Spark SQL快速入门(进阶)
教程目录
- 0x00 教程内容
- 0x01 基础环境准备
-
-
-
-
- 1. 启动 Spark-Shell
- 2. 准备数据
- 3. 生成DataFrame
-
-
-
- 0x02 Spark SQL 基础编程操作
-
-
-
-
- 1. show()
- 2. printSchema()
- 3. 获取指定字段的统计信息
- 4. 获取数据操作
- 5. 查询操作
- 6. 过滤操作
- 7. 排序操作
- 8. 统计操作
-
-
-
- 0x03 执行 SQL 语句
- 0x04 保存 DataFrame 为其他格式
-
-
-
-
- 1. 默认为Parquet格式
- 2. 保存为其他格式
- 3. 保存模式
-
-
-
- 0x05 支持多种数据源
-
-
-
-
- 1. 通用 load、save 函数
- 2. 指定其他格式数据源
-
-
-
- 0xFF 总结
0x00 教程内容
- 基础环境准备
- Spark SQL 基础编程操作
- 执行 SQL 语句
- 保存 DataFrame 为其他格式
- 支持多种数据源
本文的前置教程课程为: Spark SQL快速入门(基础)
0x01 基础环境准备
1. 启动 Spark-Shell
spark-shell
2. 准备数据
vi /home/hadoop-sny/datas/teacher.json
{
"name":"shaonaiyi", "age":"30", "height":198}
{
"name":"shaonaier", "age":"28", "height":174}
{
"name":"shaonaisan", "age":"25", "height":178}
{
"name":"shaonaisi", "age":"21", "height":183}
{
"name":"shaonaiwu", "age":"32", "height":165}
3. 生成DataFrame
在 spark-shell 中输入如下代码:
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder().appName("PersonApp").getOrCreate()
import spark.implicits._
val teacherDF = spark.read.json("/home/hadoop-sny/datas/teacher.json")
0x02 Spark SQL 基础编程操作
1. show()
teacherDF.show()
show():显示所有的数据
show(n) :显示前n条数据
show(true): 字段最多显示20个字符,默认为true
show(false): 取消最多显示20个字符的限制
show(n, true):显示前n条并最多显示20个字符

字段最多显示20个字符的意思是,比如name字段,名称太长,超过了20个字符的话,会显示成 ...,如果不超过则不会。
2. printSchema()
打印数据表的 Schema信息(结构):
teacherDF.printSchema()

3. 获取指定字段的统计信息
teacherDF.describe("height").show() //其中,Count:记录条数,Mean:平均值,Stddev:样本标准差,Min:最小值,Max:最大值

4. 获取数据操作
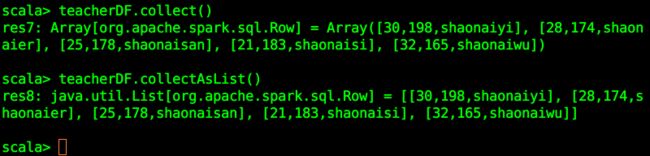
collect():获取所有数据到数组
collectAsList():获取所有数据到List。
teacherDF.collect()
teacherDF.collectAsList()
first(): 获取第一行记录;
head(n):获取前 n 行记录;
take(n): 获取前 n 行数据;
takeAsList(n): 获取前 n 行数据,并以 List 的形式展示。
PS:head与take的结果其实是一样的。

5. 查询操作
查询名称为 shaonaiyi 或 年龄是30岁的数据:
teacherDF.where("name = 'shaonaiyi' or age = 28").show()

展示所有的老师名:
teacherDF.select("name").show()

展示所有的老师名及身高:
teacherDF.select("name", "height").show()

6. 过滤操作
展示所有年龄为30岁的老师,打印老师的名称与身高:
teacherDF.filter(teacherDF("age").equalTo("30")).select("name", "height").show()

limit(n)方法获取指定的 DataFrame 的前 n 行记录,得到的是一个新转化生成的 DataFrame 对象。
teacherDF.limit(3).show()

7. 排序操作
排序操作有两种方法:orderBy()和sort();
都是按指定字段排序,默认为升序。
desc:降序
asc :升序
teacherDF.orderBy(teacherDF("height").desc).show(false)

8. 统计操作
groupBy()和count()操作
计算所有年龄和年龄的数量:
teacherDF.groupBy("age").count().show()

0x03 执行 SQL 语句
SparkSession 提供了 SparkSession.sql() 方法,SQL 语句可以直接作为字符串传入 sql()方法中,具体可以学习相关的 SQL 知识。
首先需要将 DataFrame 注册为临时表才可以在该表上执行 SQL 语句:
teacherDF.createOrReplaceTempView("teacher")
查询身高在 170-190 之间的老师:
val sqlDF = spark.sql("SELECT name,height FROM teacher WHERE height >= 170 and height <= 190")
sqlDF.show()

如果在同一个应用的不同 session 会话中需要重用一个临时表,可以把它注册成为全局临时表,全局临时表会一直存在并在所有会话中共享直到应用程序终止。
// 注册成为全局临时表
teacherDF.createGlobalTempView("GlobalTeacher")
// newSession()返回一个新的spark对象,引用全局临时表需要 global_temp 标识
spark.newSession().sql("SELECT name,height FROM global_temp.GlobalTeacher WHERE height >= 170 and height <= 190").show()

如果重复创建表的话会报错,提示表已经存在,此时就可以使用:createOrReplaceGlobalTempView():
teacherDF.createOrReplaceGlobalTempView("GlobalTeacher")
0x04 保存 DataFrame 为其他格式
1. 默认为Parquet格式
parquet 是 Spark SQL 读取的默认数据文件格式,我们把先前从 JSON 中读取的 DataFrame 保存为这种格式,只保存名称和身高两项数据:
teacherDF.select("name", "height").write.format("parquet").save("/home/hadoop-sny/datas/teacher.parquet")
/home/hadoop-sny/datas/teacher.parquet 文件夹被会被创建并存入名称和身高。另开一个终端,可以查看文件夹下的内容:

2. 保存为其他格式
此外,你也可以保存成一份json文件:
teacherDF.select("name", "height").write.format("json").save("/home/hadoop-sny/datas/teacher-test.json")
查看内容,如图:

3. 保存模式
保存操作可以选择使用多种存储模式: SaveMode , 它可以指定如何处理现有数据。比如当执行 Overwrite 时, 在写入新数据之前,原有的数据将被删除。
| Scala/Java | Any Language | Meaning |
|---|---|---|
| SaveMode.ErrorIfExists (default) | “error” (default) | 将 DataFrame 保存到数据源时, 如果数据已经存在, 则会抛出异常 |
| SaveMode.Append | “append” | 将 DataFrame 保存到数据源时, 如果 数据/表 已存在, 则 DataFrame 的内容将被附加到现有数据中 |
| SaveMode.Overwrite | “overwrite” | 覆盖模式意味着将 DataFrame 保存到 数据源 时, 如果 数据表已经存在, 则预期 DataFrame 的内容将覆盖现有数据 |
| SaveMode.Ignore | “ignore” | 忽略模式意味着当将 DataFrame 保存到 数据源 时, 如果数据已经存在, 则保存操作预期不会保存 DataFrame 的内容, 并且不更改现有数据。这与 SQL 中的 CREATE TABLE IF NOT EXISTS 类似 |
比如:使用overwrite方式以parquet形式写出去:
teacherDF.select("name", "height").write.format("json").mode("overwrite").save("/home/hadoop-sny/datas/teacher-test.json")

退出原本的目录,重新进入查看一下文件,生成的时间变了,因为重新生成了文件,并且覆盖了以前生成的文件,其他的模式也是类似的,此处不再反复截图。
0x05 支持多种数据源
1. 通用 load、save 函数
Spark SQL的默认数据源格式为 parquet 格式。当文件是 parquet 格式时,Spark SQL 可以直接在该文件上执行查询操作。
代码示例如下:
val usersDF = spark.read.load("路径/users.parquet")
usersDF.select("name", "age").write.save("namesAndAge.parquet")
2. 指定其他格式数据源
当数据源不是 parquet 文件却是内置格式的时候,使用指定简称(json, jdbc, orc, libsvm, csv, text)即可。同时还可以对 DataFrame 进行类型转换。
代码示例如下:
val usersDF = spark.read.format("json").load("路径/users.json")
usersDF.select("name", "age").write.format("parquet").save("namesAndAges.parquet")
0xFF 总结
- 本文的前置教程课程为: Spark SQL快速入门(基础),关于Spark SQL的操作还有很多知识,此处仅仅是入门教程,有机会再写相应的教程。
- 关于RDD、DataFrame、DataSet的互相转换是非常重要的知识点,请留意我的博客,点赞、评论、关注,有时间分享给大家,谢谢!
作者简介:邵奈一
全栈工程师、市场洞察者、专栏编辑
| 公众号 | 微信 | 微博 | CSDN | 简书 |
福利:
邵奈一的技术博客导航
邵奈一原创不易,如转载请标明出处,教育是一生的事业。