遇见C++ Lambda
遇见C++ Lambda
Written by Allen Lee
If you die when there's no one watching, and your ratings drop and you're forgotten.
– Marilyn Manson, Lamb Of God
生成随机数字
假设我们有一个vector<int>容器,想用100以内的随机数初始化它,其中一个办法是通过generate函数生成,如代码1所示。generate函数接受三个参数,前两个参数指定容器的起止位置,后一个参数指定生成逻辑,这个逻辑正是通过Lambda来表达的。
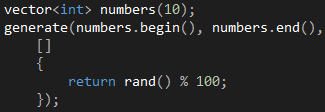
代码 1
我们现在看到Lambda是最简形式,只包含捕获子句和函数体两个必要部分,其他部分都省略了。[]是Lambda的捕获子句,也是引出Lambda的语法,当编译器看到这个符号时,就知道我们在写一个Lambda了。函数体通过{} 包围起来,里面的代码和一个普通函数的函数体没有什么不同。
那么,代码1生成的随机数字里有多少个奇数呢,我们可以通过for_each函数数一下,如代码3所示。和generate函数不同的是,for_each函数要求我们提供的Lambda接受一个参数。一般情况下,如果Lambda的参数列表不包含任何参数,我们可以把它省略,就像代码1所示的那样;如果包含多个参数,可以通过逗号分隔,如(int index, std::string item)。
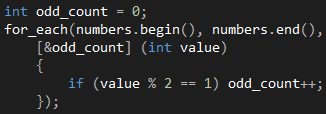
代码 2
看到这里,细心的读者可能已经发现代码2的捕获子句里面多了一个"&odd_count",这是用来干嘛的呢?我们知道,这个代码的关键部分是在Lambda的函数体里修改一个外部的计数变量,常见的语言(如C#)会自动为Lambda捕获当前上下文的所有变量,但C++要求我们在Lambda的捕获子句里显式指定想要捕获的变量,否则无法在函数体里使用这些变量。如果捕获子句里面什么都不写,像代码1所示的那样,编译器会认为我们不需要捕获任何变量。
除了显式指定想要捕获的变量,C++还要求我们指定这些变量的传递方式,可以选择的传递方式有两种:按值传递和按引用传递。像[&odd_count] 这种写法是按引用传递,这种传递方式使得你可以在Lambda的函数体里对odd_count变量进行修改。相对的,如果变量名字前面没有加上"&"就是按值传递,这些变量在Lambda的函数体里是只读的。
如果你希望按引用传递捕获当前上下文的所有变量,可以把捕获子句写成[&];如果你希望按值传递捕获当前上下文的所有变量,可以把捕获子句写成[=]。如果你希望把按引用传递设为默认的传递方式,同时指定个别变量按值传递,可以把捕获子句写成[&, a, b];同理;如果默认的传递方式是按值传递,个别变量按引用传递,可以把捕获子句写成[=, &a, &b]。值得提醒的是,像[&, a, &b]和[=, &a, b]这些写法是无效的,因为默认的传递方式均已覆盖b变量,无需单独指定,有效的写法应该是[&, a]和[=, &a]。
生成等差数列
现在我们把一开始的问题改一下,通过generate函数生成一个首项为0,公差为2的等差数列。有了前面关于捕获子句的知识,我们很容易想到代码3这个方案,首先按引用传递捕获i变量,然后在Lambda的函数体里修改它的值,并返回给generate函数。
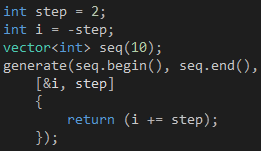
代码 3
如果我们把i变量的传递方式改成按值传递,然后在捕获子句后面加上mutable声明,如代码4所示,我们可以得到相同的效果,我指的是输出结果。那么,这两个方案有什么不一样呢?调用generate函数之后检查一下i变量的值就会找到答案了。需要说明的是,如果我们加上mutable声明,参数列表就不能省略了,即使里面没有包含任何参数。
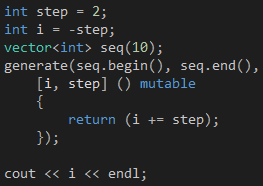
代码 4
使用代码3这个方案,i变量的值在调用generate函数之后是18,而使用代码4这个方案,i变量的值是-2。这个意味着mutable声明使得我们可以在Lambda的函数体修改按值传递的变量,但这些修改对Lambda以外的世界是不可见的,有趣的是,这些修改在Lambda的多次调用之间是共享的。换句话说,代码4的generate函数调用了10次Lambda,前一次调用时对i变量的修改结果可以在后一次调用时访问得到。
这听起来就像有个对象,i变量是它的成员字段,而Lambda则是它的成员函数,事实上,Lambda是函数对象(Function Object)的语法糖,代码4的Lambda最终会被转换成代码5所示的Functor类。
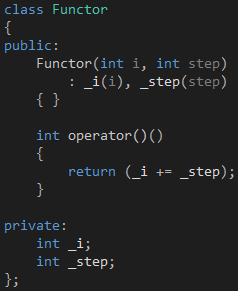
代码 5
你也可以把代码4的Lambda替换成Functor类,如代码6所示。

代码 6
如何声明Lambda的类型?
到目前为止,我们都是把Lambda作为参数直接传给函数的,如果我们想把一个Lambda传给多个函数,或者把它当作一个函数多次调用,那么就得考虑把它存到一个变量里了,问题是这个变量应该如何声明呢?如果你确实不知道,也不想知道,那么最简单的办法就是交给编译器处理,如代码7所示,这里的auto关键字相当于C#的var,编译器会根据我们用来初始化f1变量的值推断它的实际类型,这个过程是静态的,在编译时完成。
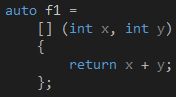
代码 7
如果我们想定义一个接受代码7的Lambda作为参数的函数,那么这个参数的类型又该如何写呢?我们可以把它声明为function模板类型,如代码8所示,里面的类型参数反映了Lambda的签名——两个int参数,一个int返回值。
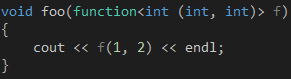
代码 8
此外,你也可以把这个函数声明为模板函数,如代码9所示。
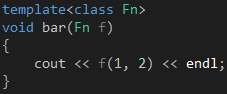
代码 9
无论你如何声明这个函数,调用的时候都是一样的,而且它们都能接受Lambda或者函数对象作为参数,如代码10所示。
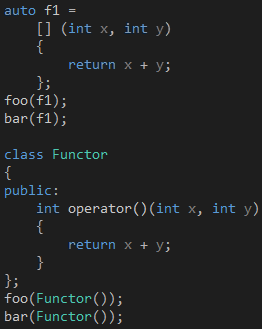
代码 10
捕获变量的值什么时候确定?
现在,我要把代码7的Lambda调整成代码11所示的那样,通过捕获子句而不是参数列表提供输入,这两个参数分别使用不同的传递方式,那么,我在第三行修改这两个参数的值会否对第四行的调用产生影响?
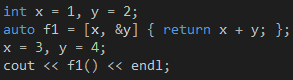
代码 11
如果你运行代码11,你将会看到输出结果是5。为什么?这是因为按值传递在声明Lambda的那一刻就已经确定变量的值了,无论之后外面怎么修改,里面只能访问到声明时传过来的版本;而按引用传递则刚好相反,里面和外面看到的是同一个东西,因此在调用Lambda之前外面的任何修改对里面都是可见的。这种问题在C#里是没有的,因为C#只有按引用传递这种方式。
返回值的类型什么时候可以省略?
最后,我们一直没有提到返回值的类型,编译器会一直帮我们自动推断吗?不会,只有两种情况可以在声明Lambda时省略返回值类型,而前面的例子刚好都满足这两种情况,因此推到现在才说:
- 函数体只包含一条返回语句,如最初的代码1所示。
- Lambda没有返回值,如代码2所示。
当你需要加上返回值的类型时,必须把它放在参数列表后面,并且在返回值类型前面加上"->"符号,如代码12所示。
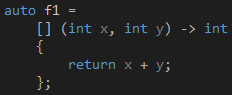
代码 12
*以上代码均在Visual Studio 2010和Visual Studio 2012 RC上测试通过。