数据结构——双向循环链表模板类
数据结构笔记(二)
今天可是10.1呀,瞧瞧我在干什么?竟然没去大明湖,没去趵突泉……,而是在教室敲数据结构的代码。当然,最终可以把相关知识的代码写出来,并与有梦想的你一块分享、学习,意义也是蛮大的。
这篇博客主要是贴出数据结构中一个重要的模板class——双向循环链表,也会在最后提到一些写此template class时的注意点和易错点,希望自己作为前车之鉴,也希望各位指正、批评。
双向循环链表主类定义:
//双向循环链表模板类代码
#include *lLink, *rLink; //定义左链指针和右链指针
DbNode(DbNode *left = NULL, DbNode *right = NULL) : //构造函数并初始化两个指针
lLink(left), rLink(right) {}
DbNode(T value, DbNode *left = NULL, DbNode *right = NULL) :
data(value), lLink(left), rLink(right) {}
};
//双向循环链表模板类定义
template<class T>
class DbList {
public:
DbList(T uniqueVal); //构造函数
~DbList(); //析构函数
int Length() const; //计算双向链表的长度
bool IsEmpty(){ return first->rLink == first; } //判断双向循环链表是否为NULL
DbNode * getHead() const{ return first; } //取附加头节点地址
void setHead(DbNode * ptr) { first = ptr; } //设置附加头节点的地址
DbNode * Search(const T & x); //在链表中沿后继方向查找给定x的data节点
//在链表中定义序号为i(i》= 90)的节点,d = 0按照前驱方向,d != 0 按照后继方向
DbNode * Locate(int i, int d);
//在i个节点后插入一个包含有x值得新节点,d = 0 按照前驱方向,d != 0按照后继方向
bool Insert(int i, const T & x, int d);
//删除第i个节点,x存储删除节点的数据,d = 0 按照前方向, d != 0按照后继方向
bool Remove(int i, T & x, int d);
void CreateDbList(T endFlag); //创建双链表
void OutputList(int model = 0); //输出循环双向链表
protected:
DbNode * first;
};
//函数定义
template<class T>
DbList::DbList(T uniqueVal) {
//构造函数建立双向链表的附加头节点,他包含了一个用于某些特殊情况的值
first = new DbNode(uniqueVal);
if (NULL == first) {
cerr << "存储分配出错" << endl;
exit(1);
}
first->rLink = first->lLink = first; //因为是循环链表,所以初始化都指向自己
}
template<class T>
DbList::~DbList() {
//析构函数,释放指针资源
delete first;
}
template<class T>
int DbList::Length() const {
//计算带附加头节点的双向循环链表的长度,通过函数返回
DbNode *current = first->rLink;
int count = 0;
while (current != first) {
current = current->rLink;
count++;
}
return count;
}
template<class T>
DbNode * DbList::Search(const T & x) {
//在带附加头节点的双向循环链表中寻找其值等于x的节点;
//若找到,则函数返回该节点的地址,否则函数返回NULL
DbNode *current = first->rLink;
while (current != first && current->data != x) {
current = current->rLink;
}
if (current->data == x) {
return current;
}
else {
return NULL;
}
}
template<class T>
DbNode * DbList::Locate(int i, int d) {
//在带附加头节点的双向循环链表中按照d所指的方向寻找第i个节点的地址,若d = 0在前驱方向上
//寻找第i个节点,若d != 0,在后继方向上寻找第i个节点
if (first->rLink== first || 0 == i) { //第0个节点或者是NULL表
return first;
}
DbNode *current = NULL;
if (0 == d) { //确定搜索方向
current = first->lLink;
}
else {
current = first->rLink;
}
for (int j = 1; j < i; j ++) {
if (current == first) { //i 的大小超过了Length
break;
}
else if (0 == d) { //指针继续向后游动
current = current->lLink;
}
else {
current = current->rLink;
}
}
if (current != first) { //判断是否定位成功
return current;
}
else {
return NULL;
}
}
template<class T>
bool DbList::Insert(int i, const T & x, int d) {
//建立一个包含有x的新节点,并将其按照d指定的方向插入到第i个节点之后
DbNode *current = Locate(i, d); //用定位函数定位到相应的节点
if (NULL == current) { //i不合理,插入失败
return false;
}
DbNode *newNode = new DbNode(x); //新建节点并初始化
if (NULL == newNode) {
cerr << "内存分配错误" << endl;
exit(1);
}
//注意不同d导致插入时的“后面”位置不是同一个概念
if (0 == d) {
newNode->lLink = current->lLink;
current->lLink = newNode;
newNode->lLink->rLink = newNode;
newNode->rLink = current;
}
else {
newNode->rLink = current->rLink;
current->rLink = newNode;
newNode->rLink->lLink = newNode;
newNode->lLink = current;
}
return true;
}
template<class T>
bool DbList::Remove(int i, T & x, int d) {
//在附加头节点的双向循环链表中按照d所指的方向删除第i个节点
DbNode *current = Locate(i, d);
if (NULL == current) { //i不合理删除失败
return false;
}
current->lLink->rLink = current->rLink;
current->rLink->lLink = current->lLink;
x = current->data;
delete current;
return true;
}
template<class T>
void DbList::CreateDbList(T endFlag) {
//创建循环双向链表,直到遇到endFlag停止
DbNode *newNode, *tail; //创建新节点的指针和时刻指向尾部的指针
tail = first;
T inVal;
cin >> inVal;
while (endFlag != inVal) {
newNode = new DbNode(inVal);
newNode->lLink = tail;
tail->rLink = newNode;
tail = newNode;
cin >> inVal;
}
tail->rLink = first; //构建循环
first->lLink = tail;
}
template<class T>
void DbList::OutputList(int model) {
//此函数用来输出循环双向链表,默认是沿着后继输出,model != 0,沿着前驱输出
DbNode *output = NULL; //创建游动指针
if (0 == model) {
output = first->rLink;
while (output != first) {
cout << output->data << " ";
output = output->rLink;
}
}
else {
output = first->lLink;
while (output != first) {
cout << output->data << " ";
output = output->lLink;
}
}
cout << endl;
} 测试主函数:
#include dblist1(0);
//dblist1.CreateDbList(0); //创建结束数据设置为0
//cout << dblist1.Length() << endl; //长度计算输出测试
//DbList dblist2(0);
//dblist2.CreateDbList(0);
//dblist2.Insert(3, 100, 0); //前驱插入测试
//dblist2.Insert(5, 100, 1); //后继插入测试
//dblist2.OutputList();
//dblist2.OutputList(1);
int delVal_1 = 0, delVal_2 = 0;
DbList<int> dblist3(0);
dblist3.CreateDbList(0);
dblist3.Remove(3, delVal_1, 0); //前驱删除测试
dblist3.OutputList();
dblist3.Remove(5, delVal_2, 1); //后继删除测试
dblist3.OutputList(); //默认后继输出
system("pause");
return 0;
}结果展示(途中只测试了双向删除函数)
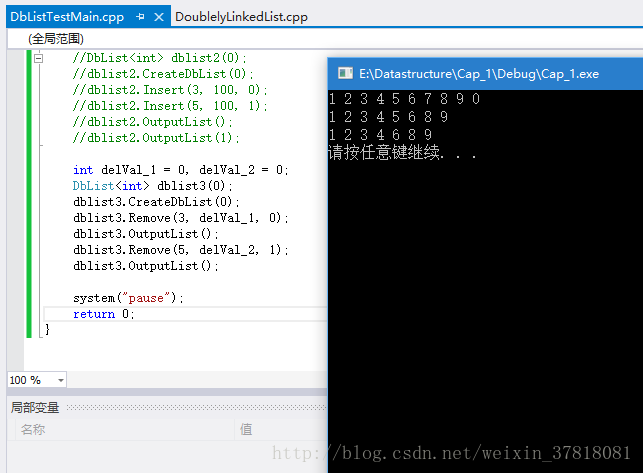
注意点:
1、插入与删除函数的实现,应该考虑两个方向上的操作,所以代码中添加了模式标识符d
2、为了更好的实现插入与删除操作,最好定义一个定位函数(代码中的Locate函数),写代码时能够明显感觉出优势。
3、集成在定位函数中,可以省去很多繁琐的工作,如检查插入、删除数据的合法性,不用重复遍历等等。
4、尤其是在插入操作