学习资料

import requests
if __name__ == '__main__':
#step1:指定url
url='https://www.sogou.com/'
#step2:发起请求
#get方法会返回一个响应对象
res=requests.get(url=url)
#step3:获取相应数据.text返回的是以字符串形式的
page=res.text
print(page)
#step4:持久化存储
with open('./sogou.html','w',encoding='utf-8')as fp:
fp.write(page)
print("爬取数据结束")简单的网页采集器 搜索引擎
import requests
if __name__ == '__main__':
url='https://www.sogou.com/sie?'
#处理url携带的参数:封装到字典中
kw=input('enter a word:')
param={
'query':kw
}
#对指定url发起的请求是携带参数的url是携带参数的
res=requests.get(url=url,params=param)
passs=res.text
print(passs)
fileName=kw+'.html'
with open(fileName,'w',encoding='utf-8') as fp:
fp.write(passs.text)
print(fileName,'保存成功!!!!')
ps:输入空姐,则在网页中搜索空姐
搞定百度翻译
ajax 前端局部刷新
百度翻译,是post请求携带的参数
响应的是json数据
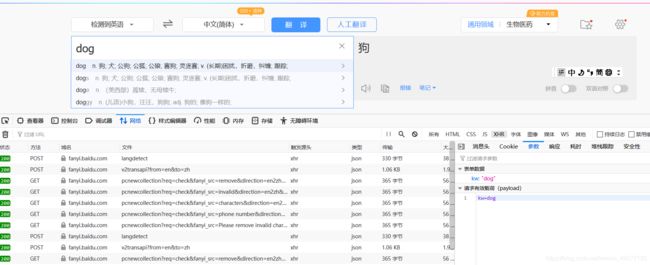
post请求要携带参数
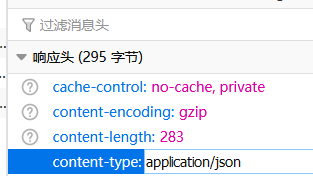
json数据
import requests
import json
if __name__ == '__main__':
#指定url链接
post_url='https://fanyi.baidu.com/sug'
#post请求参数处理(同get请求一致)
data={
'kw':'dog'
}
# 伪装一下浏览器
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0'}
#请求发送
res=requests.post(url=post_url,data=data,headers=headers)
#获取响应数据:json()方法返回一个obj(对象)(如果确认响应数据是json类型的,才可以使用JSON)
dic_obj=res.json()
print(dic_obj)
#持久化存储
fp=open('./dog.json','w',encoding='utf-8')
json.dump(dic_obj,fp=fp,ensure_ascii=False)#设置不存在字符模式
ps.可以自定义一个输入函数
爬取豆瓣电影中的详细数据
网址:https://movie.douban.com/j/chart/top_list?type=24&interval_id=100%3A90&action=&start=100&limit=20
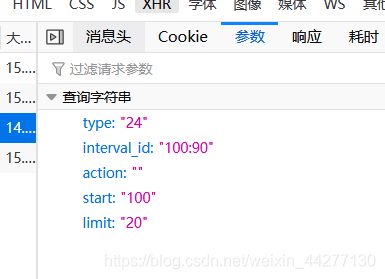
因为是json异步加载数据
import requests
import json
if __name__ == '__main__':
url='https://movie.douban.com/j/chart/top_list'
param={
"type": "24",
"interval_id": "100:90",
"action": "",
"start": "1",#从库中的第几部电影去取
"limit": "20",#一次取出的个数
}
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0'}
req=requests.get(url=url,params=param,headers=headers)
li_data=req.json()#json返回一个列表
fp=open('./douban.json','w',encoding='utf-8')
json.dump(li_data,fp=fp,ensure_ascii=False)#避免出现字符型数据
print('over!!!')练习肯德基餐厅查询
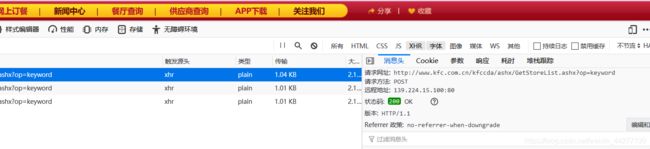

import requests
if __name__ == '__main__':
url='http://www.kfc.com.cn/kfccda/storelist/index.aspx'
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0'}
param={
"keyword": "青岛",
"pageIndex": "1",
"pageSize": "10",
}
response=requests.get(url=url,params=param,headers=headers)
list_data=response.text
print(list_data)
爬取化妆品管理信息平台url=http://scxk.nmpa.gov.cn:81/xk/
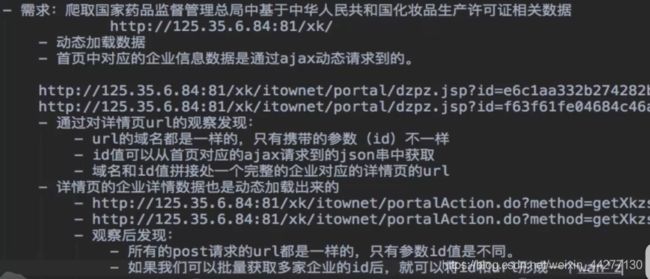
因为网页中有很多链接,每一个id代表一个公司的详细数据所以要访问每一个链接
先把所有的id打印出来
import requests
import json
if __name__ == '__main__':
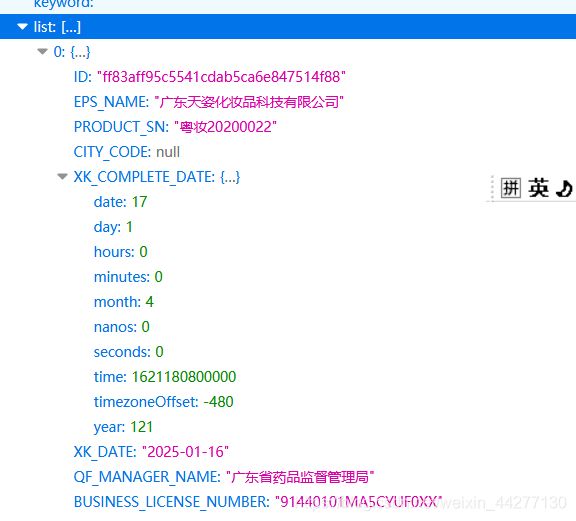
#批量获取不同企业的id值
url='http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsList'
#参数的封装
data={
"on":"true",
"page":"1",
"pageSize":"15",
"productName":"",
"conditionType":"1",
"applyname":"",
"applysn":"",}
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0'}
id_list = [] # 存储企业的id
json_ids=requests.post(url=url,headers=headers,data=data).json()
for dic in json_ids['list']:
id_list.append(dic['ID'])#append字典的添加
#获取企业详情数据
post_url='http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsById'
for id in id_list:
data={
'id':id
}
data_json=requests.post(url=post_url,data=data,headers=headers).json()
print(data_json,'----------------------------')