语义分割发展总结(Development of Image Segmentation)
语义分割发展
2019/08/24 整理
1. 传统方法
在深度学习应用到计算机视觉领域之前,研究人员一般使用纹理基元森林(TextonForest) 或是随机森林(Random Forest) 方法来构建用于语义分割的分类器。
纹理基元森林(TextonForest): 基于texton的纹理分析方法将图像表达为纹理图像的直方图分布,纹理字典可以是一组滤波器响应,也可以是邻域亮度,基于邻域亮度的texton分类包含四个部分:texton字典构建,texton直方图生成,分类器训练和分类器结果预测。使用训练图像的texton直方图训练KNN或支持向量机分类器,将测试图像的texton直方图输入到训练好的分类器,预测出测试图像的类别。缺点: 邻域亮度对图像旋转和光照变化较敏感,不同的邻域大小具有不同的分类性能,且对不同的图像而言,最优的邻域大小并不相同。
随机森林: 基于随机森林的图像语义分割的算法,从训练库图像中随机地采样出固定大小的窗口作为特征,通过窗口中随机的选取两个像素点的像素值对比,将这些特征量化为数值向量,这样的向量集合被用于训练随机森林分类器.在测试阶段,以每个像素点作为中心,提取一个窗口,在这个窗口中提取一个向量集合,利用随机森林的叶子节点对这些向量分别进行投票,根据投票结果选举产生该像素点最可能的归属类别.该算法直接利用了图像低级的像素信息,而不是去计算复杂的滤波器组响应或局部描述子,这可大幅提高了算法训练和测试速度
2.完全卷积网络(Fully Convolutional Networks)
Fully Convolutional Networks for Semantic Segmentation
2014年,加州大学伯克利分校的Long等人提出的完全卷积网络(Fully Convolutional Networks),推广了原有的CNN结构,在不带有全连接层的情况下能进行密集预测。这种结构的提出使得分割图谱可以生成任意大小的图像,且与图像块分类方法相比,也提高了处理速度。在后来,几乎所有关于语义分割的最新研究都采用了这种结构。
文章的主要创新点:
- 将端到端的卷积网络推广到语义分割中;
- 重新将预训练好的Imagenet网络用于分割问题中;
- 使用逆卷积层(ConvTranspose2d)进行上采样;
- 提出了跳跃连接来改善上采样的粗糙程度
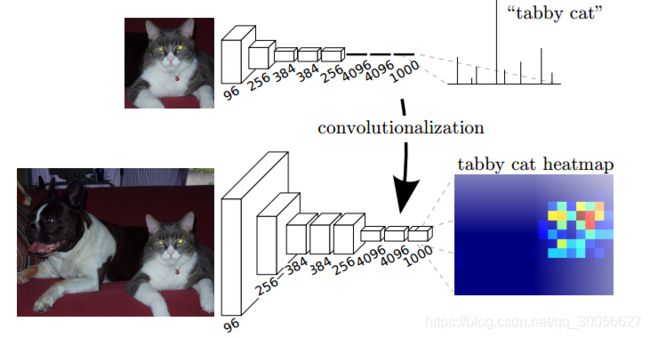
本文的关键在于:分类网络中的全连接层可以看作是使用卷积核遍历整个输入区域的卷积操作。这相当于在重叠的输入图像块上评估原始的分类网络,但是与先前相比计算效率更高,因为在图像块重叠区域,共享计算结果。
在将VGG等预训练网络模型的全连接层卷积化之后,由于CNN网络中的池化操作,得到的特征图谱仍需进行上采样。
反卷积层在进行上采样时,不是使用简单的双线性插值,而是通过学习实现插值操作。此网络层也被称为上卷积、完全卷积、转置卷积、逆卷积或是分形卷积。
然而,由于在池化操作中丢失部分信息,使得即使加上反卷积层的上采样操作也会产生粗糙的分割图。因此,本文还从高分辨率特性图谱中引入了跳跃连接方式。
创新点逆卷积和跳跃连接的部分pytorch代码 如下:
class FCNs(nn.Module):
def __init__(self, pretrained_net, n_class):
super().__init__()
self.n_class = n_class
self.pretrained_net = pretrained_net # 载入VGG16的不包含全连接层的网络模型
self.relu = nn.ReLU(inplace=True)
self.deconv1 = nn.ConvTranspose2d(512, 512, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1) # 逆卷积
self.bn1 = nn.BatchNorm2d(512) # BN层
self.deconv2 = nn.ConvTranspose2d(512, 256, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn2 = nn.BatchNorm2d(256)
self.deconv3 = nn.ConvTranspose2d(256, 128, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn3 = nn.BatchNorm2d(128)
self.deconv4 = nn.ConvTranspose2d(128, 64, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn4 = nn.BatchNorm2d(64)
self.deconv5 = nn.ConvTranspose2d(64, 32, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn5 = nn.BatchNorm2d(32)
self.classifier = nn.Conv2d(32, n_class, kernel_size=1)
def forward(self, x):
output = self.pretrained_net(x) # vgg16模型的输出
x5 = output['x5']
x4 = output['x4']
x3 = output['x3']
x2 = output['x2']
x1 = output['x1']
score = self.bn1(self.relu(self.deconv1(x5)))
score = score + x4
score = self.bn2(self.relu(self.deconv2(score))) # 向前逆卷积 ,或者叫上采样
score = score + x3
score = self.bn3(self.relu(self.deconv3(score)))
score = score + x2
score = self.bn4(self.relu(self.deconv4(score)))
score = score + x1
score = self.bn5(self.relu(self.deconv5(score)))
score = self.classifier(score)
return score
除了全连接层结构,在分割问题中很难使用CNN网络的另一个问题是存在池化层。池化层不仅能增大上层卷积核的感受野,而且能聚合背景同时丢弃部分位置信息。然而,语义分割方法需对类别图谱进行精确调整,因此需保留池化层中所舍弃的位置信息。针对这个问题,目前研究人员提出两种方法解决:
- 编码器-解码器(encoder-decoder)结构
- 采用空洞卷积结构,去除池化层结构
3. 一种用于图像分割的深度卷积编码-解码架构
SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
论文中文翻译
论文主要创新点:
- 将最大池化指数转移至解码器中,改善了分割分辨率。
摘要: Segnet是用于进行像素级别图像分割的全卷积网络,分割的核心组件是一个encoder 网络,及其相对应的decoder网络,后接一个象素级别的分类网络。encoder网络:其结构与VGG16网络的前13层卷积层的结构相似。decoder网络:作用是将由encoder的到的低分辨率的feature maps 进行映射得到与输入图像featuremap相同的分辨率进而进行像素级别的分类。Segnet的亮点:decoder进行上采样的方式,直接利用与之对应的encoder阶段中进行max-pooling时的polling index 进行非线性上采样,这样做的好处是上采样阶段就不需要进行学习。 上采样后得到的feature maps 是非常稀疏的,因此,需要进一步选择合适的卷积核进行卷积得到dense featuremaps 。作者与FCN,DeepLab-LargeFOV, DenconvNet结构进行比较,统筹内存与准确率,Segnet实现良好的分割效果。SegNet主要用于场景理解应用,需要在进行inference时考虑内存的占用及分割的准确率。同时,Segnet的训练参数较少(将前面提到的VGG16的全连接层剔除),可以用SGD进行end-to-end训练。
在FCN网络中,通过上卷积层和一些跳跃连接产生了粗糙的分割图,为了提升效果而引入了更多的跳跃连接。
然而,FCN网络仅仅复制了编码器特征,而Segnet网络复制了最大池化指数。这使得在内存使用上,SegNet比FCN更为高效。

其中,编码器使用池化层逐渐缩减输入数据的空间维度,而解码器通过反卷积层等网络层逐步恢复目标的细节和相应的空间维度。从编码器到解码器之间,通常存在直接的信息连接,来帮助解码器更好地恢复目标细节。典型结构例如上图的UNet。
4. 采用膨胀(空洞)卷积的多尺度背景分割
MULTI-SCALE CONTEXT AGGREGATION BY DILATED CONVOLUTIONS
论文主要创新点:
- 使用了空洞卷积,这是一种可用于密集预测的卷积层;
- 提出在多尺度聚集条件下使用空洞卷积的“背景模块”。
池化操作增大了感受野,有助于实现分类网络。但是池化操作在分割过程中也降低了分辨率。
因此,该论文所提出的空洞卷积层是如此工作的:
在接下来将提到的DeepLab中,空洞卷积被称为多孔卷积(atrous convolution)。
从预训练好的分类网络中(这里指的是VGG网络)移除最后两个池化层,而用空洞卷积取代了随后的卷积层。
特别的是,池化层3和池化层4之间的卷积操作为空洞卷积层2,池化层4之后的卷积操作为空洞卷积层4。
这篇文章所提出的背景模型(frontend module)可在不增加参数数量的情况下获得密集预测结果。
这篇文章所提到的背景模块单独训练了前端模块的输出,作为该模型的输入。该模块是由不同扩张程度的空洞卷积层级联而得到的,从而聚集多尺度背景模块并改善前端预测效果。
需要注意的是,该模型预测分割图的大小是原图像大小的1/8。这是几乎所有方法中都存在的问题,将通过内插方法得到最终分割图。
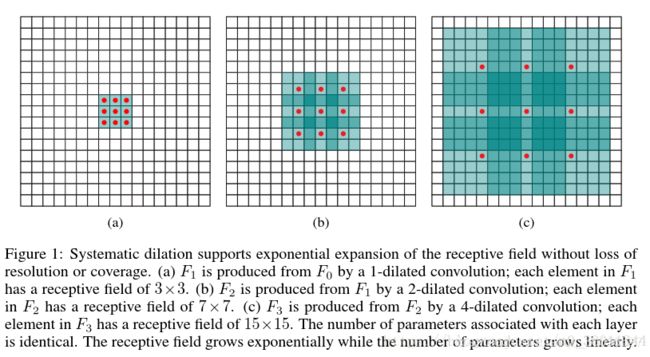
how: 卷积(空洞卷积)就是将传统的卷积推广到一个更一般的形式。这个形式并不新颖,其他很多问题中都有类似的推广,本文作者将这个形式推广到了神经网络中来。
我们首先解释普通卷积核的大小选择的影响,如果是连续三个卷积层且卷积核33(参考VGG),则这三个卷积层就相当于一个卷积核为77的卷积层。它们的感受野都是77。之所以用三个33不用一个77,因为参数数量少了(77+1-(333+3))个。
但是这样一个连续的3个33的卷积核最终的感受野才77而且随卷积层的增大,感受野以等差的方式增加(3,5,7,9…),效率太低,所以很多模型都用pooling的方式成倍提高感受野,而pooling不可避免的会忽略空间信息。
再来看一下膨胀卷积核的带来的变化,所谓膨胀卷积核,用通俗的话来说,就是带有空洞的卷积核,1-dilated卷积核相当于普通的卷积核,2-delated卷积核中间相差一个空洞,3-delated卷积核中间相差3个空洞…其卷积过程如下图:
4.以条件随机场为代表的后处理操作
Convolutional CRFs for Semantic Segmentation
代码github地址
当下许多以深度学习为框架的图像语义分割工作都是用了条件随机场(Conditional random field,CRF)作为最后的后处理操作来对语义预测结果进行优化。
最有效的模型传统上将条件随机场(CRF)的结构化建模能力与卷积神经网络的特征提取能力结合起来。然而,在最近的工作中中,使用条件随机场进行后处理已经不再受到人们青睐。我们认为这主要是由于条件随机场训练和推断速度太过缓慢以及其参数学习的难度所致。为了克服这两个问题,我们提出将条件独立的假设添加到全连接条件随机场的框架中。这使得我们可以在 GPU 上高效地使用卷积操作重新进行推断。这样做可以将推断和训练加速超过 100 倍。卷积条件随机场的所有参数都可以使用反向传播轻松进行优化。
5.深度空洞卷积和条件随机场的全卷积语义分割
Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
主要贡献:
- 使用了空洞卷积;
- 提出了在空间维度上实现金字塔型的空洞池化atrous spatial pyramid pooling(ASPP);
- 使用了全连接条件随机场。
具体解释:
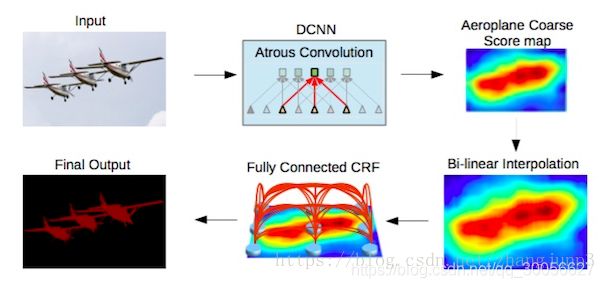
空洞卷积在不增加参数数量的情况下增大了感受野,按照上文提到的空洞卷积论文的做法,可以改善分割网络。
我们可以通过将原始图像的多个重新缩放版本传递到CNN网络的并行分支(即图像金字塔)中,或是可使用不同采样率(ASPP)的多个并行空洞卷积层,这两种方法均可实现多尺度处理。
我们也可通过全连接条件随机场实现结构化预测,需将条件随机场的训练和微调单独作为一个后期处理步骤。
6.用于高分辨率语义分割的多路径细化网络
Multi-Path Refinement Networks for High-Resolution Semantic Segmentation
主要贡献:
- 带有精心设计解码器模块的编码器-解码器结构
- 所有组件遵循残差连接的设计方式。
具体解释:
使用空洞卷积的方法也存在一定的缺点,它的计算成本比较高,同时由于需处理大量高分辨率特征图谱,会占用大量内存,这个问题阻碍了高分辨率预测的计算研究。
DeepLab得到的预测结果只有原始输入的1/8大小。
所以,这篇论文提出了相应的编码器-解码器结构,其中编码器是ResNet-101模块,解码器为能融合编码器高分辨率特征和先前RefineNet模块低分辨率特征的RefineNet模块。
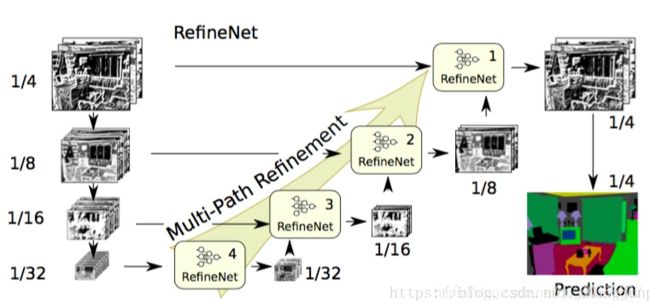
每个RefineNet模块包含一个能通过对较低分辨率特征进行上采样来融合多分辨率特征的组件,以及一个能基于步幅为1及5×5大小的重复池化层来获取背景信息的组件。
这些组件遵循恒等映射的思想,采用了残差连接的设计方式。

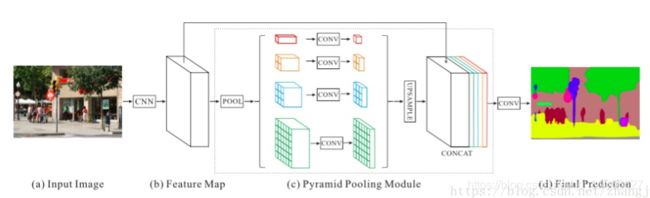
7.金字塔场景解析网络
Pyramid Scene Parsing Network
主要贡献:
- 提出了金字塔池化模块来聚合背景信息;
- 使用了附加损失(auxiliary loss)。
具体解释:
全局场景分类很重要,由于它提供了分割类别分布的线索。金字塔池化模块使用大内核池化层来捕获这些信息。
和上文提到的空洞卷积论文一样,PSPNet也用空洞卷积来改善Resnet结构,并添加了一个金字塔池化模块。该模块将ResNet的特征图谱连接到并行池化层的上采样输出,其中内核分别覆盖了图像的整个区域、半各区域和小块区域。
在ResNet网络的第四阶段(即输入到金字塔池化模块后),除了主分支的损失之外又新增了附加损失,这种思想在其他研究中也被称为中级监督(intermediate supervision)。
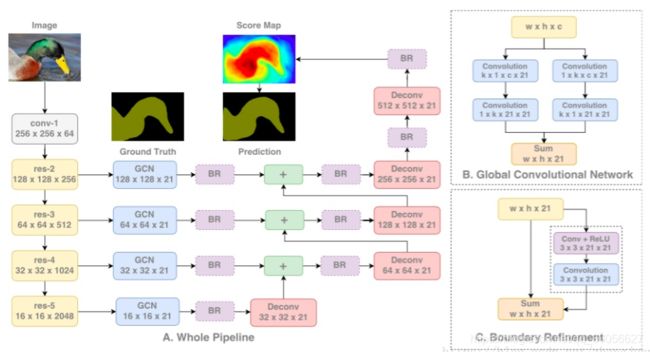
8. 改进全局卷积网络的语义分割-采用大维度卷积核
Large Kernel Matters — Improve Semantic Segmentation by Global Convolutional Network
主要贡献:
- 提出了一种带有大维度卷积核的编码器-解码器结构。
具体解释:
这项研究通过全局卷积网络来提高语义分割的效果。
语义分割不仅需要图像分割,而且需要对分割目标进行分类。在分割结构中不能使用全连接层,这项研究发现可以使用大维度内核来替代。
采用大内核结构的另一个原因是,尽管ResNet等多种深层网络具有很大的感受野,有相关研究发现网络倾向于在一个小得多的区域来获取信息,并提出了有效感受野的概念。
大内核结构计算成本高,且具有很多结构参数。因此,k×k卷积可近似成1×k+k×1和k×1+1×k的两种分布组合。这个模块称为全局卷积网络(Global Convolutional Network, GCN)。
接下来谈结构,ResNet(不带空洞卷积)组成了整个结构的编码器部分,同时GCN网络和反卷积层组成了解码器部分。该结构还使用了一种称作边界细化(Boundary Refinement,BR)的简单残差模块。
9.更多最新的语义分割的论文及相关代码
1.《Object Region Mining with Adversarial Erasing: A Simple Classification to Semantic Segmentation Approach》CVPR2017弱监督语义分割
详细介绍
项目
2.Effective Use of Dilated Convolutions for Segmenting Small Object Instances–卫星图像分割
详细介绍
论文地址
3.BlitzNet: A Real-Time Deep Network for Scene Understanding–ICCV2017 目标检测分割
详细介绍
项目 Project
Code
4.Deep Dual Learning for Semantic Image Segmentation --ICCV2017语义分割
详细介绍
5.FastMask: Segment Multi-scale Object Candidates in One Shot --CVPR2017 分割候选区域
Code
详细介绍
6.Fully Convolutional DenseNets for Semantic Segmentation --CVPRW 2017 语义分割
Code
论文地址
详细介绍
语义分割的展望
基于深度学习的图像语义分割技术虽然可以取得相比传统方法突飞猛进的分割效果,但是其对数据标注的要求过高:不仅需要海量图像数据,同时这些图像还需提供精确到像素级别的标记信息(Semantic labels)。因此,越来越多的研究者开始将注意力转移到弱监督(Weakly-supervised)条件下的图像语义分割问题上。在这类问题中,图像仅需提供图像级别标注(如,有「人」,有「车」,无「电视」)而不需要昂贵的像素级别信息即可取得与现有方法可比的语义分割精度。
另外,示例级别(Instance level)的图像语义分割问题也同样热门。该类问题不仅需要对不同语义物体进行图像分割,同时还要求对同一语义的不同个体进行分割(例如需要对图中出现的九把椅子的像素用不同颜色分别标示出来)
备注:部分转载自https://blog.csdn.net/zhangjunp3/article/details/80258577