Python+Selenium自动化测试教程连载(2)
上一期介绍了自动化测试Python+Selenium框架的基本介绍,这期讲元素定位。
元素定位
1.WEB自动化时利器–浏览器自带开发者工具
几乎所有浏览器都自带前端调试工具,也就是我们说的开发者工具。
开发者工具包括元素(ELements)、控制台(Console)、源代码(Sources)、网络(Network)、性能(Performance)等页签,可以分别点击查看。
元素(Elements):用于查看或修改HTML元素的属性、CSS属性、监听事件、断点。
控制台(Console):控制台一般用于执行一次性代码,查看JavaScript对象,查看调试日志信息或异常信息。
源代码(Sources):该页面用于查看页面的HTML文件源代码、JavaScript源代码、CSS源代码,此外最重要的是可以调试JavaScript源代码,可以给JS代码添加断点等。
网络(Network):网络页面主要用于请求数据的查看,网络连接相关的信息。
这些页签开发同学用的多些,我们测试人员一般使用元素(Elements)和网络(Network)。
其中做web自动化要用到元素
(Elements)
这个模块的功能,接口或性能测试使用网络(Network)。
2.如何调出开发者工具
一般直接F12即可打开开发者工具。
以chrome浏览器为例,也可以通过菜单打开:工具–更多工具–开发者工具

打开后页面如下,切换到第一个元素(Elements)页签:

可以改变开发者工具的出现位置和方式,谷歌中默认是浏览器右侧:

如何查看web元素
做自动化要找一个某个元素,要查看元素有没有NAME或ID属性,在浏览器渲染后的页面是看不到的,此时可以通过开发者工具进行查看。
F12快捷键打开开发者工具,点击其左上角鼠标图标。点击后图标变蓝,此时移动鼠标到web界面的各个元素上,可以看到元素信息,及对应元素定义代码块。
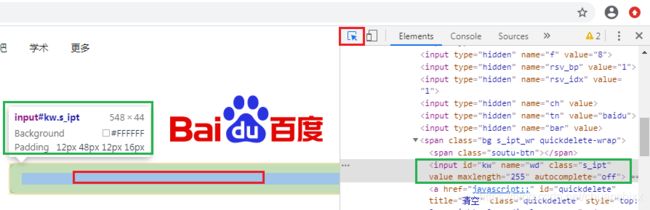
找到目标元素后,点击鼠标,则完成元素选择,右侧展示当前选中鼠标的信息。
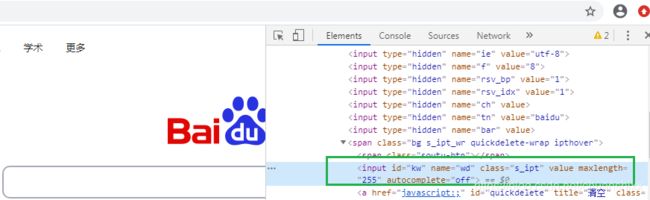
元素确定后,可以通过右键菜单,进行添加删除元素、编辑元素属性等操作:

也可以在当前前端文件中,进行元素查找匹配,鼠标定位到任意一行代码,按快捷键ctrl+f,在输入框中输入搜索字符串后回车,可以看到:总匹配个数,当前匹配元素。也可以上下键查看所有匹配项。
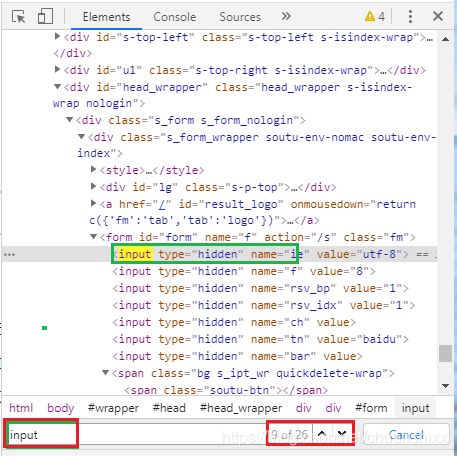
简单元素定位
所有的自动化工具要模拟用户操作,一般都要识别出用户在对哪个元素做什么操作
哪个元素即通常大家说的元素定位。我们需要告诉Selenium操作哪个元素,Selenium根据我们提供的信息到运行程序上进行元素匹配,匹配到即进行操作
WebDriver 提供了8大元素定位方式,我们先看前六种元素定位方式。
1.根据Id定位
假设要操作的Web元素定义如下:
这里有个属性是id="su",那么我们可以根据id进行元素定位:element = driver.find_element_by_id(“su”)
2.根据Name定位
element = driver.find_element_by_name(“wd”)
3.根据LinkText定位
超链接在web网站中很常见,通过它可以实现页面的跳转。
以百度搜索为例,通过开发者工具,看到如下超链接的创建语句:
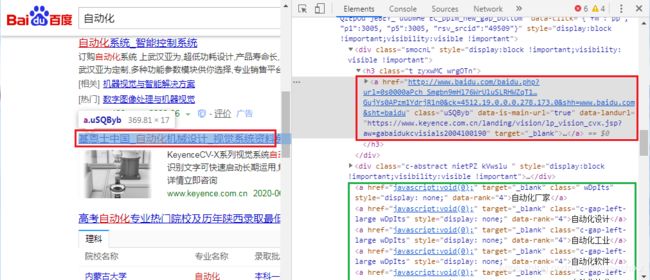
我们看到超链接a标签即没有id也没有name属性,那么我们怎么找到它?
如果一个页面有多个超链接,那么至少从超链接文本上能够区分,如:

同样的,selenium中也根据link text进行超链接定位,要查找第一个超链接,把它的超链接文本作为参数传递给
find_element_by_link_text方法:
Link_element = driver.find_element_by_link_text(“自动化专业现在吃香吗”)
4.根据PartialLinkText定位
我们可以做超链接字符串的部分匹配:
Python(计算机程序设计语言)_百度百科
超链接字符串为:Python(计算机程序设计语言)_百度百科
部分匹配:在当前页面查找超链接字符串包含“_百度百科”的元素
ele = driver.find_element_by_partial_link_text("_百度百科")
ele.click()
5.根据class Name定位
每个元素在定义时有class属性,相当于把这个元素划归到某类中:
则可以根据类别名称进行定位:ele = driver.find_element_by_class_name(“s_ipt”)
- 如果元素定义时class值中间带空格,相当于这个元素同时属于多个类别:
按照整个class的值定位会失败,可以根据某个类名定位:
ele = driver.find_element_by_class_name(“s_ipt_wr”)
6.根据tag Name定位
每个元素在HTML文件中,都有个标签名称,如input,div,form,span等
若元素没有id,name这些易于定义的属性,也可以根据标签名称input进行定位:ele = driver.find_element_by_tag_name(“input”)
- 通常一个页面上同类型的标签会不止一个,需要进行过滤。
根据xpath进行元素定位
在前边的6种元素定位方式中,如果元素没有id或name,或者根据class名称tag名称无法准确定位到元素的话,就可以采用xpath进行元素定位。
XPath 是一门在 XML 文档中查找信息的语言。 它使用路径表达式在 XML 文档中进行内容查找。
1.Xml术语
节点在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点。XML 文档是被作为节点树来对待的
如:
Harry Potter J K. Rowling 2005 29.99其中有如下结点:
(文档节点)
J K. Rowling (元素节点)
(属性节点)
基本值是无父或无子的节点。
基本值的例子:
J K. Rowling
“en”
2.节点关系
节点之间可能是父子,兄弟,同胞,先辈或后代的关系。
Harry Potter J K. Rowling 2005 29.99Book节点是title、author等节点的父节点,同时,title、author是book的子节点。
Title、author、year、price之间是同胞关系。
Bookstore是title、author和book的先辈节点,同时bookstore的后辈节点是title、author和booke等节点。
3.xpath语法
XPath 使用路径表达式来选取 XML 文档中的节点或节点集。节点是通过沿着路径 (path) 或者不 (steps) 来选取的。
Harry Potter29.99
Learning XML39.95
4.选取节点
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。下面列出了最有用的路径表达式:
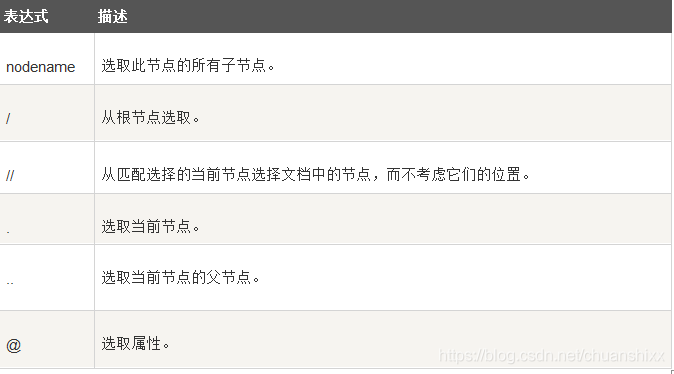
5.谓语
谓语用来查找某个特定的节点或者包含某个指定的值的节点。
谓语被嵌在方括号中。
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
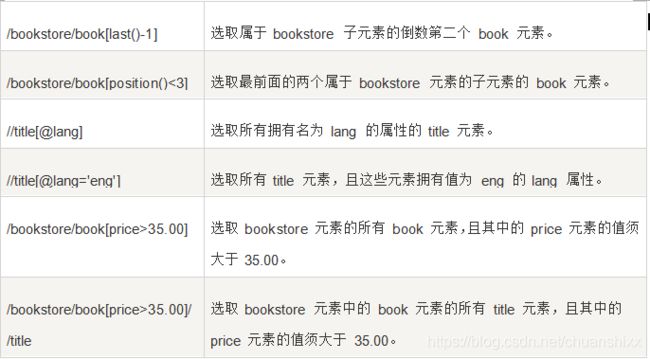
6.选取未知节点
XPath 通配符可用来选取未知的 XML 元素。

find_element与find_elements方法的区别
自动化过程中,通过find_elemet_by_id方法进行元素定位时,有时操作不到目标元素。原因可能是由于页面代码开发时不够规范,不同的元素id相同。
针对这种情况,Selenium开发了两套find方法,如下:
find_element_by_id find_elements_by_id
find_element_by_name find_elements_by_name
find_element_by_tag_name find_elements_by_tag_name
find_element_by_xpath find_elements_by_xpath
等等
那么两套方法使用上有何区别:
若匹配到元素:
find_element返回第一个匹配WebElement元素
Find_elements返回列表,包括所有匹配元素
若匹配不到元素:
find_element报异常
Find_elements返回空列表
两套方法使用时根据实际情况选择。
如果确定当前一个元素定位方式到底匹配到几个元素呢?可以在chrome的开发者工具中直接做验证,获取使用火狐浏览器的插件进行验证都可以。