- 谈到 SQL 的开窗函数,要说到HIVE了,因为这个是HIVE支持的特性,但是在Spark SQL中支持HIVE 的。那么让我们看一看开窗函数是什么吧。
- 什么是开窗函数呢 ?
- 开窗函数也叫分析函数,有两类:一类是聚合开窗函数,一类是排序开窗函数。
- 开窗函数的调用格式为: 函数名(列名) over(partition by 列名 order by 列名)
- 如果你没有接触过开窗函数上面这个格式你也许会有些疑惑,但你只要了解一些聚合函数,那么理解开窗函数就非常容易了,我们知道聚合函数对一组值进行计算并返回单一的值,如sum(),count(),max(),min(),avg()等,这些函数常与group by 语句连用。但是一组数据只返回一组指是不能满足需求的,如我们常想知道的各个地区的第一名是谁? 各个班级的前几名是谁?这个时候需要每一组返回多个值。 用开窗函数解决就非常方便。
- 首先我们提一个需求。下面是一张班级表 其中name为学生姓名,class 为班级班级,score 为成绩,那么我们提出一个需求:得出每个班级内成绩最高的学生信息。表名为 A。
- 我们先使用传统的方法进行查找,但是需要创建临时表才可以所以性能也不够好,那么我们下面使用Spark SQL 中的开窗函数进行优化/
select a.name, b.class, b.max from A a
(select name,class,max(score) max from A group by class ) b
where a.socre = b.score
- 开窗函数 (rank()、dense_rank()、row_number())
- 思想:简单点就就在你查询的结果上,直接多出来一个列(可以是聚合值或者是排序号,本题就是排序号)。
- 先把sql 写出来然后在在Spark SQL 中实现
- 先开窗
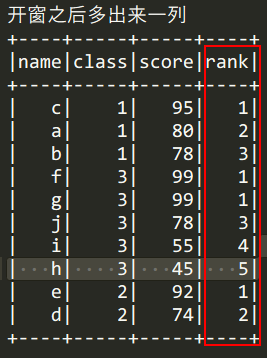
select name,class,score ,rank() over(partition by class order by sorce)
- 结果为下图:如果多出来的一列就是我们开窗函数要做到的效果,那么接下来在找到班级的分数最高的就太容易了
- 只需要加上一个查询条件 就可以拿出想要的了。
select * from
(select name,class,score ,rank() over(partition by class order by sorce)) as t
where t.rank = 1
object OverFunction extends App {
val sparkConf = new SparkConf().setAppName("over").setMaster("local[*]")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
import spark.implicits._
println("//*************** 原始的班级表 ****************//")
val scoreDF = spark.sparkContext.makeRDD(Array( Score("a", 1, 80),
Score("b", 1, 78),
Score("c", 1, 95),
Score("d", 2, 74),
Score("e", 2, 92),
Score("f", 3, 99),
Score("g", 3, 99),
Score("h", 3, 45),
Score("i", 3, 55),
Score("j", 3, 78))).toDF("name","class","score")
scoreDF.createOrReplaceTempView("score")
scoreDF.show()
println("//*************** 求每个班最高成绩学生的信息 ***************/")
println(" /******* 开窗函数的表 ********/")
spark.sql("select name,class,score, rank() over(partition by class order by score desc) rank from score").show()
println(" /******* 计算结果的表 *******")
spark.sql("select * from " +
"( select name,class,score,rank() over(partition by class order by score desc) rank from score) " +
"as t " +
"where t.rank=1").show()
//spark.sql("select name,class,score,row_number() over(partition by class order by score desc) rank from score").show()
println("/************** 求每个班最高成绩学生的信息(groupBY) ***************/")
spark.sql("select class, max(score) max from score group by class").show()
spark.sql("select a.name, b.class, b.max from score a, " +
"(select class, max(score) max from score group by class) as b " +
"where a.score = b.max").show()
spark.stop()
}
- 常用的函数
- row_number()没有重复值的排序(记录相等也是不重复的),可以进行分页使用
- rank() 跳跃排序,有两个第二名时后边跟着的是第四名
- dense_rank() 连续排序,有两个第二名时仍然跟着第三名