LSTMCell
1.RNN循环神经网络

先来解释一下 batch_size timestep
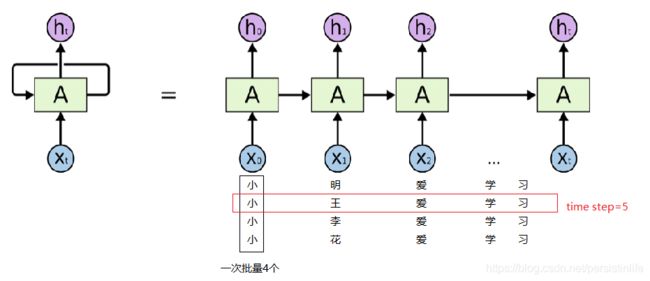
样本数据:
小明爱学习
小王爱学习
小李爱学习
小花爱学习
通常样本数据会以(batch_size, time_step, embedding_size)送入模型,对应的可以是(4,5,100)
4表示批量送入也就是(小,小,小,小)第二批是(明,王,李,花)…
5表示时间步长,一句话共5个字
100表示词嵌入的维度
H t = ϕ ( X t W x h + H ( t − 1 ) W h h + b h ) H_t = \phi(X_tW_{xh}+H_(t-1)W_{hh}+b_h) Ht=ϕ(XtWxh+H(t−1)Whh+bh)
X t X_t Xt输入 假设一次输入4个字符,那么Xt的维度是4*100
W x h W_{xh} Wxh 对应的矩阵大小是 100*hidden_size
X t W x h X_tW_{xh} XtWxh输出大小即为4*hidden_size 也就是说W将词嵌入转换成隐藏层大小
$H_{t-1} $ 也就是 4*hidden_size
W h h W_{hh} Whh 相乘大小就是 hidden_size * hidden_size
b h b_h bh 偏执项大小是1*h通过广播的方式和前面相加
所以最终输出 H t H_t Ht就是4*hidden_size
对于输出层:
O t = H t W h q + b q O_t = H_tW_{hq}+b_q Ot=HtWhq+bq
W h q W_{hq} Whq相应的大小为hidden_size*labels_number
这里labels_number对应的是字典中字的个数,也就是说最终是要预测下一个字的概率
最终输出 O t O_t Ot是4*labels_number
如果是分类任务再加上一个softmax 就得到此次批量4个各自的最大概率的值是什么。
2.LSTM及参数计算
对比上述RNN类比LSTM结构

依然用上面例子,输入timestep=5 及一句话5个字。字嵌入维度是100及一个字用100维表示。设置LSTM(64)输出维度是64及隐含层输出是64维。
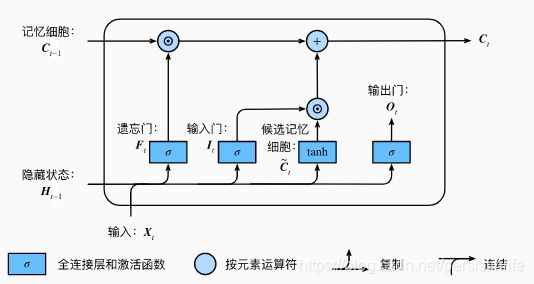
总共三个门结构
遗 忘 门 : F t = σ ( W f [ h t − 1 , x t ] + b f ) 输 入 门 : I t = σ ( W i [ h t − 1 , x t ] + b i ) 输 出 门 : O t = σ ( W o [ h t − 1 , x t ] + b o ) 候 选 记 忆 细 胞 : C t ~ = t a n h ( W c [ h t − 1 , x t ] + b o ) 记 忆 细 胞 : C t = F t ⋅ C t − 1 + I t ⋅ C t ~ 隐 藏 状 态 : H t = O t ⋅ t a n h ( C t ) 遗忘门:F_t = \sigma(W_f[h_{t-1}, x_t] + b_f) \\ 输入门:I_t = \sigma(W_i[h_{t-1}, x_t] + b_i) \\ 输出门:O_t = \sigma(W_o[h_{t-1}, x_t] + b_o) \\ 候选记忆细胞:\tilde{C_{t}}=tanh(W_c[h_{t-1}, x_t] + b_o) \\ 记忆细胞:C_t = F_t\cdot C_{t-1}+I_t\cdot \tilde{C_{t}} \\ 隐藏状态:H_t = O_t \cdot tanh(C_t) 遗忘门:Ft=σ(Wf[ht−1,xt]+bf)输入门:It=σ(Wi[ht−1,xt]+bi)输出门:Ot=σ(Wo[ht−1,xt]+bo)候选记忆细胞:Ct~=tanh(Wc[ht−1,xt]+bo)记忆细胞:Ct=Ft⋅Ct−1+It⋅Ct~隐藏状态:Ht=Ot⋅tanh(Ct)
h t − 1 h_{t-1} ht−1 是上一个隐含层,也就是64。 [ h t − 1 , x t ] [h_{t-1}, x_t] [ht−1,xt] 维度是(1,164) 所以 W f W_f Wf 大小就是(164,64) ,偏执项64
所以通过公式可以看到和 [ h t − 1 , x t ] [h_{t-1}, x_t] [ht−1,xt] 相乘共用4个矩阵,参数数量是(164*64+64 )* 4
σ \sigma σ激活函数是sigmoid输出是[0,1],可以看出几个门输出的值是0到1之间。
tanh输出是[-1, 1],
遗忘门控制上一个记忆细胞信息是否需要保留,输入门控制当前候选细胞。
如果遗忘门一直近似1 输入门近似0 ,记忆细胞会一直记录历史的信息。
对于这样门组合方式是不是可以达到很好的效果,各个门结构实际上在样本中体现在哪里?

上图是李宏毅老师的讲义截图,对于每一个输入都会产生四个矩阵,由这四个矩阵决定最终的输出(这里也可以看出lstm的参数量是普通前馈神经网络的4倍)
例如:输入样本 豆浆喝起来很香醇,油条吃起来嘎嘣脆
当有足够这样多的句式,遗忘门会会将前一句中的主语或动词丢弃,因为后文中主语或吃起来等等和前文没有关系。
有一些改进版本,例如GRU,JANET(JUST ANOTHER NETWORK)保留了遗忘门,由论文中的实验可以看出遗忘门是最重要的门之一https://arxiv.org/yiabs/1804.04849。
实际当中LSTM的传输是将上一层的细胞向量,隐藏层向量和当前输入向量(c,h,x)一起进行计算。如下是李宏毅老师的讲义截图

3.keras中若干个Cell例如LSTMCell
LSTMCell或者其他得cell表示一个cell单元,表示一个step
而LSTM是一个循环层,LSTM也是RNN结构,只是cell是用LSTMCell实现得。
如LSTMCell
LSTMCell或者其他得cell表示一个cell单元,表示一个step
而LSTM是一个循环层,LSTM也是RNN结构,只是cell是用LSTMCell实现得。