这篇博文是借助360开源的Floyd项目和百度开源的Braft项目来分析Raft的实现,至于Raft的理论(概念)和原理及一些问题点可以从下面的连接中获取,本身分析它是兴趣,利用周末时间来延伸自己的知识点,如有说的不正确,请指教哈,这篇估计要写一段时间,平时比较忙。
Floyd里有关多线程的东西使用了Pink实现,但在分析Raft的时候会简化它,不然东西比较多。我会按照网上的说明,把它至少分为三个部分来分析,第一部分是Leader选举,第二部分是日志复制,第三部分是安全性,可能关键代码比较多以及每个字段的作用。然后最后分析如何启动(框架),有几个线程,以及各个承担的职责。另外的Paxos挺复杂的,我也不准备去分析,微信团队也开源了一个类似的实现PhxPaxos,有兴趣的可自己分析下。
几个关键的字段作用结合下代码来分析比较好,每个节点使用FloydContext来描述该时刻的状态和一些数据:
34 struct FloydContext {
35 // Role related
36 explicit FloydContext(const Options& _options)
37 : options(_options),
38 voted_for_ip(""),
39 voted_for_port(0),
40 leader_ip(""),
41 leader_port(0),
42 vote_quorum(0),
43 commit_index(0),
44 last_applied(0),
45 last_op_time(0),
46 apply_cond(&apply_mu) {}
47
48 void RecoverInit(RaftMeta *raft);
49 void BecomeFollower(uint64_t new_iterm,
50 const std::string leader_ip = "", int port = 0);
51 void BecomeCandidate();
52 void BecomeLeader();
53
54 Options options;
55 // Role related
56 uint64_t current_term;
58 Role role;
59 std::string voted_for_ip;
60 int voted_for_port;
61 std::string leader_ip;
62 int leader_port;
63 uint32_t vote_quorum;
64
65 uint64_t commit_index;
66 std::atomic last_applied;
67 uint64_t last_op_time;
68
69 std::set members;
70
71 // mutex protect commit_index
72 // used in floyd_apply thread and floyd_peer thread
73 slash::Mutex global_mu;
74 slash::Mutex apply_mu;
75 slash::CondVar apply_cond;
76 };
current_term表示当前任期,role表示节点在该任期是处于什么状态,每个成员变量的作用从命名大概知道,不具体分析了。
19 void FloydContext::RecoverInit(RaftMeta *raft_meta) {
20 current_term = raft_meta->GetCurrentTerm();
21 voted_for_ip = raft_meta->GetVotedForIp();
22 voted_for_port = raft_meta->GetVotedForPort();
23 commit_index = raft_meta->GetCommitIndex();
24 last_applied = raft_meta->GetLastApplied();
25 role = Role::kFollower;
26 }
28 void FloydContext::BecomeFollower(uint64_t new_term,
29 const std::string _leader_ip, int _leader_port) {
30 // when requestvote receive a large term, then we transfer from candidate to follower
31 // then we should set voted_for_ip to the leader_ip
32 // if (current_term < new_term) {
33 voted_for_ip = _leader_ip;
34 voted_for_port = _leader_port;
35 // }
36 current_term = new_term;
37 leader_ip = _leader_ip;
38 leader_port = _leader_port;
39 role = Role::kFollower;
40 }
42 void FloydContext::BecomeCandidate() {
43 current_term++;
44 role = Role::kCandidate;
45 leader_ip.clear();
46 leader_port = 0;
47 voted_for_ip = options.local_ip;
48 voted_for_port = options.local_port;
49 vote_quorum = 1;
50 }
52 void FloydContext::BecomeLeader() {
53 role = Role::kLeader;
54 leader_ip = options.local_ip;
55 leader_port = options.local_port;
56 }
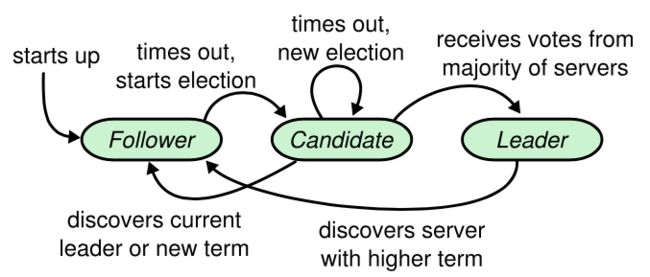
每个节点在同一时刻(任期term)只会有一种状态(Leader/Follower/Candidate),初始启动时,集群中的节点都为Follower,像current_term等是在RecoverInit中从rocksdb数据库中恢复(初始化的),每次状态变更都会涉及到成员变量的修改,至于如何从一个状态至另一个状转变的,先引用下转换图,然后从代码层面分析。
40 class FloydPrimary {
41 public:
42 FloydPrimary(FloydContext* context, PeersSet* peers, RaftMeta* raft_meta,
43 const Options& options, Logger* info_log);
44 virtual ~FloydPrimary();
45
46 int Start();
47 int Stop();
48 void AddTask(TaskType type, bool is_delay = true);
49 private:
50 FloydContext* const context_;
51 PeersSet* const peers_;
52 RaftMeta* const raft_meta_;
53 Options options_;
54 Logger* const info_log_;
55
56 std::atomic reset_elect_leader_time_;
57 std::atomic reset_leader_heartbeat_time_;
58 pink::BGThread bg_thread_;
59
60 // The Launch* work is done by floyd_peer_thread
61 // Cron task
62 static void LaunchHeartBeatWrapper(void *arg);
63 void LaunchHeartBeat();
64 static void LaunchCheckLeaderWrapper(void *arg);
65 void LaunchCheckLeader();
66 static void LaunchNewCommandWrapper(void *arg);
67 void LaunchNewCommand();
68
69 void NoticePeerTask(TaskType type);
74 };
这个线程主要的工作是做些心跳机制,状态转换等,Floyd启动的时候会先塞一个任务primary_->AddTask(kCheckLeader)主要是用于选择Leader,所有节点初始状态为Follower;
52 void FloydPrimary::AddTask(TaskType type, bool is_delay) {
59 switch (type) {
60 case kHeartBeat:
61 if (is_delay) {
62 uint64_t timeout = options_.heartbeat_us;
63 bg_thread_.DelaySchedule(timeout / 1000LL, LaunchHeartBeatWrapper, this);
64 } else {
65 bg_thread_.Schedule(LaunchHeartBeatWrapper, this);
66 }
67 break;
68 case kCheckLeader:
69 if (is_delay) {
70 uint64_t timeout = options_.check_leader_us;
71 bg_thread_.DelaySchedule(timeout / 1000LL, LaunchCheckLeaderWrapper, this);
72 } else {
73 bg_thread_.Schedule(LaunchCheckLeaderWrapper, this);
74 }
75 break;
76 case kNewCommand:
77 bg_thread_.Schedule(LaunchNewCommandWrapper, this);
78 break;
79 default:
81 break;
82 }
83 }
85 void FloydPrimary::LaunchHeartBeatWrapper(void *arg) {
86 reinterpret_cast(arg)->LaunchHeartBeat();
87 }
88
89 void FloydPrimary::LaunchHeartBeat() {
90 slash::MutexLock l(&context_->global_mu);
91 if (context_->role == Role::kLeader) {
92 NoticePeerTask(kNewCommand);
93 AddTask(kHeartBeat);
94 }
95 }
96
97 void FloydPrimary::LaunchCheckLeaderWrapper(void *arg) {
98 reinterpret_cast(arg)->LaunchCheckLeader();
99 }
101 void FloydPrimary::LaunchCheckLeader() {
102 slash::MutexLock l(&context_->global_mu);
103 if (context_->role == Role::kFollower || context_->role == Role::kCandidate) {
104 if (options_.single_mode) {
105 //code...
111 } else if (context_->last_op_time + options_.check_leader_us < slash::NowMicros()) {
112 context_->BecomeCandidate();
116 raft_meta_->SetCurrentTerm(context_->current_term);
117 raft_meta_->SetVotedForIp(context_->voted_for_ip);
118 raft_meta_->SetVotedForPort(context_->voted_for_port);
119 NoticePeerTask(kHeartBeat);
120 }
121 }
122 AddTask(kCheckLeader);
123 }
124
125 void FloydPrimary::LaunchNewCommandWrapper(void *arg) {
126 reinterpret_cast(arg)->LaunchNewCommand();
127 }
125 void FloydPrimary::LaunchNewCommandWrapper(void *arg) {
126 reinterpret_cast(arg)->LaunchNewCommand();
127 }
128
129 void FloydPrimary::LaunchNewCommand() {
131 if (context_->role != Role::kLeader) {
133 return;
134 }
135 NoticePeerTask(kNewCommand);
136 }
140 void FloydPrimary::NoticePeerTask(TaskType type) {
141 for (auto& peer : (*peers_)) {
142 switch (type) {
143 case kHeartBeat:
146 peer.second->AddRequestVoteTask();
147 break;
148 case kNewCommand:
151 peer.second->AddAppendEntriesTask();
152 break;
153 default:
156 }
157 }
158 }
其中心跳检查也做了些投票逻辑(没有分开),具体代码如上,没有多少难点,能做什么是取决于是什么状态。
其中check_leader_us这个值在每个节点是不相同的:check_leader_us = std::rand() % 2000000 + check_leader_us,引用一段话“服务器启动时初始状态都是follower,如果在超时时间内没有收到leader发送的心跳包,则进入candidate状态进行选举,服务器启动时和leader挂掉时处理一样。为了避免选票瓜分的情况,raft利用随机超时机制避免选票瓜分情况。选举超时时间从一个固定的区间随机选择,由于每个服务器的超时时间不同,则leader挂掉后,超时时间最短且拥有最多日志的follower最先开始选主,并成为leader。一旦candidate成为leader,就会向其他服务器发送心跳包阻止新一轮的选举开始。”简来说,随机化超时时间检查,检查时间大概是 [3s, 5s)。
代码行101〜123就是判断有没有超时,超时的话从kFollower转换为kCandidate,BecomeCandidate函数要做的事就是增加当前的任期数,给自己投一票,然后通过心跳机制的方式向其他节点请求投票,并再次AddTask(kCheckLeader),进行下一轮检查(超时后),来看一下AddRequestVoteTask主要做了什么,以及当其他节点收到心跳后的处理,这里为了使分析更简单,假设有A/B两个节点,A向B进行请求投票AddRequestVoteTask,此时A的某个工作线程进行了RequestVoteRPC[不考虑异步回调的事件]
93 void Peer::RequestVoteRPC() {
94 uint64_t last_log_term;
95 uint64_t last_log_index;
96 CmdRequest req;
97 {
98 slash::MutexLock l(&context_->global_mu);
99 raft_log_->GetLastLogTermAndIndex(&last_log_term, &last_log_index);
100
101 req.set_type(Type::kRequestVote);
102 CmdRequest_RequestVote* request_vote = req.mutable_request_vote();
103 request_vote->set_ip(options_.local_ip);
104 request_vote->set_port(options_.local_port);
105 request_vote->set_term(context_->current_term);
106 request_vote->set_last_log_term(last_log_term);
107 request_vote->set_last_log_index(last_log_index);
消息协议使用了google的pb,这个线程会把自己的当前任期数,ip/port,以last_log_term和last_log_index,发给其他节点SendAndRecv[后面两个字段的作用和何时修改,会在后面分析];
B节点的工作线程收到请求后,进行了如下处理:
89 case Type::kRequestVote:
90 response_.set_type(Type::kRequestVote);
91 floyd_->ReplyRequestVote(request_, &response_);
92 response_.set_code(StatusCode::kOk);
93 break;
714 int FloydImpl::ReplyRequestVote(const CmdRequest& request, CmdResponse* response) {
715 slash::MutexLock l(&context_->global_mu);
716 bool granted = false;
717 CmdRequest_RequestVote request_vote = request.request_vote();
718 /*
719 * If RPC request or response contains term T > currentTerm: set currentTerm = T, convert to follower (5.1)
720 */
721 if (request_vote.term() > context_->current_term) {
722 context_->BecomeFollower(request_vote.term());
723 raft_meta_->SetCurrentTerm(context_->current_term);
724 }
725 // if caller's term smaller than my term, then I will notice him
726 if (request_vote.term() < context_->current_term) {
727 BuildRequestVoteResponse(context_->current_term, granted, response);
728 return -1;
729 }
730 uint64_t my_last_log_term = 0;
731 uint64_t my_last_log_index = 0;
732 raft_log_->GetLastLogTermAndIndex(&my_last_log_term, &my_last_log_index);
733 // if votedfor is null or candidateId, and candidated's log is at least as up-to-date
734 // as receiver's log, grant vote
735 if ((request_vote.last_log_term() < my_last_log_term) ||
736 ((request_vote.last_log_term() == my_last_log_term) && (request_vote.last_log_index() < my_last_log_index))) {
737 BuildRequestVoteResponse(context_->current_term, granted, response);
738 return -1;
739 }
740
741 if (vote_for_.find(request_vote.term()) != vote_for_.end()
742 && vote_for_[request_vote.term()] != std::make_pair(request_vote.ip(), request_vote.port())) {
743 BuildRequestVoteResponse(context_->current_term, granted, response);
744 return -1;
745 }
746 vote_for_[request_vote.term()] = std::make_pair(request_vote.ip(), request_vote.port());
747 context_->BecomeFollower(request_vote.term());
748 raft_meta_->SetCurrentTerm(context_->current_term);
749 raft_meta_->SetVotedForIp(context_->voted_for_ip);
750 raft_meta_->SetVotedForPort(context_->voted_for_port);
751 // Got my vote
752 GrantVote(request_vote.term(), request_vote.ip(), request_vote.port());
753 granted = true;
754 context_->last_op_time = slash::NowMicros();
755 BuildRequestVoteResponse(context_->current_term, granted, response);
756 return 0;
757 }
以上的就是收到请求投票的节点处理,分为以下几种情况:
1)如果B的任期数小于A,则B变为kFollower,如果B的任期数大于A,则拒绝投票,因为只有最新的Candidate才有可能成为Leader;
2)如果request_vote.last_log_term() < my_last_log_term,或者((request_vote.last_log_term() == my_last_log_term) && (request_vote.last_log_index() < my_last_log_index)),则拒绝投票;
3)然后判断该term内是否对同一个节点进行了重复投票;
代码行746〜755进行投票,并修改状态;
my_last_log_index 和my_last_log_term表示节点的最新日志条目的索引值和当时的任期值,主要是为了安全性考虑,如果没有这两个字段参与的条件判断,那成为leader的那个节点可能没有最新的日志,term最大并不能解决这个问题,具有最新最全日志的server的才有资格去竞选当上Leader,并且根据任期号可以判断一条日志的新旧程度。
A收到投票响应后,进行了如下处理:
128 if (res.request_vote_res().term() > context_->current_term) {
129 context_->BecomeFollower(res.request_vote_res().term());
130 raft_meta_->SetCurrentTerm(context_->current_term);
131 raft_meta_->SetVotedForIp(context_->voted_for_ip);
132 raft_meta_->SetVotedForPort(context_->voted_for_port);
133 return;
134 }
135 if (context_->role == Role::kCandidate) {
136 if (res.request_vote_res().vote_granted() == true) { // granted
137 if (CheckAndVote(res.request_vote_res().term())) {
138 context_->BecomeLeader();
139 UpdatePeerInfo();
140 primary_->AddTask(kHeartBeat, false);
141 }
142 } else {
143 context_->BecomeFollower(res.request_vote_res().term());
144 raft_meta_->SetCurrentTerm(context_->current_term);
145 raft_meta_->SetVotedForIp(context_->voted_for_ip);
146 raft_meta_->SetVotedForPort(context_->voted_for_port);
147 }
148 } else if (context_->role == Role::kFollower) {
149 } else if (context_->role == Role::kLeader) {
150 }
151 }
152 return;
代码行128〜134判断自己的任期数是否小于对端的,是的话则自己变为kFollower;因为是异步请求投票,所以在收到某个节点的投票响应后,此时的节点状态可能已经发生变化了,故在检查时,需要结合节点当前的状态;
如果是kCandidate,然后检查当前任期内的投票数是否大于一定的数,如果满足则变为kLeader,并且
72 void Peer::UpdatePeerInfo() {
73 for (auto& pt : (*peers_)) {
74 pt.second->set_next_index(raft_log_->GetLastLogIndex() + 1);
75 pt.second->set_match_index(0);
76 }
77 }
然后每个follower进行AddAppendEntriesTask,具体做了什么下次分析。
65 bool Peer::CheckAndVote(uint64_t vote_term) {
66 if (context_->current_term != vote_term) {
67 return false;
68 }
69 return (++context_->vote_quorum) > (options_.members.size() / 2);
70 }
如果是kFollower或者kLeader,啥也不做。
补充一下,见代码行135〜140,在Server成为新Leader后,会立刻AddTask,写一条NOP日志,之后才能提供服务,主要是为了安全性考虑,下一篇会把这个坑填上。
下面几个链接是我在分析源码时,所做的一些参考,最后三个是一些相关的应用,包括优化方案,原始Raft论文里的实现性能并不怎么好。
参考:
https://github.com/maemual/raft-zh_cn/blob/master/raft-zh_cn.md
https://www.cnblogs.com/katsura/p/6549344.html
https://yq.aliyun.com/articles/62425
https://www.jianshu.com/p/4711c4c32aab
https://www.jianshu.com/p/2a2ba021f721
https://www.jianshu.com/p/ee7646c0f4cf
https://yq.aliyun.com/articles/398232?spm=a2c4e.11153940.blogcont62425.18.1e944bd0b1UuMv
https://yq.aliyun.com/articles/398237?spm=a2c4e.11153940.blogcont62425.19.1e944bd0b1UuMv
https://pingcap.com/blog-cn/#Raft
https://www.zhihu.com/question/54997169
https://zhuanlan.zhihu.com/p/25735592