目录
- 声学模型
- GRU-CTC
- DFCNN
- DFSMN
- 语言模型
- n-gram
- CBHG
- 数据集
本文搭建一个完整的中文语音识别系统,包括声学模型和语言模型,能够将输入的音频信号识别为汉字。
声学模型使用了应用较为广泛的递归循环网络中的GRU-CTC的组合,除此之外还引入了科大讯飞提出的DFCNN深度全序列卷积神经网络,也将引入阿里的架构DFSMN。
语言模型有传统n-gram模型和基于深度神经网络的CBHG网络结构,该结构是谷歌用于TTS任务中的tacotron系统,本文中将该系统部分结构移植过来用于搭建拼音序列生成汉字序列系统。
数据集采用了目前能找到的所有中文免费数据,包括:thchs-30、aishell、primewords、st-cmd四个数据集,训练集总计大约450个小时。
该项目地址在:https://github.com/audier/my_ch_speech_recognition写的时候可能有些乱,后续会整理。
声学模型
声学模型目前开源了部分示例模型,更大模型将在确认识别结果后更新。
GRU-CTC
我们使用 GRU-CTC的方法搭建了第一个声学模型,在gru_ctc_am.py中,利用循环神经网络可以利用语音上下文相关的信息,得到更加准确地信息,而GUR又能选择性的保留需要的信息。该模型使用python/keras进行搭建,本文系统都基于python搭建。
网络结构如下:
该结构没有真正使用,只是一个基本框架,类似于helloworld,用于作为示例。
def creatModel():
input_data = Input(name='the_input', shape=(500, 26))
layer_h1 = Dense(512, activation="relu", use_bias=True, kernel_initializer='he_normal')(input_data)
layer_h1 = Dropout(0.2)(layer_h1)
layer_h2 = Dense(512, activation="relu", use_bias=True, kernel_initializer='he_normal')(layer_h1)
layer_h2 = Dropout(0.2)(layer_h2)
layer_h3 = Dense(512, activation="relu", use_bias=True, kernel_initializer='he_normal')(layer_h2)
layer_h4_1 = GRU(512, return_sequences=True, kernel_initializer='he_normal', dropout=0.3)(layer_h3)
layer_h4_2 = GRU(512, return_sequences=True, go_backwards=True, kernel_initializer='he_normal', dropout=0.3)(layer_h3)
layer_h4 = add([layer_h4_1, layer_h4_2])
layer_h5 = Dense(512, activation="relu", use_bias=True, kernel_initializer='he_normal')(layer_h4)
layer_h5 = Dropout(0.2)(layer_h5)
layer_h6 = Dense(512, activation="relu", use_bias=True, kernel_initializer='he_normal')(layer_h5)
layer_h6 = Dropout(0.2)(layer_h6)
layer_h7 = Dense(512, activation="relu", use_bias=True, kernel_initializer='he_normal')(layer_h6)
layer_h7 = Dropout(0.2)(layer_h7)
layer_h8 = Dense(1177, activation="relu", use_bias=True, kernel_initializer='he_normal')(layer_h7)
output = Activation('softmax', name='Activation0')(layer_h8)
model_data = Model(inputs=input_data, outputs=output)
#ctc层
labels = Input(name='the_labels', shape=[50], dtype='float32')
input_length = Input(name='input_length', shape=[1], dtype='int64')
label_length = Input(name='label_length', shape=[1], dtype='int64')
loss_out = Lambda(ctc_lambda, output_shape=(1,), name='ctc')([labels, output, input_length, label_length])
model = Model(inputs=[input_data, labels, input_length, label_length], outputs=loss_out)
model.summary()
ada_d = Adadelta(lr=0.01, rho=0.95, epsilon=1e-06)
model=multi_gpu_model(model,gpus=2)
model.compile(loss={'ctc': lambda y_true, output: output}, optimizer=ada_d)
#test_func = K.function([input_data], [output])
print("model compiled successful!")
return model, model_dataDFCNN
由于两个原因在使用GRU作为语音识别的时候我们会遇到问题。一方面是我们常常使用双向循环神经网络才能取得更好的识别效果,这样会影响解码实时性。另一方面随着网络结构复杂性增加,双向GRU的参数是相同节点数全连接层的6倍,这样会导致训练速度非常缓慢。
科大讯飞提出了一种使用深度卷积神经网络来对时频图进行识别的方法,就是DFCNN,利用CNN参数共享机制,可以将参数数量下降一个级别,且深层次的卷积和池化层能够充分考虑语音信号的上下文信息,且可以在较短的时间内就可以得到识别结果,具有较好的实时性。
该模型在cnn_witch_fbank.py和cnn_ctc_am.py中,实验中是所有网络结果最好的模型,目前能够取得较好的泛化能力,声学模型识别率能够达到90%以上,其网络结构如下: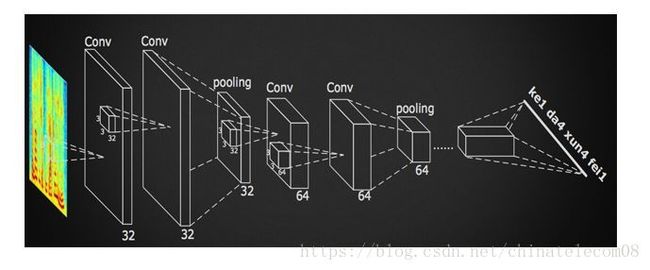
def creatModel():
input_data = Input(name='the_input', shape=(800, 200, 1))
# 800,200,32
layer_h1 = Conv2D(32, (3,3), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(input_data)
layer_h1 = BatchNormalization(mode=0,axis=-1)(layer_h1)
layer_h2 = Conv2D(32, (3,3), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(layer_h1)
layer_h2 = BatchNormalization(axis=-1)(layer_h2)
layer_h3 = MaxPooling2D(pool_size=(2,2), strides=None, padding="valid")(layer_h2)
# 400,100,64
layer_h4 = Conv2D(64, (3,3), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(layer_h3)
layer_h4 = BatchNormalization(axis=-1)(layer_h4)
layer_h5 = Conv2D(64, (3,3), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(layer_h4)
layer_h5 = BatchNormalization(axis=-1)(layer_h5)
layer_h5 = MaxPooling2D(pool_size=(2,2), strides=None, padding="valid")(layer_h5)
# 200,50,128
layer_h6 = Conv2D(128, (3,3), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(layer_h5)
layer_h6 = BatchNormalization(axis=-1)(layer_h6)
layer_h7 = Conv2D(128, (3,3), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(layer_h6)
layer_h7 = BatchNormalization(axis=-1)(layer_h7)
layer_h7 = MaxPooling2D(pool_size=(2,2), strides=None, padding="valid")(layer_h7)
# 100,25,128
layer_h8 = Conv2D(128, (1,1), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(layer_h7)
layer_h8 = BatchNormalization(axis=-1)(layer_h8)
layer_h9 = Conv2D(128, (3,3), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(layer_h8)
layer_h9 = BatchNormalization(axis=-1)(layer_h9)
# 100,25,128
layer_h10 = Conv2D(128, (1,1), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(layer_h9)
layer_h10 = BatchNormalization(axis=-1)(layer_h10)
layer_h11 = Conv2D(128, (3,3), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(layer_h10)
layer_h11 = BatchNormalization(axis=-1)(layer_h11)
# Reshape层
layer_h12 = Reshape((100, 3200))(layer_h11)
# 全连接层
layer_h13 = Dense(256, activation="relu", use_bias=True, kernel_initializer='he_normal')(layer_h12)
layer_h13 = BatchNormalization(axis=1)(layer_h13)
layer_h14 = Dense(1177, use_bias=True, kernel_initializer='he_normal')(layer_h13)
output = Activation('softmax', name='Activation0')(layer_h14)
model_data = Model(inputs=input_data, outputs=output)
# ctc层
labels = Input(name='the_labels', shape=[50], dtype='float32')
input_length = Input(name='input_length', shape=[1], dtype='int64')
label_length = Input(name='label_length', shape=[1], dtype='int64')
loss_out = Lambda(ctc_lambda, output_shape=(1,), name='ctc')([labels, output, input_length, label_length])
model = Model(inputs=[input_data, labels, input_length, label_length], outputs=loss_out)
model.summary()
ada_d = Adadelta(lr=0.01, rho=0.95, epsilon=1e-06)
#model=multi_gpu_model(model,gpus=2)
model.compile(loss={'ctc': lambda y_true, output: output}, optimizer=ada_d)
#test_func = K.function([input_data], [output])
print("model compiled successful!")
return model, model_dataDFSMN
而前馈记忆神经网络也也解决了双向GRU的参数过多和实时性较差的缺点,它利用一个记忆模块,包含了上下几帧信息,能够得到不输于双向GRU-CTC的识别结果,阿里最新的开源系统就是基于DFSMN的声学模型,只不过在kaldi的框架上实现的。我们将考虑使用DFSMN+CTC的结构在python上实现。该网络后续将实现。
结构如下: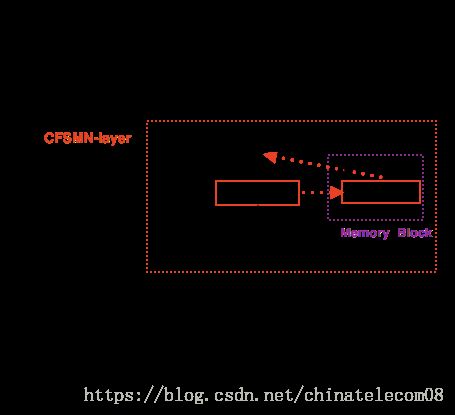
语言模型
n-gram
n元语法是一个非常经典的语言模型,这里不过多介绍啦。
CBHG
该想法来自于一个大神搞输入法的项目,下面部分也引用此处:搜喵出入法
他是利用该模型建立一个按键到汉字的作用,本文对其结构和数据处理部分稍作改动,作为语言模型。
拼音输入的本质上就是一个序列到序列的模型:输入拼音序列,输出汉字序列。所以天然适合用在诸如机器翻译的seq2seq模型上。
模型初始输入是一个随机采样的拼音字母的character embedding,经过一个CBHG的模型,输出是五千个汉字对应的label。
这里使用的CBHG模块是state-of-art的seq2seq模型,用在Google的机器翻译和语音合成中,该模型放在language_model/CBHG.py中,结构如下:
图片来自 Tacotron: Towards End-to-End Speech Synthesis
关于该模型值得注意的几点:
1.模型先使用一系列的一维卷积网络,有一系列的filter,filter_size从1到K,形成一个Conv1D Bank。这样的作用相当于使用了一系列的unigrams, bigrams直到K-grams,尽可能多的拿到输入序列从local到context的完整信息。其实这样的模型,与之前我们提到过的IDCNN(Iterated Dilated Convolutionary Nerual Network)有异曲同工之妙。而IDCNN相比较起来有更少的参数,不知道如果把CBHG的Conv1D Bank换成IDCNN是怎样的效果。
2.模型在最终的BiGRU之前加入了多层的Highway Layers,用来提取更高层次的特征。Highway Layers可以理解为加入了本来不相邻层之间的“高速公路”,可以让梯度更好地向前流动;同时又加入一个类似LSTM中门的机制,自动学习这些高速公路的开关和流量。Highway Networks和Residual Networks、Dense Networks都是想拉近深度网络中本来相隔很远的层与层之间的距离,使很深的网络也可以比较容易地学习。
3.模型中还使用了Batch Normalization(继ReLU之后大家公认的DL训练技巧),Residual Connection(减少梯度的传播距离),Stride=1的Max-pooling(保证Conv的局部不变性和时间维度的粒度)以及一个时髦的BiGRU。Tacotron: Towards End-to-End Speech Synthesis这篇文章发表在2017年4月,最潮的DL技术用到了很多。
项目基于深度学习的中文语音识别系统中language_model/文件夹中已经默认放置了例子语料,可以通过直接运行CBHG.py进行数据预处理、模型训练、和模型测试,下面是我用项目中的默认数据在12G GPU上训练了大概小半天的模型识别结果,如果利用网络爬虫增加数据集,将会有更好的泛化结果。
请输入测试拼音:ta1 mei2 you3 duo1 shao3 hao2 yan2 zhuang4 yu3 dan4 ta1 que4 ba3 ai4 qin1 ren2 ai4 jia1 ting2 ai4 zu3 guo2 ai4 jun1 dui4 wan2 mei3 de tong3 yi1 le qi3 lai2
她没有多少豪言壮语但她却把爱亲人爱家庭爱祖国爱军队完美地统一了起来
请输入测试拼音:chu2 cai2 zheng4 bo1 gei3 liang3 qian1 san1 bai3 wan4 yuan2 jiao4 yu4 zi1 jin1 wai4 hai2 bo1 chu1 zhuan1 kuan3 si4 qian1 wu3 bai3 qi1 shi2 wan4 yuan2 xin1 jian4 zhong1 xiao3 xue2
除财政拨给两千三百万元教太资金外还拨出专款四千五百七十万元新建中小学
请输入测试拼音:ke3 shi4 chang2 chang2 you3 ren2 gao4 su4 yao2 xian1 sheng1 shuo1 kan4 jian4 er4 xiao3 jie3 zai4 ka1 fei1 guan3 li3 he2 wang2 jun4 ye4 wo4 zhe shou3 yi1 zuo4 zuo4 shang4 ji3 ge4 zhong1 tou2
可是常常有人告诉姚先生说看见二小姐在咖啡馆里和王俊业握着族一坐坐上几个钟头数据集
数据集采用了目前我能找到的所有中文免费数据,包括:thchs-30、aishell、primewords、st-cmd四个数据集,训练集总计大约450个小时,在实验过程中,使用thchs-30+aishell+st-cmd数据集对DFCNN声学模型进行训练,以64batch_size训练。
- 数据集
- 共计约430小时,相关链接:http://www.openslr.org/resources.php
st-cmd、primewords、Aishell、thchs30四个数据集,整理为相同格式,放于
some_expriment\data_process\datalist中。包含了解压后数据的路径,以及训练所需的数据标注格式,其中prime数据没有区分训练集等,为我手工区分。各个数据集的数量(句)如下:Name train dev test aishell 120098 14326 7176 primewords 40783 5046 5073 thchs-30 10000 893 2495 st-cmd 10000 600 2000
这是目前能找到的所有开源中文语料,如果还有希望大神能够留言提示。
转载请注明出处:https://www.cnblogs.com/sunhongwen/p/9613674.html