网易的黑科技:以前策划写三四周AI,现在放那儿自己跑就行了

| 摘要:有了这样的AI之后,《逆水寒》1V1的代练就找不到了。 |
整理/安德鲁
强化学习不需要你去写规则。很多场景,以前可能策划需要写三四周的AI,交给强化学习,策划不用管这个事情,让这个机器跑着就好了。
”
强化学习不需要你去写规则。很多场景,以前可能策划需要写三四周的AI,交给强化学习,策划不用管这个事情,让这个机器跑着就好了。
前几天的北京国际游戏创新大会(BIGC)上,网易伏羲实验室的吕唐杰分享了他们对于应用强化学习的研究、理解和应用。
他重点讲述了强化学习的应用意义,以及怎样与以往游戏中传统AI开发方式结合,形成1+1大于2的效果。他也谈到了强化学习在游戏中的一些落地方式。比如《逆水寒》中,更多样化的AI应用,就让玩家的PVP内容有了极其丰富的层次——“有了这样的AI之后,《逆水寒》1V1的代练就找不到了。”
以下是葡萄君整理的演讲内容。
大家下午好,我叫吕唐杰,我今天的题目是《应用强化学习来开发游戏AI》。我们从2017年年底开始做强化学习,到现在做了快三年的时间,这方面积累了一些经验,今天给大家分享一下工作的一些成果。

今天整个分享内容分成四个部分:
第一部分简单介绍一下强化学习和游戏AI,强化学习刚才有几位老总都讲过了,我就不太细讲技术细节了。
第二部分介绍一下我们自研的一套强化学习框架,RLEase。
第三部分是我们真正通过强化学习的落地效果。
第四部分,强化学习多个场景下遇到了很多问题,我觉得还有很多需要解决的。
一
第一部分,先介绍一下什么是强化学习以及游戏AI。强化学习跟深度学习、监督学习不太一样,强化学习更像是人类学习的过程。它的目标是最大化累计的reward,我们感知到环境做一些行为,这个行为会让外部环境发生改变,外部环境对我们反馈,根据这个反馈我们学习这个行为到底好还是不好,这个目标是长期的目标,我可以承受一些短期的负惩罚。
强化学习不是看短期目标,而是看非常长期的目标,只要奔着长期目标好的事情就会做。强化学习这几年有了巨大的发展,包括这一波人工智能的技术,我觉得其实也是由强化学习来推动这个潮流。最早从谷歌用AI来玩游戏,八十年代的游戏非常简单。相对于最有名的、做得最好的两个公司,一个是DeepMind,一个是OpenAI。他们现在已经有新的OpenAI的应用,在《星际争霸2》游戏项目上做到了顶尖人类选手的水平,是以前我们做传统AI几乎无法想象的效果。
强化学习这几年取得了非常大的进展,对于游戏开发者来说,强化学习到底怎么用?你肯定很懵,这个强化学习怎么用到我们实际游戏开发里面?

游戏开发者更熟悉的AI技术,一个是有限状态机,一个是行为树。这两种技术都认为是一种规则技术,说白了就是人去写规则,你想要它什么样的行为,你就写出什么样的规则出来。
状态机也好,或者行为树也好,只是做了AI开发范示,怎么在游戏里面把规则写得清楚,不出现太大的问题——你要写一个非常复杂的AI,或者水平非常高的AI。为什么会有这个问题?因为人自己也想不清楚到底该去怎么打,这个场景太复杂了。如果想要变得那么强的话,一个是树变得非常巨大,二是可能树之间的规则写着写着就搞不太清楚了,很难把握这个点。
强化学习可以解决这个问题。强化学习是一种自学习的技术,不需要你去写规则。包括我们现在落地下来一些感觉:很多场景,以前可能策划需要写两周,三四周的AI,强化学习交给它,策划不用管这个事情,让这个机器跑着就好了。强化学习有这个能力,但是它也会有很多的问题。

强化学习技术门槛也有点高,我们想的是:
第一点,怎么降低强化学习的接入和使用的门槛,让更多的游戏开发者能使用上这个技术?
第二点,因为强化学习技术本身发展在日新月异,学术圈非常火爆,基本每年都会大量的文章出来,新技术、新发展。研究人员可能想在我们的游戏环境中,实验一下新想法、新算法,怎么能让AI研究人员更好地理解游戏的需求?因为游戏环境还是挺复杂的,需要很多的专业背景。
第三点,我们已经有很多的传统AI技术,怎么结合传统AI技术与强化学习,这个也是比较重要的问题。
第四点,我们在想这个问题,如何将强化学习这个东西应用到更广泛的游戏领域,提升玩家体验。
二
下一步就是介绍的我们这边做的RLEase框架,这个本质上是为了解决一些问题。我们网易有一套自己的工具,传统的开发AI的工具,我们这边叫流程图。其实就是我们写代码的时候会破坏一些示意图,我们有这样的工具来开发游戏AI,比如说用锁开门这样的AI。
左边是示例,这里面这个东西跟行为树很像。它里面每个节点有状态,有颜色代表不同的转移,跟行为树整体上比较类似。支持一些异步的模式,这个是我们现在网易这边开发游戏很常用的一套工具。
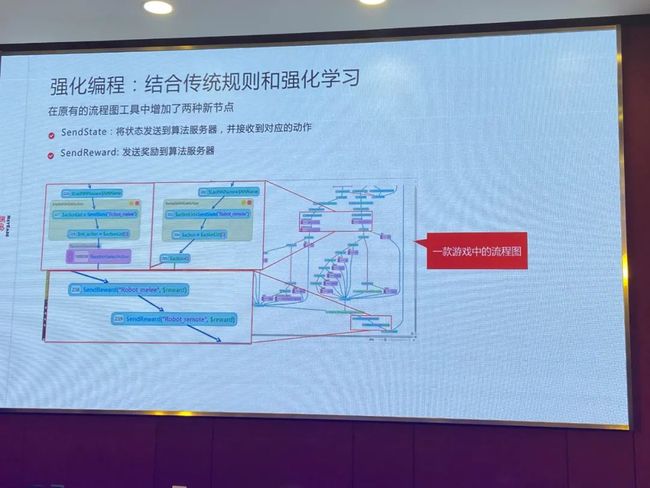
第一个问题,他们开发好了很多AI,我们怎么能把强化学习结合进去,它也有很多其他逻辑在里面,不可能从头用强化学习。我们的想法是,把强化学习的技术跟我们流程图工具结合起来,强化学习里加上两种新的节点,叫SendState和SendReward。
这是一个真实游戏里的流程图,我们截出来,结合强化学习来跑。这是游戏很复杂的时候——大型的吃鸡游戏,可能有很多AI,AI怎么跑毒,碰到人怎么打,里面有很多逻辑,强化学习跟它怎么结合呢?
因为强化学习技术本身并没有那么神奇,好像什么场景都能解决,它对计算量要求很高,跟它的结合点,是让它解决一些强化学习比较适合解决的问题,或者传统AI不太好做的问题。比如说碰到对手怎么跟它打,这个事情AI不太好写——游戏比较复杂,技能比较多,打起来套路很多,你就不知道怎么应对对手的套路。
针对这个我们把一部分功能替换成了强化学习的函数,对它来说调了一个接口。我把当前的游戏信息发给你,你只要告诉我该放什么技能就行了,其他的我自己不管。相当于我写了一段跟战斗相关的AI,但这个AI并不是他自己写的,而是交给我们强化学习训练出来的。剩下的跑毒也好,大地图里面捡东西也好,这种不去训练。因为这种逻辑很好写,没必要交给我们来做。我们是通过这样的方式。来结合传统的规则和强化学习的。
另外,刚才讲了强化学习的技术门槛好像有点高,很多传统的写AI的不太懂。我们希望开发一套东西能让这个强化学习变得简单一点,RLEase这套框架最重要的是简化环境的接入流程,能让游戏接入成本降低,降低强化学习的门槛,特别是让AI研究人员降低大规模强化学习的门槛,目前这些特性先不细讲了。对于AI研究员来说我们提供了标准的接口,这个技术在日新月异地发展,很多时候有新的算法和新的方法尝试。我们也是这套框架里面添加了标准的接口,这个框架本身是有很多特性,对于AI研究员来说只要新写一个算法,这些特性都已经集成好了。
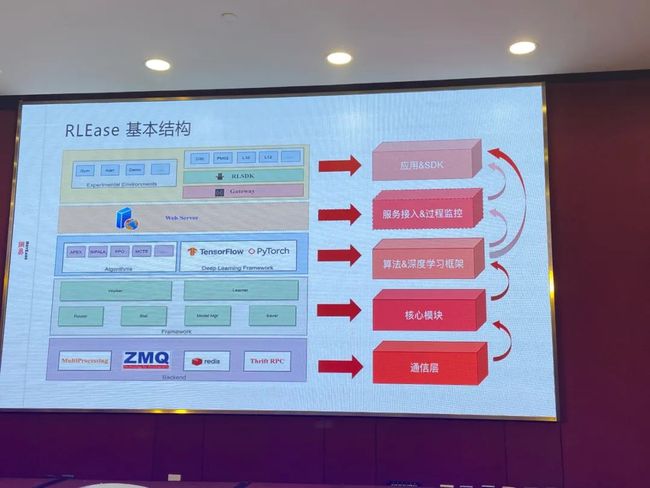
我们这套RLEase整体上是这样,跟传统深度学习有一点不一样,是大规模的计算,对计算支援要求比较高,对于框架要求也比较高。一个是面向游戏开发团队,能降低他们的难度,另外能让AI研究人员降低开发新算法的难度。让所有的节点通信都交给我们底层通信来做。
再上层一点就是我们深度学习的能力,另外就是深度学习,这些都是在我们框架里面比较好的支持。另外我们在上层,为游戏开发团队来说提供了一个ISDK。ISDK就是给游戏团队用的,用了这套SDK可以跑运算环境,他只要拿到上层的SDK就可以了。对于AI研究人员来说,只需要关注算法和深度学习框架。
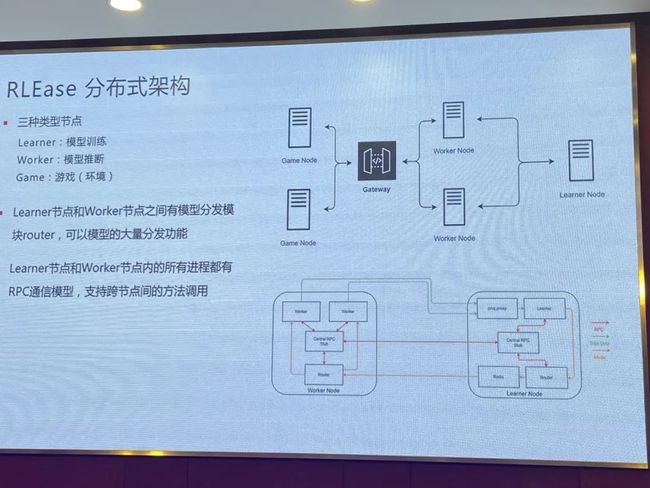
我刚才讲了怎么支持这种能力,简单介绍一下我们这种分布式结构里面,精简的话会有几种概念。第一种讲了三重类型的节点,一种是Leanre,模型训练。第二是Worer,模型推心。第三是Gome,游戏(环境)。这样分离的方式支持分布式,每个节点可以放在不同物理的服务器上的。另外一个是所有节点之间都会有IBC通信,比如说一些高性能的模型分发相关的功能,能支撑我们把这个训练框架的规模提高到上千甚至上万这个级别。
听了上半场觉得这东西好像特别费资源,我们自己做下来,对于很多场景,如果不想要追求职业选手这样水平的话,并不需要那么高,所以也没有那么大的硬件门槛。
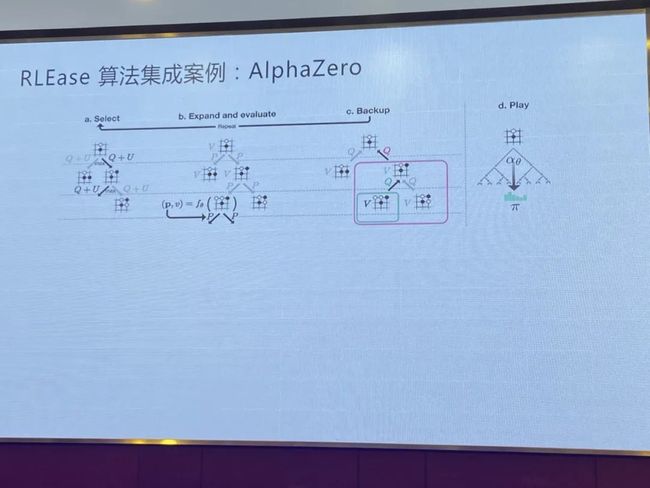
讲个例子,我们上半年给《逆水寒》做五子棋。但是玩家跟玩家之间玩五子棋的人不多,再有一点,玩家输了不太爽,有受挫感。我们当时没有做围棋的的项目,我们从头开始集成算法框架。在RLEase里面简单实现了几个模块,标准定了几个接口。这个接口实现好了之后,我们的AlphaZero已经成功了,它自带大规模分布式的能力,我们可以做到好几个节点同时跑,大概跑到23000的样子,这个五子棋的AI就已经比市面上找到的所有传统搜索AI明显要强。游戏里面不需要那么强的AI,我们为什么做这么强的AI,因为我们发现做了强AI后再做简单AI非常容易。
另外一个是我们提供的SRA,常见的开发脚本,一般来说,传统端游里面会有C++,现在手游可能在集成脚本上的Lua来做。为了让游戏方用我们的SDK,我们提供了多语言版本的支持。举个例子,这个SDK是给研究员用的。怎么用呢?你在游戏里面Input一下SDK,在你想要做请求,比如说这个AI写不清楚了,想交给AI做,这个时候插一个函数就行了。Python这个游戏自己能学出来到底该怎么打。

开发完AI之后还得有个部署。游戏线上怎么用?我们这边做了好几款游戏,积累了一些经验,我们有服务端的ASI的部署能力,部署了AI服务器,让游戏请求到AI服务器,进行AI推理,进行对应的动作。另外一个提供一些客户端部署方案,现在有在安卓、iOS上的部署。有些游戏必须是在手游上部署的,因为逻辑就在客户端上,我们提供SDK能直接把训练好的模型变成在端上的模型直接用。
三
第三部分介绍一下我们在《逆水寒》里的效果,这是给他们做的一个游戏场景,是一个流派竞技的玩法。这个玩法每天可以排行榜里挑战排行更高的玩家,但MMO里玩家不一定实时在线,当这个玩家不在线的时候,可以用AI替代玩家出战。以前AI很弱,基本上都能打过。游戏方要我们提供高水平的、提供不同难度的AI,让对手也能体验到乐趣。另外也希望AI能有这样一些行为多样性。

看上去好像很简单一个场景,1V1,实际上还有很多困难。《逆水寒》里面有20个技能,每次携带10个技能出场,每个玩家携带的不一样,升级路线也不一样。因为AI是替代玩家打,这就要求AI要去适应所有玩家的技能组合。这个组合其实很多。光这样一个职业AI,就有4万多种技能组合。
怎么表示这种场景?玩家可能携带了很多技能,怎么在建模过程中表示带了哪些技能、可以用哪些技能、让模型合理地用技能?我们用01向量表示玩家携带的技能。模型可能会输出未携带技能,当它输出不合法的动作,我们会替换掉。这个游戏里面龙吟地上插很多器件,可以刷技能CD,理论上它应该要看到这个信息。

常见想法是,深度学习直接画一张图就行了,用Image表示就可以了。这样它的计算量成倍增长,需要很多GPU、很多计算时间。但这对于这样一款游戏真正落地来说是不适合的,我们不可能用这么多的代价训练这样一个AI。我们做了一个取舍:我们让AI看到这些,雷达图让AI看到周边哪些地方是有器件的,不需要那么准的位置,标一下就行了。最后展出来就是八维的向量,输入到state里面,最后测出来这个已经达到水平了。
我们训出来比较强的AI,怎么匹配多难度的玩家?一种做法是比较简单的,一种比较天然的想法,因为我们训练这个模型就是越来越强的,我把前期的模型拿出来就是弱的,中期的模型拿出来比较中期的水平。
这样就会带来一个问题——可能在线上部署了非常多的模型,在线上用的时候,我要用十几个段位,部署十几个模型,对我们挑战也非常大。我们后来只做一个模型,专家跟低水平玩家之间的差距体现在几方面,一是操作反应速度、技能释放频率。高手技能释放间隔非常短,释放速度非常快,那种动作的反应非常好。低水平玩家,这点要弱一点。
所以我们增加了一维参数,调整AI输出频率。另外高水平玩家在APM高的基础上,误操率也很低。而有些玩家,可能按的很快,但是很多时候按错了,做了很多误操作,这也是影响人水平的过程。
还有一个维度就是动作随机概率,让模型有一定概率使出随机动作,这个也比较明显地降低了玩家AI水平。另外一点,我们是在仿照人类,玩家对于战场信息判断有问题的。针对这一点,可以在输入层上加噪音,在一些关键信息——比如说血量、位置、技能的CD——这些关键信息上加一些噪音,这个AI水平也会有明显的下降。他自己也看不清了,判断就会出错。

这些东西到底有没有用?我们做了验证,让这些参数变得水平越来越低、间隔越来越大、随机概率越来越高。我们训一个AI之后,最高水平是1600,随着参数越来越弱,水平几乎是线性下降。线上打出来的感觉,也和低水平玩家蛮像的——这个基本上已经满足了策划的需求。
我们线上部署的时候部署了一个模型,这样一个场景下,基本上能满足当前1V1的需求。对于复杂的,比如说团队游戏,这些参数可能不够,还要在策略层上做一些丰富性。不过对当前的场景来说,只能说这是一个比较好的解决方案了。
另外,我们训练出的这个AI,水平到底够不够强,开发组这边请最高水平的玩家来体验过。实际上AI水平已经非常高了。
红色的是AI,绿色的是我们这边龙吟的高手。我们AI是不掉血的,基本上所有技能都可以完美躲过。如果没玩过这个游戏可能看不太清楚为什么赢。为什么两个人放同样的技能,看着差不多的,但有一方基本上没怎么掉血?我们采访过策划,他说AI的一些组合非常合理,很多时候确实是他们策划怎么设计的,打出来就是什么样的,基本满足策划的需求、设计的想法。再加上可能因为是最高水平,反应非常快,所以人类反应跟不上,实际上很难打过它。
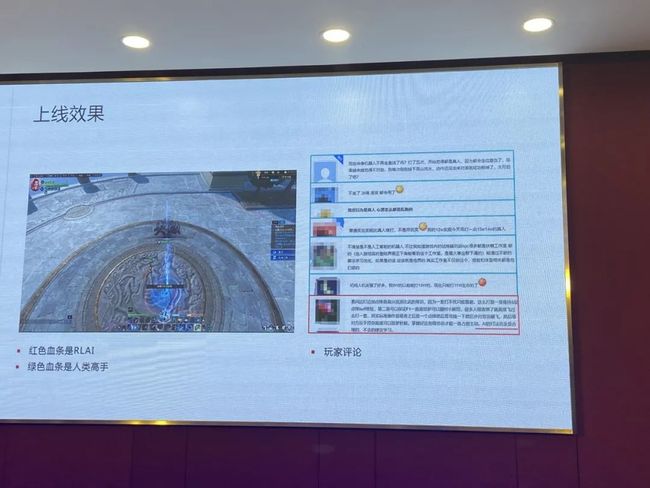
最终我们上线之后调了难度,不会让玩家体验到这个AI。我们调了之后在贴吧里关注了玩家的反馈,感觉整体上正面反馈远远大于负面反馈。整个策划开发团队对这样的AI效果也是比较满意的。
我们这个AI让玩家自己选择打,他挑战别人的时候也可以用AI,而且他也可以选择什么类型的AI。有了这样的AI之后,《逆水寒》1V1的代练就找不到了。

这是更多游戏上落地的效果,我们在格斗、棋牌,卡牌和体育游戏都有相关积累。这些AI已经上线部署了,现在就在用。右下角是正在测试的一款游戏,年底也是要上线的,这是其中的卡牌玩法。
游戏方比较重视这个玩法,原来不太好做,因为卡牌很多,也不太好测卡组的平衡性。后来AI测试的时候,基本上达到了玩家体验的时候的感觉。因为我们有酒馆,这个场景下,AI的使用率达到70%,30%是玩家之间打。具体来讲,第一是打我们的AI受挫感比较低,第二没有人知道他打AI输了。他在酒馆设计自己的套路和想法是非常适合的。

还有一些附加的效果,强化学习还能做一些什么事情?比如说刚刚讲的平衡性测试,我们在《逆水寒》里面做过,龙吟这个职业上线前做过一些平衡性测试,去看一下它跟其他职业整体对战的效果。
第一版给我们测之前,训完AI效果大概就是——这个职业碾压所有其他职业,而且碾压度非常高,是完虐型的打法。然后我们给开发组提供数据,给他们截了一些视频,他们看过之后做了一些数值、技能迭代。迭代完以后再测,测完后再给新版本。龙吟上线之后经历过三次版本,可以看到上线的效果,做种版本没有起初的那种碾压效果。
四
强化学习也有很多问题,比如拟人化的游戏AI。怎么解决这个问题,一种比较简单的想法:用专家数据进行模仿学习。这里有个很大的问题是需要数据,如果是“像人”的话,接受学习肯定需要大量的玩家数据。这里存在一个悖论,游戏对于AI最大的需求是游戏上线之后一开始那段时间,玩家不多的时候让AI活跃游戏。当然,像《王者荣耀》那样热门的游戏,可能AI的需求度没那么高,因为玩家之间所有的难度匹配都能满足需求。
而如果游戏还没上线,游戏刚开始的时候需要AI,我们数据从哪儿来?没有那么多的玩家,这是一个比较大的问题。

另外,采集数据的时候是需要预处理的,预处理工作量比较大。还有一个困难,“像人”是主观的,实际上我们发现它非常主观,每个人都有自己的想法,关于像人到底是什么也是非常大的问题,怎么样评价像人这样一个指标?我们能想到的一点,是让玩家测试,直接让玩家做一些黑箱测试,让他判断对面是人还是AI。但这个成本比较高,因为要请一些玩家测试。怎么样通过数据评价?这是比较难的问题。

还有一个问题在模型上线之前。模型是个神经网络,很多时候动作会输出一些不合人类逻辑、常识的行为出来。所以策划跟QA一般给会很多意见,AI上线之后,持续迭代的过程中也会给很多意见。怎么样把这些意见跟模型结合起来?这也是比较大的问题,也有点难。
比较简单的,可能我在流程图里面插一些规则,在某些策划的强制建议里面走强制建议就行了。但这个时候也会出现意想不到的情况,比如说模型的输出跟策划的输入是矛盾的。因为可能没法控制模型它到底是什么行为,它有自己的想法,还有可能是对的,只是不符合我们的认知而已,有可能会出这样的一些死循环。
还有另一个比较大的需求——就是不仅需要拟人化的高水平AI,还希望AI的打法多一些,提升玩家乐趣。我们做过尝试,在《逆水寒》中做了多样化的AI。比如说右边这三个神像,有三种完全不同的打法。平衡型的可能符合正常人的思路,还有激进型的、保守型的。我们这边的一些经验,是可以结合进化算法来做的,进化算法跟强化学习产生多种高水平的AI。进化算法比强化学习还高,这两种结合的要求会更高,成本可能会超出我们目前能够承受的门槛。
另外,其实进化算法也需要设定一些目标。我们可能一开始是激进也好,保守也好,都是对这个游戏有一定的理解的,知道某个游戏有什么样的风格才行。如果是完全不同的游戏,就需要专家给出解答。因为策划的表述,并不是直接转化成我们理解的、直接用在算法里的东西。
这是我今天所有的内容了。总的来说,我感觉强化学习技术还是挺棒的,能做很多事情。但是也有很多新的问题,我们也在持续的探索过程中。
我们团队在很多新问题上做方法的尝试,或者是性能、效果的提升。希望未来强化学习这个技术能在更多场景上——不只是游戏AI——还包括像自动化测试、关卡生成、关卡难度评价。我们确实看到它有这样的潜力,只不过真的要达到这种能力,还需要很多深入研究。
今天就先到这儿,谢谢!

推荐阅读
最新的游戏专业书上架啦!点击下方小程序即可获取
