【检测】Prime Sample Attention in Object Detection
Prime Sample Attention in Object Detection
作者:CUHK SenseTime Joint Lab, NTU
在目标检测中的一个普遍认知就是应该平等的对待每个sample和目标。这篇文章研究了不同的样本对于最终结果的影响。作者认为在每个minibatch中的样本既不是独立的也不是同样重要的,所以一个平均的结果并不能意味是一个更高的mAP。作者提出了Prime Sample的概念并且提出了PISA的结果,主要关注这些样本的训练过程,实验证明关注prime sample而不是hard sample对于训练来说更加有效。在MSCOCO数据集上,PISA表现的比random sampling和hard mining超过了1个百分点。
现在的目标检测办法主要用的是region-based 方法。因此region sample的选择对于检测结果来说是很重要的,然而很多的sample位于图像的背景区域,音系简单的选择所有sample或者随意选择一些是一种不合理的办法。
已经有一些研究表明主要关注一些困难的sample是一个比较有效的办法。代表的有OHEM(?)和Focal Loss。OHEM主要选择hard samples比如说有着高的loss值。Focal Loss是给loss function换了一种形式来强调difficult samples。
然而,什么才是最重要的sample呢?
这项研究提出了2个需要被重点考虑的方面:
- Sample不应该是独立的或者是相同重要的。本文的研究西安市,应该重点关注了那些和groundtruth有着高iou的samples。
- 分类和定位是相关联的。尤其是,被很好定位的samples需要以高的confidences来分类(?)
文章重点:
- 提出了PISA
- 定义了IoU-HLR
- 加入了classification-aware regression loss
Related Work:
Improvement of NMS with localization confidence
IoU-Net并不是完全用分类结果来做NMS,定位结果也需要。 除了传统算法中的classification和regression分支,它引入了一个其他的分支来预测sample的IoU。并且用这个预测的IoU(localization confident) 来排序所有的sample。本文和IoU-Net的主要不同有:
本文是联系两个分支而不是开发出新一个。
本文的目标不是提升NMS。 而是调查sample的重要性并且重点关注prime samples。
Sampling strategies in object detection
在目标检测中最广泛被采用的sampling scheme是random sampling。因为负样本总是比正样本多很多,所以正样本负样本见一个固定的比例可能会被设置。(?)
还有的想法是选择有着高的loss值的hard samples,但是,hard mining的目的是增加classifier的的表现能力而不是探索检测和分类的差别。
Prime Samples
mAP:
mAP的工作方式反映了对于一个目标检测器来说哪个sample更重要。
所有的bounding boxes中IoU最高的那个被认为是最重要的,并且直接影响了recall。
在对于不同物体的全部最高的IoU的bounding box中,有着最高IoU的那个更加重要
IoU Hierarchical Local Rank (IoU-HLR):
本文提出了IoU-HLR来排序在一个minibatch中sample的重要性, IoU-HLR是基于最终的sample的定位计算的,而不是regression前的bounding box的坐标,因为mAP是基于regressed sample的位置衡量的。
如下图所示,首先将所有的sample根据他们最近的objects分成不同组,然后在每个组中,根据他们的IoU降序排序得到了LoU Local Rank(IoU-LR)。然后所有的top1 LoU-LR被选出来了,然后是top2,3。。。等等。这两步的分类结果会形成在一个batch中所有样本的一个线性的命令,所以称它IoU-HLR。

Learn Detectors via Prime Sample Attention
如果我们只有top IoU-HLR samples进行训练,就像OHEM做的那样,mAP就会下降的很厉害因为大多数prime sample都是很容易训练的所以不能提供足够的梯度来优化classifier(为什么只是classifier?)
所以本文提出了Prime Sample Attention,一个简单有效并且可以更关注于prime samples。 PISA包括2个部分,Importancebased Sample Reweighting (ISR) and Classification Aware
Regression Loss (CARL)。 在PISA的作用下,训练进程更加偏向于prime samples而被平均对待的samples。 首先,prime sample的loss weight比其他的大,所以在这些sample上,classifier往往可以预测出更好的分数(为什么是classifier?)。第二,因为classior和regressor是通过共同的目标进行学习的,所以prime samples的分数和不重要的那些比会增加(??)。
Importance-based Sample Reweighting
在被给相同的classifier的情况下,performance的分布总是于训练样本的分布相匹配的。如果一些sample在训练数据中出现的更频繁,那么在这些sample的分类正确率就会更好(为什么是分类正确率?)hard sampling和soft sampling时改变训练数据分布的两种不同方式。Hard sampling是从所有的候选中选择一些samples来训练一个模型,然而,soft sampling是给所有的samples分配不同的权重(?)。hard可以被看作是soft的一种特殊形式,每个sample都被分配一个是0或1的loss weight(?)。
这篇文章提出了一种soft Sampling 的方法—— Importance-based Sample Reweighting (ISR), 它根据重要程度给samples分配了不同的loss weights
用线性方程可以将r_i转换为u_i,如下所示:u_i代表了class j的第i个sample的重要性值。
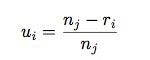
u_i 和w_i存在着一个简单的递增的关系:
![]()
之后,cross entropy classification loss可以被改写为:
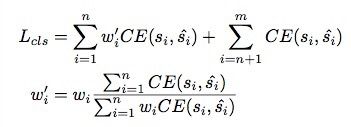
n和m分别是正样本和全部样本的总量。注意到简单的增加loss weights将会改变loss的全部值和正样本负样本之间的比例,所以我们将w_i归一化到 w_i’为了保证全部正样本的loss不变。(w_i为什么不能加到regression loss中?)
Classification-Aware Regression Loss
除了re-weight classification loss 来重点关注prime samples,作者还提出了一个联合优化两个分支通过Classification-Aware Regression Loss (CARL)。CARL可以增加prime sample的分数同时降低其他的分数。Regression的质量确定了sample的重要性,并且我们希望classifier可以输出对于重要sample的更高的分数。两个分支的优化应该是相关的而不是独立的。
解决方法是让regression loss关注到classification score以至于梯度可以从regression反传到classification
p_i代表了预测到相关class的概率,
实验:
