AttributeError: 'NoneType' object has no attribute 'sc' 解决方法(二)
上一次本以为可以解决了这个问题,然而并没有那么地简单。博主最近在edx网站学习pyspark,想打一下视频上的代码,结果报错了,依旧是报了“AttributeError:’NoneType’ object has no attribute ‘sc’”,当时就有种怀疑人生的感觉。之后通过谷歌、百度均无果,最后直接就在大名鼎鼎的stack overflow网站,用蹩脚的英语提问,在一个大神的带领下,找到了问题的根源。第一次在stack overflow提问,第一次用英语向技术大牛阐述问题,虽然犯了很多错误,但是非常刺激和享受
扯远了。首先依旧先说明一下,博主的开发环境设置:
- 操作系统:windows 7
- 开发平台:anconda3
- 开发语言:python3
- spark版本:spark1.6.0(我用的是Jupyter Notebook来代替pyspark shell的)
我的目的是想建立一个DataFrame。代码如下:
sc.stop() #关掉之前的sc,防止运行多个sc
print(sc)
data2=[("Alice",5),("Bob",5),("Tom",5)]
print(data2)
df=sqlContext.createDataFrame(data2,["name","age"]) #建立dataframe
df.show() #把建立的dataframe显示出来结果报错了:
SparkContext object at 0x000000000483CA90>
[('Alice', 5), ('Bob', 5), ('Tom', 5)]
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
8-3dc21e7bb7c4> in <module>()
3 data2=[("Alice",5),("Bob",5),("Tom",5)]
4 print(data2)
----> 5 df=sqlContext.createDataFrame(data2,["name","age"]) #建立dataframe
6 df.show() #把建立的dataframe显示出来
D:\spark\spark-1.6.0-bin-hadoop2.6\python\pyspark\sql\context.py in createDataFrame(self, data, schema, samplingRatio)
426 rdd, schema = self._createFromRDD(data, schema, samplingRatio)
427 else:
--> 428 rdd, schema = self._createFromLocal(data, schema)
429 jrdd = self._jvm.SerDeUtil.toJavaArray(rdd._to_java_object_rdd())
430 jdf = self._ssql_ctx.applySchemaToPythonRDD(jrdd.rdd(), schema.json())
D:\spark\spark-1.6.0-bin-hadoop2.6\python\pyspark\sql\context.py in _createFromLocal(self, data, schema)
358 # convert python objects to sql data
359 data = [schema.toInternal(row) for row in data]
--> 360 return self._sc.parallelize(data), schema
361
362 @since(1.3)
D:\spark\spark-1.6.0-bin-hadoop2.6\python\pyspark\context.py in parallelize(self, c, numSlices)
410 [[], [0], [], [2], [4]]
411 """
--> 412 numSlices = int(numSlices) if numSlices is not None else self.defaultParallelism
413 if isinstance(c, xrange):
414 size = len(c)
D:\spark\spark-1.6.0-bin-hadoop2.6\python\pyspark\context.py in defaultParallelism(self)
346 reduce tasks)
347 """
--> 348 return self._jsc.sc().defaultParallelism()
349
350 @property
AttributeError: 'NoneType' object has no attribute 'sc'
从上面的代码显示说明了,空对象没有sc这个属性,于是乎我按照以前的经验,初始化一个的新的sc,代码如下:
sc.stop() #关掉之前的sc,防止运行多个sc
print(sc)
sc=SparkContext("local","hello") #初始化一个新的sc
data2=[("Alice",5),("Bob",5),("Tom",5)]
print(data2)
df=sqlContext.createDataFrame(data2,["name","age"]) #建立dataframe
df.show() #把建立的dataframe显示出来报错的结果还是一样。限于篇幅,就不重新再显示一次了。于是间我开始在stack overflow网站请教哪些大牛,他们给予我的建议就是”在一个shell里面最好就运行一个sc,不要去停止,也不要去重新建一个。“一开始无法理解这句话是什么意思?第二天,一次偶然的机会,我重新打开了pyspark的编辑界面,我把sc.stop()去掉,也把sc=SparkContext(“local”,”hello”)去掉,重新run一遍,结果好了!
代码如下:
print(sc)
data2=[("Alice",5),("Bob",5),("Tom",5)]
print(data2)
df=sqlContext.createDataFrame(data2,["name","age"]) #建立dataframe
df.show() #把建立的dataframe显示出来结果如下:
[('Alice', 5), ('Bob', 5), ('Tom', 5)]
+-----+---+
| name|age|
+-----+---+
|Alice| 5|
| Bob| 5|
| Tom| 5|
+-----+---+ perfect!如果故事就在这里完美,那你就错了,因为我很爱整事儿!
于是我在上面的代码再加一句sc.stop(),run一下,结果又是报了之前的错误—-AttributeError: ‘NoneType’ object has no attribute ‘sc’。接下来我把sc.stop()去掉了,再run一下,结果又报错了,依旧是那个错误———–AttributeError: ‘NoneType’ object has no attribute ‘sc’。怎么会这样呢?为什么一开始没有加sc.stop()不会报错,而后来加了sc.stop()再去掉sc.stop()就会报错了?如果报了错,我是不是把sc.stop()去掉,然后再重启一次pyspark shell才能解决呢?
后来又是偶然发现Jupyter Notebook的Kernel选项有个restart的功能,于是我就点击restart,然后把之前的代码(已经去掉sc.stop())再run一遍,结果就没有报错了。
具体操纵如下:点击Kernel,然后点击Restart,或者Restart &run all即可:
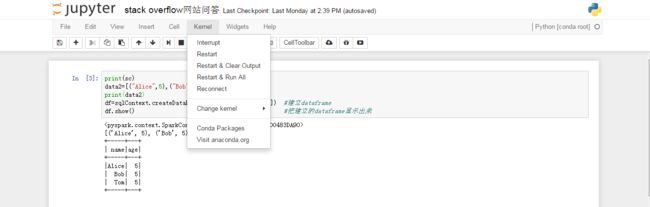
这样就可以解决AttributeError: ‘NoneType’ object has no attribute ‘sc’ 这个问题了。