深入浅出数据分析(一)——MySQL+EXCEL+R统计问卷调查
深入浅出数据分析(一)——MySQL+EXCEL+R统计问卷调查
本篇文章面向对象为小白,大牛扫一眼或看看目录就懂了。
目录
- 深入浅出数据分析一MySQLEXCELR统计问卷调查
- 目录
- 确定问题
- 分解
- 分解问题
- 分解数据
- EXCEL刀光霍霍
- 把数据库内容提取到EXCEL
- 拆分关键内容
- 数据处理
- R的正则匹配
- EXCEL数据处理
- 结果
- 总结
先说个人背景:本人于2014年暑假参与校就业信息网的开发,其中一个工作就是开发问卷调查系统,用的是PHP+MySQL(一种主流的后台开发语言和数据库)。
大三学期期末,BOSS紧急给了两个任务:
- 未填写调查问卷的同学的名单
- 学生求职的平均支出和平均工资
第一个任务还好,花点时间查w3c和纠错得到结果(来看EXCEL的同学可以略过):
SELECT DISTINCT `stu_info`.id AS `stu_id`, stu_info.`name`, `endyear`, college.`name` FROM `stu_info`, `quiz_operation`, `college`
WHERE NOT EXISTS (SELECT * FROM quiz_operation WHERE stu_info.id = quiz_operation.stu_id)
AND stu_info.colid = college.`colid` AND endyear = 2015;直接得出结果发给BOSS。
第二个任务,也就是求得学生求职的平均支出和平均工资,才是我们本篇文章的重点——数据分析相关。
确定问题
未明确明确自己的问题或目标就进行数据分析,如同为定下目的地就上路旅行一样。 —— 《深入浅出数据分析》
本次目标很明确:求得学生求职的平均支出和平均工资。
但是,关于「学生求职的平均支出和平均工资」的问题是单独的两个填空题,如下图。(问卷并不合理,合理就不用我上了,有点挑战)

要处理数据,我们至少有以下几个方面要考虑:
- 可行域范围的确定:平均支出和平均工资多大是合理的;
- 字符识别:元,块,RMB,钱,k,多个数字等等各种情况;
- 筛除不可靠数据:比如学生乱填写的数据。
其中,第二点和第三点是难点。当然,大部分内容会在「分解」中详细叙述。
分解
分解问题
分解问题意在将大问题划分为小问题,通过回答大问题分解出来的小问题,就可找到大问题的答案。
显然,在这里我们不需要这么做。在调查问卷中,有两个单独的关于「学生求职的平均支出和平均工资」的问题,我们要做的就是分解数据。
分解数据
由于之前问卷设计存在纰漏,关于「学生求职的平均支出和平均工资」的问题是一个填空题。
因此分解数据并不简单,在调查问卷中,关于「学生求职的平均支出」的问题是一个填空题。而且当初设计用户填完后上传到数据库的内容为

可见,我是用一对分隔符“\/”将用户填写的每个选项分隔开。其中,quiz_id = 7的数据中,被分隔符“\/”划分开的第四个选项,就是关于「学生求职的平均支出」的问题。
顺便一提,第五个选项是多选题。
接下来我们要做的是选定我们分解数据的工具。当前情境有以下选项:
- PHP+MySQL
- EXCEL
- R
在「确定问题」中我们提到过,「识别字符」是难点,而EXCEL中并没有正则表达式,但EXCEL比起其他两个的优点是可视编辑,容易并且灵活。然而,EXCEL的正则表达式使用起来比较困难(需要VBA),因此,我们用R来做「识别字符」的工作。
EXCEL刀光霍霍
Excel就像一把天山寒铁淬炼而成的杀猪刀,本身已经很厉害,但具体有多厉害取决于用它的人。 —— 雨声敲敲,业余独立游戏人,知乎用户
首先,先确定下我们接下来要做的工作步骤:
- 把数据库内容提取到EXCEL
- 拆分关键内容
把数据库内容提取到EXCEL
SQLyog自带导出功能,
导出配置如图,要注意的是将文本大小改为一个较大的值,防止读不全数据。

点出「导出」即可。
拆分关键内容
EXCEL有一个「分列」工具,可以让以分隔符组成的某组数据域以分隔符为单位化分开,划分开的结果分别对应到各个列。我们选中C列(content),点击「数据」选项卡下的「分列」按钮。



但是,我们会发现分隔符号只能为单个字符,而不能用“\/”的字符串,所以,我们需要返回过去先来做一遍全文的替换,将“\/”全部替换为“/”。
当然,为了后续处理更方便,我们还需要将一些“k”,“w”替换成多个零。

全部替换之后,再按之前的操作,把目标区域(即新的数据存放在哪里,如果默认的话EXCEL会覆盖你的原有数据)更新为右一列。

删除掉不需要的列之后,就能看到我们期待看到的一幕啦~

EXCEL虽然功能强大,但替换功能并不支持通配符[]和%(EXCEL中支持的通配符有*和?,但EXCEL不支持%和[]。而WORD中支持上述四种。),因此,为了完成字符识别替换的功能,我们将使用更加强大的统计工具——R语言。
数据处理
R的正则匹配
在这里,我们将用R语言来匹配我们需要的信息,删除不要的信息。
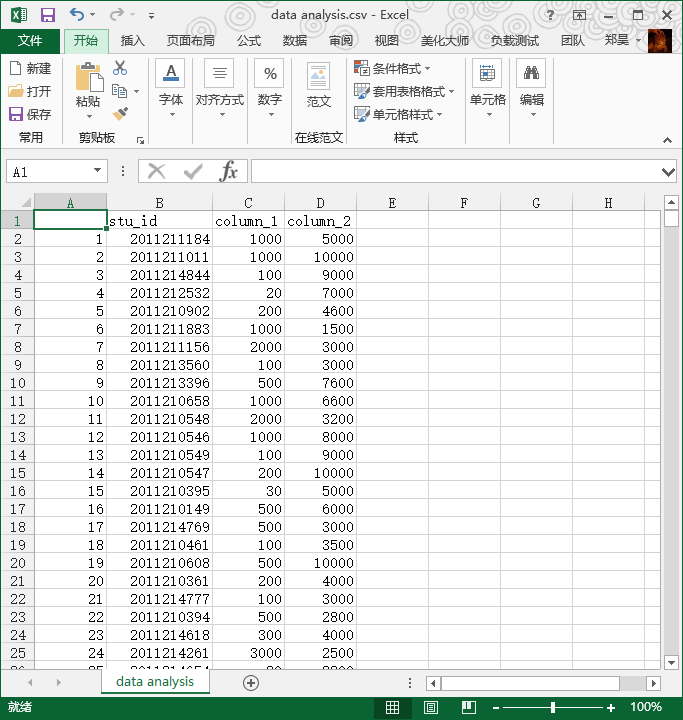
首先,我们新建一份表格,将需要统计的数据转移到这份中,B列和C列分别命名为column_1和column_2,另存为data_analysis.csv文档。
右键查看该.csv文件的保存信息。
启动R,复制.csv文件的保存位置,将“\”更改为“/”,在RGui内输入以下代码:
> da <- read.csv("C:/Users/昊/Documents/data_analysis.csv")
> head(da)上述每行代码的意思是:
- 读取位于文档的
data_analysis.csv文件,并将文件的内容赋值给da(da就成为了我们在R环境里的变量了); - 读取变量
da的开头部分信息,确认一下有备无患。
因此,我们在RGui内就可以看到,
> da <- read.csv("C:/Users/昊/Documents/data_analysis.csv")
> head(da)
stu_id column_1 column_2
1 2011211184 1000 5000
2 2011211011 1000 10000
3 2011214844 100元以内 实习期9000
4 2011212532 20 7000
5 2011210902 200 4600
6 2011211883 1000 1500
> 非常轻松~
接下来,我们利用sub()函数和正则表达式来去除文字,保留数字。
代码和结果直接给出:
> New_column_1 <- sub("[^0-9]","",da$column_1)
> head(New_column_1)
[1] "1000" "1000" "100以内" "20" "200" "1000"
> 正则表达式[^0-9]匹配的是非数字字符,sub()函数找到非数字字符后用“”(空)来替代。
我们可以看到”100元以内”转成了”100以内”,“元”这个字符被去除了,但并不是所有的非数字文本被去除,所以需要我们循环这条代码:
> New_column_1 <- sub("[^0-9]","",New_column_1)那要循环多少次呢?
我们用EXCEL打开data_analysis.csv文件,给D2赋值=LEN(D2),并复制,检测所有B列和C列,再在底部用MAX()函数取这些值的最大数,分别是32和18。所以,我们对column_1, column_2分别做32次和18次循环替代是合理的(并非最优)。
循环代码如下:
i <- 1
while (i <= 32) {
New_column_1 <- sub("[^0-9]","",New_column_1)
New_column_2 <- sub("[^0-9]","",New_column_2)
i <- i+1
}循环结束之后,输入赋值保存的代码:
> da$column_1 <- NULL
> da$column_2 <- NULL
> da["column_1"] <- New_column_1
> da["column_2"] <- New_column_2
> write.csv(da, file="data analysis.csv")
> 见证奇迹的时刻:
EXCEL数据处理
在本章中,我们将会筛选排除无用信息。
上文说过,要处理数据,我们至少有以下几个方面要考虑:
- 可行域范围的确定:平均支出和平均工资多大是合理的;
- 字符识别:元,块,RMB,钱,k,多个数字等等各种情况;
- 筛除不可靠数据:比如学生乱填写的数据。
字符识别已经在上一章处理完成。这一章我们要做的就是可行域范围的确定和筛除不可靠数据。
打开我们原始数据SQL_EXCEL.xml,获取多选题的填空内容,复制到新生成的data analysis.csv文件中。
首先要做的是,删除column_1和column_2中的空白信息。
其次就是排查不可靠数据,将column_1降序排列,如下图。2到11列,用户应该是填写了两份数字造成此处4000和5000连接,可以手动修改或者删除。
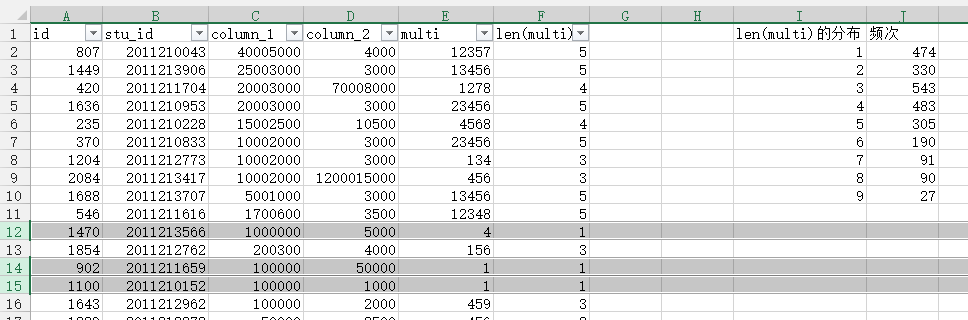
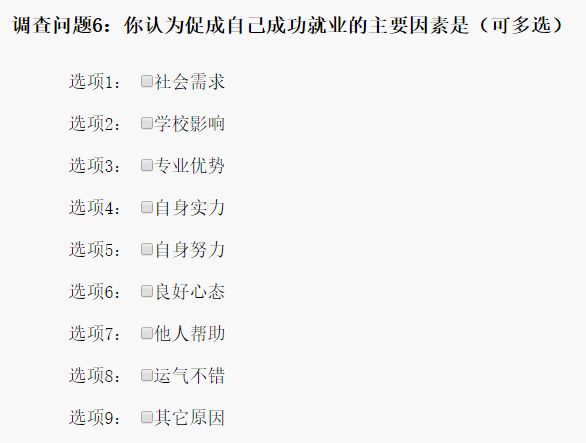
此外,我加入多选题来进行主观判断。多选题内容如下,显然不会只是单个因素促进成功就业。多选题填空的分布,只选择一项的同学占了不少数。再结合上column_1和column_2(比如工资是连数11111,工资收入极低,支出1000工资1000多选题只填一个等情况)进行判断。
同样操作对column 2进行。出现为数不少的上述问题。
我们分别让H2=LEFT(D2,4)和I2=MID(D2,5,10)并复制到多行。再获取两列的平均值。
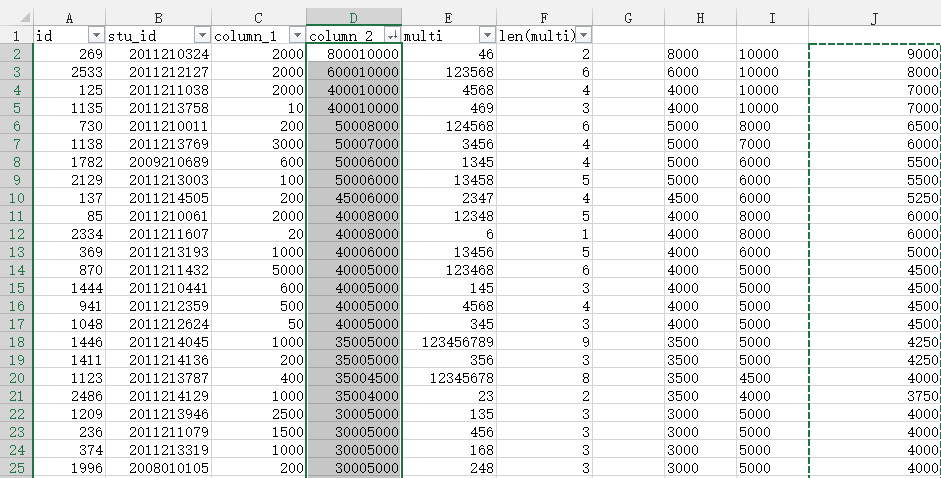
最后复制,粘贴-值。
当然,如果某位同学填的是日薪或者年薪,我没办法处理。
排除完异常值后,我们还要排除合理区间范围外的值。在这次实例中,我把支出限定在[0,50000]内,工资收入限定在[1000,50000]内为合理,不合理的值均删除。不合理的几条数据对上千条数据的平均值影响微乎其微。
结果
人均找工作支出:1402元。
人均毕业工资收入:4183元。
我们还可以看下散点图,R语言代码:
> plot(da$column_1, da$column_2)横轴是支出,纵轴是收入:

有兴趣的同学还可以看下模型,
如图建立线性模型:
> myLm <- lm(column_1~column_2, data=da)
> summary(myLm)
Call:
lm(formula = column_1 ~ column_2, data = da)
Residuals:
Min 1Q Median 3Q Max
-1662 -1084 -418 582 32621
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.321e+03 1.028e+02 12.842 <2e-16 ***
column_2 1.955e-02 2.227e-02 0.878 0.38
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2130 on 2394 degrees of freedom
Multiple R-squared: 0.0003218, Adjusted R-squared: -9.574e-05
F-statistic: 0.7707 on 1 and 2394 DF, p-value: 0.3801
> cor(da$column_1, da$column_2)
[1] 0.01793967
>
学过概率论我们都知道,相关系数的绝对值越大越好(0到1之间),而这里相关系数只有0.018,显然我们这个模型(支出和收入的关系)没有任何鸟用,毕竟个人觉得问卷调查问题设置得并不好。
给BOSS发报告去。
总结
在此还是总结下本篇文章用到的知识。
EXCEL
- 分列
- 替换,通配符
- LEN(),COUNTIF(),LEFT(),MID()
- 筛选
R
- read.csv()和write.csv()
- sub()
- 正则表达式
- 循环
- lm(),cor()
SQL
- 基础语法
- DISTINCT,EXISTS
- 导出配置