RocketMQ 源码阅读 ---- 消息存储(普通消息)
零、关键词解释
cache 是为了弥补高速设备和低速设备的鸿沟而引入的中间层,最终起到**加快访问速度**的作用。
buffer 的主要目的进行流量整形,把突发的大数量较小规模的 I/O 整理成平稳的小数量较大规模的 I/O,以**减少响应次数**(比如从网上下电影,你不能下一点点数据就写一下硬盘,而是积攒一定量的数据以后一整块一起写,不然硬盘都要被你玩坏了)。 -- 知乎
数据复制:当我们在某段代码中往某个文件写入一段字符串的时候,实际发生了什么呢?数据从 Application Memory 逐渐被复制到 Disk,中间会有多次数据复制 Application Memory -> Page Cache -> Disk 。读数据的时候,顺序反过来。
内存映射:内存映射( 即 Memory Map,简称
mmap 也被称为 zero-copy 技术) , 如
Java NIO 中 的
MappedByteBuffer 或者 MappedFileChannel 用的就是这项技术,它的作用其实就是不再使用应用层自己的内存空间(也就是用户空间的内存),直接操作 Page Cache 区域,减少了数据复制。
通俗解释,在应用这一层,是让你把文件的某一段,当作内存一样来访问。
Consumer 消费消息过程,使用了零拷贝,零拷贝包含以下两种方式
1. 使用 mmap + write 方式
优点:即使频繁调用,使用小块文件传输,效率也很高
缺点:不能很好的利用 DMA 方式,会比 sendfile 多消耗 CPU,内存安全性控制复杂,需要避免 JVM Crash
问题。
2. 使用 sendfile 方式
优点:可以利用 DMA 方式,消耗 CPU 较少,大块文件传输效率高,无内存安全新问题。
缺点:小块文件效率低于 mmap 方式,只能是 BIO 方式传输,不能使用 NIO。
RocketMQ 选择了第一种方式,mmap+write 方式,因为有小块数据传输的需求,效果会比 sendfile 更好。
一、前言
存储子系统的选择。理论上,从速度上,文件系统 > 分布式 KV (持久化的,MongoDB)> 分布式文件系统 > 数据库,而可靠性则相反。
诸如Kafka之类的消息中间件,在队列数上升时性能会产生巨大的损失,RocketMQ之所以能单机支持上万的持久化队列与其独特的
存储结构和
mmap 技术来实现。
分区(partition 对应 RocketMQ 的 queue)数量在Kafka中有什么作用?
Producer(消息发送者)的往消息Server的写入并发数与分区数成正比。
Consumer(消息消费者)消费某个Topic的并行度与分区数保持一致,假设分区数是20,那么Consumer的消费并行度最大为20。
每个Topic由固定数量的分区数组成,分区数的多少决定了单台Broker能支持的Topic数量,Topic数量又决定了支持的业务数量。
为什么Kafka不能支持更多的分区数?
每个分区
存储了完整的消息数据,虽然每个分区写入是磁盘顺序写,但是多个分区同时顺序写入
在操作系统层面变为了随机写入。
由于数据分散为多个文件,很难利用IO层面的GroupCommit机制,网络传输也会用到类似优化算法。
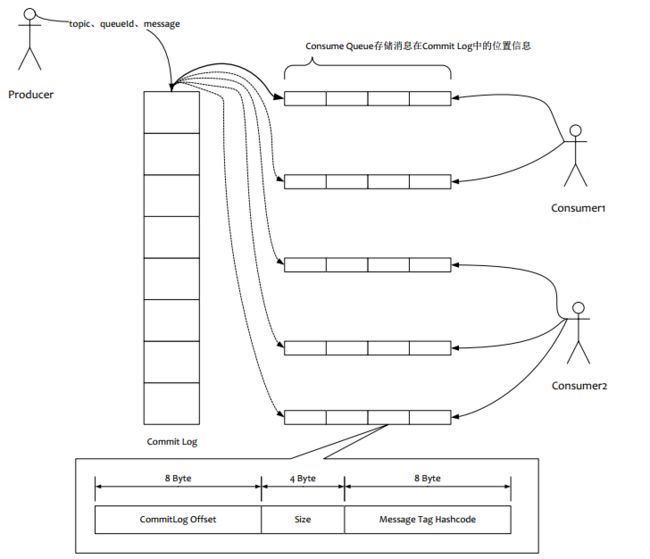
RocketMQ 存储架构
如上图所示,所有的消息数据单独存储到一个 Commit Log,
完全顺序写,随机读。对最终用户展现的队列(ConsumeQueue)实际只存储消息在 Commit Log 的
位置信息和 Tag 的 hashcode,并且串行方式刷盘。
顺序写高性能磁盘最高能到 600M/s,但是磁盘随机写的速度只有大概 100KB/ s,相差6000倍,所以存储方式和方法的选择会导致好几个数量级的队列性能差距。
架构优点:
-
队列轻量化,单个队列数据非常少
-
对磁盘访问串行化,避免磁盘竞争,不会因为队列增加导致 IOWAIT 增加
这么设计带来的缺点:
-
写虽然是顺序写,但是读却变成了随机读
-
读一条消息先读 ConsumeQueue,再去找到对应 CommitLog 消息,多了一次读取操作
-
要保证 CommitLog 与 ConsumeQueue 完全一致,增加了编程复杂度
以上缺点如何克服:
-
随机读,尽可能能去命中 Page Cache,减少读 IO 操作,所以内存越大越好。如果系统中堆积消息过多,读数据要访问磁盘会不会由于随机读导致系统性能急剧下降,答案是否定的
(1)访问 Page Cache 时,即使只访问 1k 的消息,系统也会提前预读出更多数据,在下次读的时候,就可能命中内存。
(2)随机访问 CommitLog 磁盘数据,系统 IO 调度算法设置为 NOOP 方式,会在一定程度上将完全的随机读变成顺序跳跃方式,而顺序跳跃方式读较完全的随机读性能会高 5 倍以上
(3)另外 4k 的消息在完全随机访问情况下,仍可以到达 8k 次每秒以上的读性能
-
由于 ConsumeQueue 存储数据量极少,而且是顺序读,在 Page Cache 预读作用下,即使消息堆积,ComsumeQueue 的读取性能几乎与内存一致。所以可以认为 ConsumeQueue 完全不阻碍读性能。
-
CommitLog 存储了所有元信息,包含消息体,类似于 MySQL 的 binlog,所以只要有 CommitLog 在,ConsumeQueue 即使数据丢失,仍然可以恢复出来
存储目录结构:
|-- abort
|-- checkpoint
|-- config
| |-- consumerOffset.json
| |-- consumerOffset.json.bak
| |-- delayOffset.json
| |-- delayOffset.json.bak
| |-- subscriptionGroup.json
| |-- subscriptionGroup.json.bak
| |-- topics.json
| `-- topics.json.bak
|-- commitlog
| |-- 00000003384434229248
| |-- 00000003385507971072
| `-- 00000003386581712896
`-- consumequeue
|-- %DLQ%ConsumerGroupA
| `-- 0
| `-- 00000000000006000000
|-- %RETRY%ConsumerGroupA
| `-- 0
| `-- 00000000000000000000
|-- %RETRY%ConsumerGroupB
| `-- 0
| `-- 00000000000000000000
|-- SCHEDULE_TOPIC_XXXX
| |-- 2
| | `-- 00000000000006000000
| |-- 3
| | `-- 00000000000006000000
|-- TopicA
| |-- 0
| | |-- 00000000002604000000
| | |-- 00000000002610000000
| | `-- 00000000002616000000
| |-- 1
| | |-- 00000000002610000000
| | `-- 00000000002616000000
|-- TopicB
| |-- 0
| | `-- 00000000000732000000
| |-- 1
| | `-- 00000000000732000000
| |-- 2
| | `-- 00000000000732000000
二、源码阅读

1、2、client 通过 Netty 发送消息的请求 invokeSync(addr, RemotingCommand, timeoutMillis) 在 NettyRemotingServer 的内部类 NettyServerHandler 服务端处理器接收
3、根据请求 code 从 HashMap> processorTable 内存(在 broker 启动的时候写入的对应关系)中拿到对应的处理类,比如现在是发送消息,所以 code=310 对应的是 SendMessageProcessor 处理类。
4、提取出请求头信息
5、响应信息 opaque 保持不变作为请求响应,这样客户端才能用这个跟原来发的请求对应起来。(dubbo 中叫 requestId、responseId 一个道理)
6、对 %RETRY% 类型的消息处理。
如果超过最大消费次数,则 topic 修改成"%DLQ%" + 分组名,即加入死信队列(Dead Letter Queue)
8 ~ 消息持久化到文件
RocketMQ 的消息存储与 Kafka 不同,RocketMQ 存储在 queue 的消息较为简洁,comsume queue 只是存消息的索引,而真正的消息在 commitlog 里面。
(1)ConsumeQueue 消息存储结构(可以理解为消息索引):
|
字段
|
描述
|
数据类型
|
字节
|
|
offset
|
这条消息在commitLog文件实际偏移量
|
long
|
8
|
|
size
|
消息大小
|
int
|
4
|
|
tagsCode
|
消息 tag 哈希值
|
long
|
8
|
(1) topic 和 queueId 来组织文件关系,比如 TopicA 配了读写队列 0、1, 那么 TopicA 和 QueueId=0 组成一个ConsumeQueue,TopicA和Queue=1组成一个另一个ConsumeQueue.
(2) 按消费端 group 分组重试队列,如果消费端消费失败,发送到retry消费队列中
(3) 按消费端 group 分组死信队列,如果消费端重试超过指定次数,发送死信队列
(4) 每个 ConsumeQueue 可以由多个文件组成无限队列被 MapedFileQueue 对象管理
consumeQueue 的消息处理
上述的消息存储只是把消息主体存储到了物理文件中,但是并没有把消息处理到 ConsumeQueue文件中,那么到底是哪里存入的?
任务处理一般都分为两种:
-
同步,把消息主体存入到commitLog的同时把消息存入consumeQueue,RocketMQ 的早期版本就是这样处理的。
-
异步,起一个线程,不停的轮询,将当前的consumeQueue中的offSet和commitLog中的offSet进行对比,将多出来的offSet进行解析,然后put到consumeQueue中的MapedFile中(这就能提升写入性能)。

(2)
CommitLog 消息存储结构(真正的消息数据):
|
序号
|
字段
|
描述
|
数据类型
|
字节
|
|
1
|
totalSize
|
消息总大小
|
int
|
4
|
|
2
|
magicCode
|
|
int
|
4
|
|
3
|
bodyCRC
|
crc 校验码
|
int
|
4
|
|
4
|
queueId
|
队列 id
|
int
|
4
|
|
5
|
flag
|
标志值rocketmq不做处理,只存储后透传
|
int
|
4
|
|
6
|
queueOffset
|
这个值是个自增值不是真正的 consume queue 的偏移量,可以代表这个队列中消息的个数,要通过这个值查找到 consume queue 中数据,QUEUEOFFSET * 20才是偏移地址
|
long
|
8
|
|
7
|
physicOffset
|
物理偏移量。即在 commitlog 文件中的存储位置
|
long
|
8
|
|
8
|
sysFlag
|
指明消息是事务等消息特征
|
int
|
4
|
|
9
|
bornTimeStamp
|
消息生产者生产消息时间
|
long
|
8
|
|
10
|
BORNHOST
|
消息生产者的 ip:port 信息
|
long
|
8
|
|
11
|
STORETIMESTAMP
|
消息存储在 broker 的时间
|
long
|
8
|
|
12
|
STOREHOSTADDRESS
|
消息存储在 broker 的地址
|
long
|
8
|
|
13
|
RECONSUMETIMES
|
消息被某个订阅组重新消费了几次(订阅组之间独立计数),因为重试消息发送到topic=%RETRY%groupName的队列queueId=0的队列中
|
int
|
4
|
|
14
|
Prepared Transaction Offset
|
prepared状态的事物消息
|
long
|
8
|
|
15
|
bodyLength
|
前4个字节存放消息体大小值,后bodylength大小空间存储了消息体内容
|
int
|
4 + bodyLength
|
|
16
|
topicLength
|
前面1个字节存放topic长度,后面存放topic
|
int
|
1 + topicLength
|
|
17
|
propertiesLength
|
前面2字节存放属性长度,后面存放属性数据
|
int
|
2 + propertiesLength
|
// commitlog 文件名还代表文件记录的初始偏移量
this.fileFromOffset = Long.parseLong(this.file.getName());
// MappedFile 是 commitLog、consumequeue 等文件在内存中的映射。
// file = C:\Users\Yibin_Zhu\store\commitlog\00000000000000000000
// MappedFile .java
private static final AtomicLong TOTAL_MAPPED_VIRTUAL_MEMORY = new AtomicLong(0);
private static final AtomicInteger TOTAL_MAPPED_FILES = new AtomicInteger(0);
// 已经写入的位置,比如可以用来与 MappedFile 文件大小比较,判断文件是否满了
protected final AtomicInteger wrotePosition = new AtomicInteger(0);
//ADD BY ChenYang 提交到了哪个位置(这时候还没刷盘)
protected final AtomicInteger committedPosition = new AtomicInteger(0);
// 刷盘到了哪个位置
private final AtomicInteger flushedPosition = new AtomicInteger(0);
// MappedFile 文件大小,默认大小 1024*1024*1024=1073741824=1G
protected int fileSize;
protected FileChannel fileChannel;
/**
* 消息将会先放到这里,如果 writeBuffer 缓存区不为 null,则再放到 FileChannel 中
* Message will put to here first, and then reput to FileChannel if writeBuffer is not null.
*/
protected ByteBuffer writeBuffer = null;
protected TransientStorePool transientStorePool = null;
private String fileName;
private long fileFromOffset; // 文件起始偏移量,从文件名初始化到这里。因为文件顺序写,所有文件都有唯一起始偏移量
// C:\Users\Yibin_Zhu\store\commitlog\00000000000000000000
private File file;
private MappedByteBuffer mappedByteBuffer;
private volatile long storeTimestamp = 0;
private boolean firstCreateInQueue = false;
MappedFile 几个核心方法:
selectMappedBuffer(int pos, int size) 。consumer 从 broker 拉消息的时候,根据位置 pos 从 mappedByteBuffer 获取消息
init(final String fileName, final int fileSize)。初始化 fileChannel、mappedByteBuffer
// 将文件的一部分映射到内存,对 mappedByteBuffer 的变更最终会持久化到文件。当映射一旦完成,就不依赖创建它的 fileChannel 了。 关闭 fileChannel 也不会影响映射。
// 内存映射文件的许多细节本质上依赖于底层操作系统,因此不确定。
// 当请求区域并不完全包含在这个 channelFile 中,这个方法的行为是不确定的。
// 通过此程序或者其他程序,改变文件底层内容或者大小,传播到 buffer 也是不确定的。
// 改变 buffer 传播到文件的速率也是不确定的。
// 对于大多数操作系统,将文件映射到内存比通过通常的读写方法读取或写入几十千字节的数据更昂贵。 从性能的角度来看,通常只需要将相对较大的文件映射到内存中。
MappedByteBuffer mappedByteBuffer = fileChannel.map(MapMode.READ_WRITE, 0, fileSize);
| 方式 |
写入
|
落盘
|
|
方式一
|
写入内存字节缓冲区,direct 类型(writeBuffer)
|
从内存字节缓冲区(wirteBuffer) commit 到 FileChannel【fileChannel.write(byteBuffer)】,fileChannel force到磁盘
|
|
方式二
|
写入映射文件字节缓冲区(mappedByteBuffer)
|
mappedByteBuffer force 到磁盘
|
// MappedFileQueue
使用 CopyOnWriteArrayList mappedFiles 存着多个 mappedFile 的组成的 list。
MappedFile mappedFile = this.mappedFileQueue.getLastMappedFile() // 获取 list 中最后一个 mappedFile
// MappedFileQueue .java
private static final int DELETE_FILES_BATCH_MAX = 10;
private final String storePath; // 存储路径 C:\Users\Yibin_Zhu\store\commitlog
private final int mappedFileSize;
// commitLog 在内存中的映射 mappedFile 的 list
private final CopyOnWriteArrayList() ;
private final AllocateMappedFileService allocateMappedFileService;
private long flushedWhere = 0; // 从哪开始刷盘
private long committedWhere = 0; // 从哪开始提交
private volatile long storeTimestamp = 0;
MapedFileQueue在获取getLastMapedFile时,如果需要创建新的MapedFile会计算出下一个MapedFile文件地址,通过预分配服务AllocateMapedFileService异步预创建下一个MapedFile文件,这样下次创建新文件请求就不要等待,因为创建文件特别是一个1G的文件还是有点耗时的
11、把消息放入内存中
因为是顺序写入 commitLog,所以每次都是从 MappedFileQueue 从取最后一个 mappedFile
加锁写入
//写入的时候,有 2 种 buffer 选择,所以刷盘的时候也是从 2 种 buffer 里面刷
ByteBuffer byteBuffer = writeBuffer != null ? writeBuffer.slice() : this.mappedByteBuffer.slice();
调用 CommitLog 的内部类 DefaultAppendMessageCallback 的 doAppend() 方法
long wroteOffset = fileFromOffset + byteBuffer.position() // 物理偏移量= 文件偏移量 + buffer写到的位置
可选:if ((msgLen + END_FILE_MIN_BLANK_LENGTH) > maxBlank) 如果消息大于文件剩余空间,则文件剩余空间填充 BLANK
//组装好消息,写入 buffer
byteBuffer.put(this.msgStoreItemMemory.array(), 0, msgLen)
12 ~ 15、刷盘 handleDiskFlush(result, putMessageResult, msg)
同步刷盘、异步刷盘
13、 flush(flushLeastPages) 刷盘
同步刷盘类:
// getWroteBytes 即消息长度 msgLen。 long wroteOffset = fileFromOffset + byteBuffer.position();
// GroupCommitRequest request = new GroupCommitRequest(result.getWroteOffset() + result.getWroteBytes());
flushOK = CommitLog.this.mappedFileQueue.getFlushedWhere() >= req.getNextOffset(); // 有新的消息写入
if (!flushOK) { // 刷盘逻辑
CommitLog.this.mappedFileQueue.flush(0);
}
// 这里面 countDown
req.wakeupCustomer(flushOK);
// MappedFile.java
// 刷盘逻辑 -> 刷盘前判断
private boolean isAbleToFlush(final int flushLeastPages) {
int flush = this.flushedPosition.get(); // 刷到了哪个位置
int write = getReadPosition(); // this.writeBuffer == null ? this.wrotePosition.get() : this.committedPosition.get()
if (this.isFull()) {
return true;
}
if (flushLeastPages > 0) {
return ((write / OS_PAGE_SIZE) - (flush / OS_PAGE_SIZE)) >= flushLeastPages;
}
return write > flush;
}
是 CommitLog 的 内部类 class GroupCommitService extends FlushCommitLogService。刷的时候使用 CountDownLatch wait,刷成功 countdown。【fileChannel.force(false) 或者 mappedByteBuffer.force()】
同步刷盘与异步刷盘的唯一区别是异步刷盘写完 Page Cache 直接返回,而同步刷盘需要等待刷盘完成才返回。
异步刷盘的类:
// Asynchronous flush
if (!this.defaultMessageStore.getMessageStoreConfig().isTransientStorePoolEnable()) {
flushCommitLogService.wakeup();
} else {
commitLogService.wakeup();
}
(1)是 CommitLog 的 内部类 class FlushRealTimeService extends FlushCommitLogService。 【fileChannel.force(false) 或者 mappedByteBuffer.force()】
(2)或者使用 CommitRealTimeService 异步刷盘。 只是 commit 到 fileChannel 而不 flush 【fileChannel.write(byteBuffer);】
异步刷盘可能的问题:
(1)在有RAID卡,SAS 15000转磁盘测试
顺序写文件,速度可以达到 300M/s 左右,而线上的网卡一般都为千兆网卡(124MB/s),写磁盘速度明显快于数据网络入口速度,那么是否可以做到写完内存就向用户返回,由后台线程刷盘呢?
由于磁盘速度大于网卡速度,那么刷盘的进度肯定可以跟上消息的写入速度。
(2)万一由于此时系统压力过大,可能堆积消息,除了写入IO,还有读取IO,万一出现磁盘读取落后情况,会不会导致系统内存溢出,答案是否定的,原因如下:
写入消息到PAGECACHE时,如果内存不足,则尝试丢弃干净的PAGE,腾出内存供新消息使用,策略是LRU方式。
如果干净页不足,此时写入PAGECACHE会被阻塞,系统尝试刷盘部分数据,大约每次尝试32个PAGE,来找出更多干净PAGE。
综上,内存溢出的情况不会出现。
| 后台服务 |
操作内容
|
性能
|
|
CommitRealTimeService
|
异步刷盘 && buff 由 linux 系统自动 flush 到磁盘
|
最好
|
|
FlushRealTimeService
|
异步刷盘 && buff 由应用 flush 到磁盘
|
中等
|
|
GroupCommitService
|
同步刷盘
|
最差
|
14、从刷盘 offset 找到需要刷盘的 mappedFile
findMappedFileByOffset(this.flushedWhere, this.flushedWhere == 0)
15、找到 mappedFile 后,开始刷盘 mappedFileQueue.flush(flushLeastPages)
如果使用 FlushRealTimeService 进行异步刷盘,则使用 fileChannel.force(false) 或者 mappedByteBuffer.force() 强制刷盘
16、高可用
如果配置了同步写入 slave,则同步写入slave broker
否则,异步写入 slave
17 ~ 24、ConsumeQueue 数据写入
在 broker 启动的时候,会启动 ConsumerQueue 和 CommitLog 异步校准线程(this.reputMessageService.start())。因为写入消息的时候,只同步/异步写入 commitlog,而 consumer queue 的映射关系当时没有建立,而是靠这个异步线程来对比 CommitLog 和 ConsumeQueue 来写入新的消息映射到 ConsumeQueue。(这样异步更新 ConsumeQueue,又能进一步提升写入消息性能)
具体执行就在 ReputMessageService.run()
19、offset 对比
reputFromOffset 比 commit 数据 offset 小则说明,有映射关系未建立,则需更新 ConsumeQueue
20、从 commit 拉取数据
getData(reputFromOffset)
21、调度构建 ConsumeQueue
CommitLogDispatcherBuildConsumeQueue.dispatch(DispatchRequest request)
22、存入消息位置信息(即 commitLog 映射信息)
23、根据 topic 和 queueId 能唯一定位到一个 ConsumeQueue (PS:我是不是可以在这里找到 下一个30分钟文件)
即找到 ConsumeQueue 对应的文件
24、将 ConsumeQueue 信息写入缓冲区
this.fileChannel.position(currentPos);
this.fileChannel.write(ByteBuffer.wrap(data));
后面线程异步去刷入磁盘
25 ~ 建立索引
doDispatch(dispatchRequest) 是一个列表循环处理,一个是处理 ConsumeQueue,另一个就是构建索引。构建索引是为了按照 MessageKey 查询消息,在创建 Message 的时候可选指定。
下面引用官方文档:
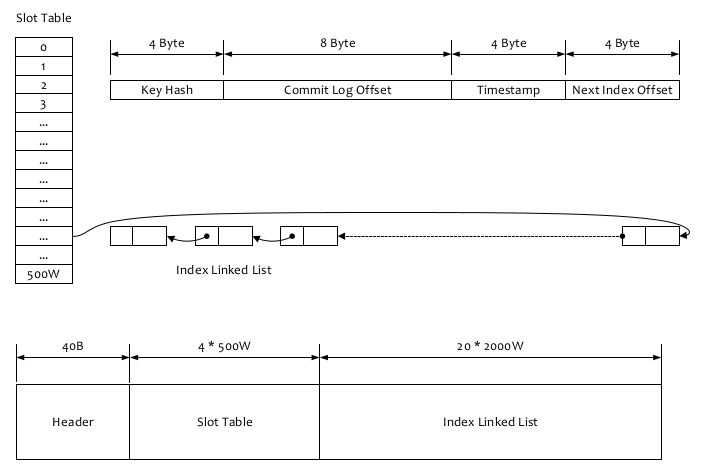
RocketMQ可以为每条消息指定Key,并根据建立高效的消息索引,索引逻辑结果如上图所示(PS:类似 HashMap 的索引),
查询过程如下:
1、根据查询的key的hashcode%slotNum得到具体的槽的位置(slotNum是一个索引文件里面包含的最大槽的数目,例如图中所示slotNum=500W)。
2、根据slotValue(slot位置对应的值)查找到索引项列表的最后一项(倒序排列,slotValue总是指向最新的一个索引项)。
3、遍历索引项列表返回查询时间范围内的结果集(默认一次最大返回的32条记录)
4、Hash冲突;寻找key的slot位置时相当于执行了两次散列函数,一次key的hash,一次key的hash值取模,因此这里存在两次冲突的情况;第一种,key的hash值不同但模数相同,此时查询的时候会在比较一次key的hash值(每个索引项保存了key的hash值),过滤掉hash值不相等的项。第二种,hash值相等但key不等,出于性能的考虑冲突的检测放到客户端处理(key的原始值是存储在消息文件中的,避免对数据文件的解析),客户端比较一次消息体的key是否相同。
5、存储;为了节省空间索引项中存储的时间是时间差值(存储时间-开始时间,开始时间存储在索引文件头中),整个索引文件是定长的,结构也是固定的 。
索引建立过程:
public boolean putKey(final String key, final long phyOffset, final long storeTimestamp) {
if (this.indexHeader.getIndexCount() < this.indexNum) { // 索引最大数量是 indexNum=2000W
int keyHash = indexKeyHashMethod(key); // 第一次散列。
int slotPos = keyHash % this.hashSlotNum; // 第二次散列。 hashSlotNum=500W key具体槽位。参看 1、根据查询的key的hashcode%slotNum得到具体的槽的位置
int absSlotPos = IndexHeader.INDEX_HEADER_SIZE + slotPos * hashSlotSize; // Slot 的位置。INDEX_HEADER_SIZE=40 hashSlotSize=4
FileLock fileLock = null;
try {
// fileLock = this.fileChannel.lock(absSlotPos, hashSlotSize,
// false);
int slotValue = this.mappedByteBuffer.getInt(absSlotPos); // 拿到 slot 中的值
if (slotValue <= invalidIndex || slotValue > this.indexHeader.getIndexCount()) {
slotValue = invalidIndex;
}
long timeDiff = storeTimestamp - this.indexHeader.getBeginTimestamp();
timeDiff = timeDiff / 1000;
if (this.indexHeader.getBeginTimestamp() <= 0) {
timeDiff = 0;
} else if (timeDiff > Integer.MAX_VALUE) {
timeDiff = Integer.MAX_VALUE;
} else if (timeDiff < 0) {
timeDiff = 0;
}
// Index 在索引文件具体位置 indexSize=20
int absIndexPos =
IndexHeader.INDEX_HEADER_SIZE + this.hashSlotNum * hashSlotSize
+ this.indexHeader.getIndexCount() * indexSize;
// 消息数据存放
this.mappedByteBuffer.putInt(absIndexPos, keyHash);
this.mappedByteBuffer.putLong(absIndexPos + 4, phyOffset);
this.mappedByteBuffer.putInt(absIndexPos + 4 + 8, (int) timeDiff);
this.mappedByteBuffer.putInt(absIndexPos + 4 + 8 + 4, slotValue); // 指向前一个节点
// 存入索引。 根据Message 的 Key 找到 absSlotPos和对应的value indexCount,根据 indexCount可以找到 absIndexPos 位置
this.mappedByteBuffer.putInt(absSlotPos, this.indexHeader.getIndexCount());
if (this.indexHeader.getIndexCount() <= 1) {
this.indexHeader.setBeginPhyOffset(phyOffset);
this.indexHeader.setBeginTimestamp(storeTimestamp);
}
this.indexHeader.incHashSlotCount();
this.indexHeader.incIndexCount();
this.indexHeader.setEndPhyOffset(phyOffset);
this.indexHeader.setEndTimestamp(storeTimestamp);
return true;
} catch (Exception e) {
log.error("putKey exception, Key: " + key + " KeyHashCode: " + key.hashCode(), e);
} finally {
if (fileLock != null) {
try {
fileLock.release();
} catch (IOException e) {
log.error("Failed to release the lock", e);
}
}
}
} else {
log.warn("Over index file capacity: index count = " + this.indexHeader.getIndexCount()
+ "; index max num = " + this.indexNum);
}
return false;
}
消息删除:
删除过期 CommitLog(默认超过 72 小时删除)
删除过期 ConsumeQueue(跟 CommitLog offset 对比,commitLog 偏移量大于 CQ 存储的偏移量,说明响应的 commitLog已经被删除了,CQ也就可以删除了)
Broker 重启数据恢复:
如何找到上次刷盘位置?
“checkpoint”此文件会记录刷盘的时间戳,恢复时,根据时间戳来扫描 Commit Log 的存储时间戳,就可以找到从
哪里开始恢复。
如果此文件丢失,则会对 Commit Log 进行全盘扫描恢复,这种情况会耗时较长。
broker 启动的时候
// BrokerController.java
messageStore.load()
// DefaultMessageStore.java
public boolean load() {
boolean result = true;
try {
boolean lastExitOK = !this.isTempFileExist();
log.info("last shutdown {}", lastExitOK ? "normally" : "abnormally");
if (null != scheduleMessageService) {
result = result && this.scheduleMessageService.load(); // 定时消息加载
}
// load Commit Log 加载 CommitLog 此时只是把文件内存加载到 MappedFile,具体wrotePosition、committedPosition 等只是全部设为 fileSize,还未恢复
result = result && this.commitLog.load();
// load Consume Queue 加载 ConsumeQueue
result = result && this.loadConsumeQueue();
if (result) {
this.storeCheckpoint =
new StoreCheckpoint(StorePathConfigHelper.getStoreCheckpoint(this.messageStoreConfig.getStorePathRootDir()));
// 加载索引
this.indexService.load(lastExitOK);
// 恢复
this.recover(lastExitOK);
log.info("load over, and the max phy offset = {}", this.getMaxPhyOffset());
}
} catch (Exception e) {
log.error("load exception", e);
result = false;
}
if (!result) {
this.allocateMappedFileService.shutdown();
}
return result;
}
// 恢复
private void recover(final boolean lastExitOK) {
// 遍历 ConsumeQueue 的消息,来恢复 MappedFile 的 wrotePosition、committedPosition、flushedPosition,
// mappedFileQueue 的 flushedWhere、committedWhere,当然遍历完也知道了 maxPhysicOffset,即commitLog 中最大的写入位置。
// flushedWhere、committedWhere 和 wrotePosition、committedPosition、flushedPosition 正常情况下就都是相同的,处理到具体的什么位置,即文件名(带有文件偏移信息) + 文件内的偏移。
this.recoverConsumeQueue();
if (lastExitOK) {
this.commitLog.recoverNormally();
} else {
// 根目录下有 abort 文件,说明未正常关闭 broker,所以走这里恢复。
// 基本上和恢复 ConsumeQueue 差不多,就是如果有 checkpoint 文件的时间戳找到对应要恢复的文件(其实就是最后一个文件,因为是顺序写入的),会快点,也是遍历相应文件找到写到什么位置。
// 恢复 flushedWhere、committedWhere 和 wrotePosition、committedPosition、flushedPosition。
this.commitLog.recoverAbnormally();
}
this.recoverTopicQueueTable();
}
提示:
BrokerId = 0 表明 broker 为 master。其他为 slaver。master 可以读/写,而 slaver 只能读。
没有用zk选主,所以 broker 主从不会切换,启动了就固定了。