广义线性模型分类
logistic 回归模型
logistic regression是统计学习中经典的分类算法,属于对数线性模型。
回归模型:
给定一个数据集合 (x1,y1)(x2,y2)…(xn,yn) ,有监督学习构建模型,学习过程就是模型参数 θ 的学习过程。作为discrimination algorithm,对 P(Y|X;θ) 建模,
针对二分类问题,我们选择logitic 分布来描述 P(Y|X) 的分布, g(x)=ex1+ex
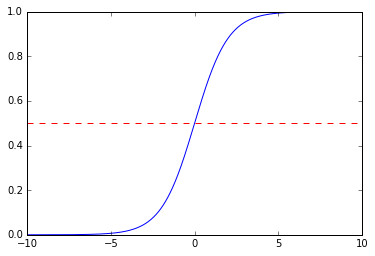
这样logistic回归模型为
在预测时,给定Input value x,分别计算P(y=1|x),P(y=0|x),x属于概率大的那个类别。
模型参数估计:
定义模型后,需要基于DataSet学习模型参数,也就是 θ ,使得数据的概率最大,我们可以用极大似然估计法估计模型参数。
为了方便计算,定义:
p(y=1|x;θ)=π(x),p(y=0|x;θ)=1−π(x)
则有:
p(y|x;θ)=π(x)y(1−π(x))1−y
定义参数的似然函数 L(θ)=P(Y|X;θ)=∏i=1np(yi|xi,θ) ∏Ni=1p(yi|xi;θ),
对数似然函数:
那么代价函数为
目前是求 J(θ) 的极大值。
采用的方法是梯度下降法,即:
实例-预测性别
import numpy as np
from matplotlib.pylab import imread
import os
## PCA获取主特征向量和均值
def PCA(date,args=0.95):
numsFeatures,numsSamples=date.shape
mean=np.sum(date,1)/numsSamples
mean_date=date-np.outer(mean,np.ones(numsSamples)) # 中心化的矩阵
if numsFeatures>numsSamples:
covar_mat=np.dot(mean_date.T,mean_date) # 计算协方差
eigvec,eigval,temp = np.linalg.svd(covar_mat) # 计算特征值和特征向量
eigvec=np.dot(mean_date,eigvec)
else:
covar_mat=np.dot(mean_date,mean_date.T)
eigvec,eigval,temp= np.linalg.svd(covar_mat);
if args>=1:
return eigvec[:,0:int(args)],mean
else:
temp_sum,d,eig_sum=0,0,np.sum(eigval)
while temp_sum/eig_sum1
return eigvec[:,0:d],mean;
## 根据主特征向量和均值获取对应的坐标
def Dime_reduction(date,eigvec,mean):
return np.dot(eigvec.T,date-np.outer(mean,np.ones(date.shape[1])))
# 对数据进行预处理
def Pre_Process(date):
## 增加一个属性元素
numsFeatures,numsSamples=date.shape
date=list(date)
date.append(np.ones(numsSamples))
date=np.array(date)
numsFeatures,mean=numsFeatures+1,np.mean(date,1)
## 均匀化
var=np.max(date,1)-np.min(date,1)
indice=np.zeros(date.shape)
indice=date-np.kron(mean,np.ones((numsSamples,1))).T
for i in range(numsFeatures):
if var[i]!=0:
indice[i]=indice[i]/var[i]
else:
indice[i],var[i]=1,date[i,0]
return indice,mean,var
def TrainLogRegres(train_x, train_y, opts):
numFeatures,numSamples = train_x.shape
alpha = opts['alpha']; maxIter = opts['maxIter']
weights,error,k = np.ones(numFeatures),np.ones(numSamples),0
# optimize through gradient descent algorilthm
while kand np.dot(error,error)>1e-3:
output = 1/(1+np.exp(-np.dot(weights,train_x)))
error = train_y - output
weights = weights + alpha * np.dot(train_x , error.T)
k=k+1
return weights
# 读取训练数据
def Read_Train_data():
path_male,path_female='./训练数据/男性样本','./训练数据/女性样本'
file_male,file_female=os.listdir(path_male),os.listdir(path_female)
date=np.zeros((len(file_male)+len(file_female),112,92))
## 开始都数据
for i in range(len(file_male)):
date[i]=imread(path_male+'/'+file_male[i])
for i in range(len(file_female)):
date[i+len(file_male)]=imread(path_female+'/'+file_female[i])
# 设置标记label
label=np.zeros(date.shape[0])
label[0:len(file_male)]=1
temp=np.zeros((date.shape[0],112*92))
for i in range(date.shape[0]):
temp[i]=date[i].reshape(112*92)
return temp.T,label
# 读取测试数据
def Read_Test_data():
path_male,path_female='./测试样本/男性样本','./测试样本/女性样本'
file_male,file_female=os.listdir(path_male),os.listdir(path_female)
date=np.zeros((len(file_male)+len(file_female),112,92))
## 开始都数据
for i in range(len(file_male)):
date[i]=imread(path_male+'/'+file_male[i])
for i in range(len(file_female)):
date[i+len(file_male)]=imread(path_female+'/'+file_female[i])
# 设置标记label
label=np.zeros(date.shape[0])
label[0:len(file_male)]=1
temp=np.zeros((date.shape[0],112*92))
for i in range(date.shape[0]):
temp[i]=date[i].reshape(112*92)
return temp.T,label
def Pre_Peidict(date,PCA_eigvec,PCA_mean,train_mean,train_var):
indice=Dime_reduction(date,PCA_eigvec,PCA_mean)
indice=list(indice)
indice.append(np.ones(date.shape[1]))
indice=np.array(indice)
for i in range(indice.shape[0]):
indice[i]=(indice[i]-train_mean[i])/train_var[i]
return indice
def Predict_result(date,weight):
output = 1/(1+np.exp(-np.dot(weight,date)))
for i in range(output.shape[0]):
if output[i]>=0.5:
output[i]=1
else:
output[i]=0
return output
def Predict_ratio(output,label):
count=numSample=label.shape[0]
for i in range(numSample):
if label[i] != output[i]:
count=count-1
return count/numSample
# 测试和训练数据
if __name__ == '__main__':
train_date,train_label=Read_Train_data()
PCA_eigvec,PCA_mean=PCA(train_date,0.95)
train_indice=Dime_reduction(train_date,PCA_eigvec,PCA_mean)
train_indice,train_mean,train_var=Pre_Process(train_indice)
weights=TrainLogRegres(train_indice,train_label,{'alpha':0.01,'maxIter':1000})
test_date,test_label=Read_Test_data()
indice=Pre_Peidict(test_date,PCA_eigvec,PCA_mean,train_mean,train_var)
output=Predict_result(indice,weights)
print('正确率为:',Predict_ratio(output,test_label)) 具体的数据参考:http://download.csdn.net/my/uploads
多分类
指数分布族(The Exponential Family)
如果一个分布可以用如下公式表达,那么这个分布就属于指数分布族:
其中 y 是随机变量, h(x) 称为基础度量值(base measure), η 称为分布的自然参数(natural parameter),也称为标准参数(c anonical parameter), T(y) 称为充分统计量,通常 T(y)=y , a(η) 称为对数分割函数(log partition function), e−a(η) 本质上是一个归一化常数,确保概率 p(y;η) 和为1;当 T(y) 被固定时, a(η),b(η) 就定义了一个以 η 为参数的一个指数分布。我们变化η 就得到这个分布的不同分布。
伯努利分布属于指数分布族。伯努利分布均值为 ϕ ,写为Bernoulli( ϕ ),是一个二值分布, y∈{0,1} 。所以 p(y=1;ϕ)=ϕ;p(y=0;ϕ)=1−ϕ 。当我们变化 ϕ 就得到了不同均值的伯努利分布。伯努利分布表达式转化为指数分布族表达式过程如下:
其中
许多其他分部也属于指数分布族,例如:伯努利分布(Bernoulli)、高斯分布(Gaussian)、多项式分布(Multinomial)、泊松分布(Poisson)、伽马分布(Gamma)、指数分布(Exponential)、 β 分布、Dirichlet分布、Wishart分布.
广义线性模型(Constructing GLMs)
在分类和回归问题中,我们通过构建一个关于 x 的模型来预测 y 。这种问题可以利用广义线性模型(Generalized linear models,GMLs)来解决。构建广义线性模型我们基于三个假设,也可以理解为我们基于三个设计决策,这三个决策帮助我们构建广义线性模型:
- y|x;θ∼ExponentialFamily(η) ,假设 y|x;θ 满足一个以 θ 为参数的指数分布。
- 给定 x ,我们的目标是要确定 T(y) ,即 h(x)=E[T(y)|x] 。大多数情况下T(y)=y,那么我们实际上要确定的是 h(x)=E[y|x] 。
- 假设自然参数 η 和 x 是线性相关,即假设: η=θTx
多项分布属于指数分布族
多分类模型的输出结果为该样本属于 k 个类别的概率,从这 k 个概率中我们选择最优的概率对应的类别(通常选概率最大的类别),作为该样本的预测类别。这 k 个概率用 k 个变量, ϕ1,ϕ2,⋯ϕk 表示。这 k 个变量和为1,即满足
ϕk 可以用前 k−1 个变量来表示,即:
使用广义线性模型拟合这个多分类问题,首先要验证这个多项分布是否符合一个指数分布族。定义 T(y) 为
T(y) 不是一个数值,而是一个 k−1 维的向量。使用 (T(y))i 符号表示向量 T(y) 的第 i 个元素。
引入一个新符号: 1{Boolean} ,如果括号内为true则这个符号取1,反之取0,即 1{True} , 0{False} 。所以, T(y) 与 y 的关系就可以表示为 (Y(y)i=1){y=i}
(Y(y)i) 和 ϕi 的关系:
即:
多项分布表达式转化为指数分布族表达式过程如下:
其中
Softmax函数(Softmax Function)
在使用广义线性模型拟合这个多项式分布模型之前,需要先推导一个函数,这个函数在广义线性模型的目标函数中会用到。这个函数称为Softmax函数(Softmax Function)
由 η 表达式可得:
另 ηk=log(ϕk/ϕk)=0 ,那么:
则
这个 ϕi 关于 η 的的函数称为Softmax函数(Softmax Function)。
广义线性构建模型
根据广义线性模型的第三个假设:
θ 是模型中的参数,为了符号上的方便我们定义 θk=1 ,所以
ηk=θTkx=0
所以模型在给定 x 的条件下 y 的分布为:
上面的表达式求解的是在 y=i 时的概率。在Softmax回归这个广义线性模型中,目标函数是:
求解了这个目标函数,我们就构造出了分类模型:
目标函数推导过程如下:
现在利用数据来求解目标函数 hθ(x) :参数拟合的问题;
对数似然函数为
用梯度下降法求解此模型,关于 θk 的梯度向量为:
实例
# -*- coding: utf-8 -*-
"""
Created on Sat Jun 11 16:51:09 2016
@author: Selena
"""
import numpy as np
from matplotlib.pylab import imread
import os
## PCA获取主特征向量和均值
def PCA(date,args=0.95):
numsFeatures,numsSamples=date.shape
mean=np.sum(date,1)/numsSamples
mean_date=date-np.outer(mean,np.ones(numsSamples)) # 中心化的矩阵
if numsFeatures>numsSamples:
covar_mat=np.dot(mean_date.T,mean_date) # 计算协方差
eigvec,eigval,temp = np.linalg.svd(covar_mat) # 计算特征值和特征向量
eigvec=np.dot(mean_date,eigvec)
else:
covar_mat=np.dot(mean_date,mean_date.T)
eigvec,eigval,temp= np.linalg.svd(covar_mat);
if args>=1:
return eigvec[:,0:int(args)],mean
else:
temp_sum,d,eig_sum=0,0,np.sum(eigval)
while temp_sum/eig_sum1
return eigvec[:,0:d],mean;
## 根据主特征向量和均值获取对应的坐标
def Dime_reduction(date,eigvec,mean):
return np.dot(eigvec.T,date-np.outer(mean,np.ones(date.shape[1])))
# 对数据进行预处理
def Pre_Process(date):
## 增加一个属性元素
numsFeatures,numsSamples=date.shape
date=list(date)
date.append(np.ones(numsSamples))
date=np.array(date)
numsFeatures,mean=numsFeatures+1,np.mean(date,1)
## 均匀化
var=np.max(date,1)-np.min(date,1)
indice=np.zeros(date.shape)
indice=date-np.kron(mean,np.ones((numsSamples,1))).T
for i in range(numsFeatures):
if var[i]!=0:
indice[i]=indice[i]/var[i]
else:
indice[i],var[i]=1,date[i,0]
return indice,mean,var
def TrainLogRegres(train_x, train_y, opts):
numFeatures,numSamples = train_x.shape
alpha = opts['alpha']; maxIter = opts['maxIter']
weights,error,k = np.ones(numFeatures),np.ones(numSamples),0
# optimize through gradient descent algorilthm
while kand np.dot(error,error)>1e-3:
output = 1/(1+np.exp(-np.dot(weights,train_x)))
error = train_y - output
weights = weights + alpha/numSamples * np.dot(train_x , error.T)
k=k+1
return weights
# 读取训练数据
def Read_Train_data():
path_male,path_female='./训练数据/男性样本','./训练数据/女性样本'
file_male,file_female=os.listdir(path_male),os.listdir(path_female)
date=np.zeros((len(file_male)+len(file_female),112,92))
## 开始都数据
for i in range(len(file_male)):
date[i]=imread(path_male+'/'+file_male[i])
for i in range(len(file_female)):
date[i+len(file_male)]=imread(path_female+'/'+file_female[i])
# 设置标记label
label=np.zeros(date.shape[0])
label[0:len(file_male)]=1
temp=np.zeros((date.shape[0],112*92))
for i in range(date.shape[0]):
temp[i]=date[i].reshape(112*92)
return temp.T,label
# 读取测试数据
def Read_Test_data():
path_male,path_female='./测试样本/男性样本','./测试样本/女性样本'
file_male,file_female=os.listdir(path_male),os.listdir(path_female)
date=np.zeros((len(file_male)+len(file_female),112,92))
## 开始都数据
for i in range(len(file_male)):
date[i]=imread(path_male+'/'+file_male[i])
for i in range(len(file_female)):
date[i+len(file_male)]=imread(path_female+'/'+file_female[i])
# 设置标记label
label=np.zeros(date.shape[0])
label[0:len(file_male)]=1
temp=np.zeros((date.shape[0],112*92))
for i in range(date.shape[0]):
temp[i]=date[i].reshape(112*92)
return temp.T,label
def Pre_Peidict(date,PCA_eigvec,PCA_mean,train_mean,train_var):
indice=Dime_reduction(date,PCA_eigvec,PCA_mean)
indice=list(indice)
indice.append(np.ones(date.shape[1]))
indice=np.array(indice)
for i in range(indice.shape[0]):
indice[i]=(indice[i]-train_mean[i])/train_var[i]
return indice
def Predict_result(date,weight):
output = 1/(1+np.exp(-np.dot(weight,date)))
for i in range(output.shape[0]):
if output[i]>=0.5:
output[i]=1
else:
output[i]=0
return output
def Predict_ratio(output,label):
count=numSample=label.shape[0]
for i in range(numSample):
if label[i] != output[i]:
count=count-1
return count/numSample
# 测试和训练数据
if __name__ == '__main__':
train_date,train_label=Read_Train_data()
PCA_eigvec,PCA_mean=PCA(train_date,0.95)
train_indice=Dime_reduction(train_date,PCA_eigvec,PCA_mean)
train_indice,train_mean,train_var=Pre_Process(train_indice)
weights=TrainLogRegres(train_indice,train_label,{'alpha':10,'maxIter':1000})
test_date,test_label=Read_Test_data()
indice=Pre_Peidict(test_date,PCA_eigvec,PCA_mean,train_mean,train_var)
output=Predict_result(indice,weights)
print('正确率为:',Predict_ratio(output,test_label)) 具体数据参考:http://download.csdn.net/detail/u010910642/9546395
Softmax 回归 vs. k 个二元分类器
在分类系统中,需要对k种类型分类,那么是选择使用 softmax 分类器呢,还是使用 logistic 回归算法建立 k 个独立的二元分类器呢?
这一选择取决于你的类别之间是否互斥,例如,如果你有四个类别的音乐,分别为:古典音乐、乡村音乐、摇滚乐和爵士乐,那么你可以假设每个训练样本只会被打上一个标签(即:一首歌只能属于这四种音乐类型的其中一种),此时你应该使用类别数 k = 4 的softmax回归。(如果在你的数据集中,有的歌曲不属于以上四类的其中任何一类,那么你可以添加一个“其他类”,并将类别数 k 设为5。)
如果你的四个类别如下:人声音乐、舞曲、影视原声、流行歌曲,那么这些类别之间并不是互斥的。例如:一首歌曲可以来源于影视原声,同时也包含人声 。这种情况下,使用4个二分类的 logistic 回归分类器更为合适。这样,对于每个新的音乐作品 ,我们的算法可以分别判断它是否属于各个类别。
现在我们来看一个计算视觉领域的例子,你的任务是将图像分到三个不同类别中。(i) 假设这三个类别分别是:室内场景、户外城区场景、户外荒野场景。你会使用sofmax回归还是 3个logistic 回归分类器呢? (ii) 现在假设这三个类别分别是室内场景、黑白图片、包含人物的图片,你又会选择 softmax 回归还是多个 logistic 回归分类器呢?
在第一个例子中,三个类别是互斥的,因此更适于选择softmax回归分类器 。而在第二个例子中,建立三个独立的 logistic回归分类器更加合适。