求取scores最近邻的方法之二开始新的实践Chorus
问题来源:博文1,参考:博文2,博文3,博文4,请保持关注,并请持续关注。本文依旧粉丝可见。
这个问题一直贯穿我假期种地的时光,一直想着,似乎成了我一个心病,想着用faiss解决,但若对shape为(10000,40000)甚至是(1万,10万),更是(1万,100万),(1万,千万)都是可能的,这里将item的类别各自成一类,是多分类问题,按道理说在图像的识别、检测中应该也有同样的问题啊,难道说种类还不够多??有咩有10万级别的物体检测(Object Detection)?这个问题就会很明显了吧??
针对1万行高维度数据,查找其最近邻,这是很大的问题,问题在乎1万行,假设1行需要0.001s,1万行也有10s了,这个行数就是用户数量,如果有千万级别的用户,OK,1万s !!!!这是很费劲的,所以召回是很难在1h内更新完成的。
【阅读此文,请先站在我立场想这个问题,或者请你直接告诉我如何避免这个问题】
然而实际上并不行啊,真是人生何处不艰难啊!
For Video Recommendation in Deep learning QQ Group 277356808
视频推荐深度学习加这个群
For Visual in deep learning QQ Group 629530787
视觉深度学习加这个,别加错
I'm here waiting for you
别加那么多,没必要,另外,不接受这个网页的私聊/私信!!!
采用博文3的方法根本不行啊,如下结果,原因在于 其对这种相差不大的1维数据很难求得准确的结果
[[99999 99985 99984 99990 99996 99998 99995 99993 99976 99979 99987 99981
99982 99973 99969 99972 99978 99977 99980 99997 99986 99994 99992 99991
99983 99988 99989 99975 99970 99956 99964 99953 99961 99967 99950 99966
99952 99947 99957 99960 99955 99963 99965 99958 99971 99968 99974 99938
99943 99949 99954 99941 99944 99946 99951 99948 99962 99959 99942 99935
99927 99932 99937 99940 99945 99921 99929 99924 99931 99939 99934 99926
99936 99933 99920 99923 99925 99930 99918 99915 99928 99914 99919 99922
99917 99912 99909 99906 99913 99911 99916 99898 99905 99910 99907 99908
99903 99904 99897 99902]]
[[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 1024. 1024. 1024. 1024. 1024. 1024.
1024. 1024. 1024. 1024. 1024. 1024. 1024. 1024. 1024. 1024.
1024. 1024. 1024. 1024. 2048. 2048. 2048. 2048. 2048. 2048.
2048. 2048. 2048. 2048. 2048. 2048. 2048. 3072. 3072. 3072.
3072. 3072. 3072. 3072. 3072. 3072. 3072. 3072. 4096. 4096.
4096. 4096. 4096. 4096. 4096. 5120. 5120. 5120. 5120. 5120.
5120. 5120. 5120. 5120. 6144. 6144. 6144. 6144. 6144. 6144.
6144. 7168. 7168. 7168. 7168. 7168. 8192. 8192. 8192. 8192.
8192. 9216. 9216. 9216. 9216. 9216. 9216. 10240. 10240. 10240.]]
刻度值太大,所以这种faiss是失败的。我能咋办?多看几个实践吧,比如Chorus
Chorus开始了。
1-多个参数的输入,这里有点混乱,个人不建议这种输入方法,多个argparse,很容易搞晕。
打印第一个结果,并复现错误原因。
model_name = eval('{0}.{0}'.format(init_args.model_name))
reader_name = eval('{0}.{0}'.format(model_name.reader))
runner_name = eval('{0}.{0}'.format(model_name.runner))
init_args Namespace(model_name='Chorus')
model_name
reader_name
runner_name
已经将models,helper去掉了,所以这种玩意不对。
修改为如下即可:逢山开路,遇水架桥,将代码改为自己熟悉的格式才是读懂代码。
class Chorus():
pass
init_parser = argparse.ArgumentParser(description='Model')
init_parser.add_argument('--model_name', type=str, default='BPR', help='Choose a model to run.')
init_args, init_extras = init_parser.parse_known_args()
print("init_args ",init_args)
print(type(Chorus))
model_name = eval('{}'.format(init_args.model_name))
print("model_name ",model_name)2-需要先进行预训练,再进行再次训练
python main.py --model_name Chorus --emb_size 64 --margin 1 --lr 5e-4 --l2 1e-5 --check_epoch 10 --epoch 50 --early_stop 0 --batch_size 512 --dataset 'Grocery_and_Gourmet_Food' --stage 1
python main.py --model_name Chorus --emb_size 64 --margin 1 --lr_scale 0.1 --lr 1e-3 --l2 0 --check_epoch 10 --dataset 'Grocery_and_Gourmet_Food' --base_method 'BPR' --stage 2第一个训练LR尽可能小点,第二个也不要太大。
以我目前短浅认识,这个应该在item点击序列大的时候比较复杂,明天看看怎么生成数据。下班。
ReChorus这个文章在此。
其中一个图非常有用,这就是关联及长短期兴趣的情况。
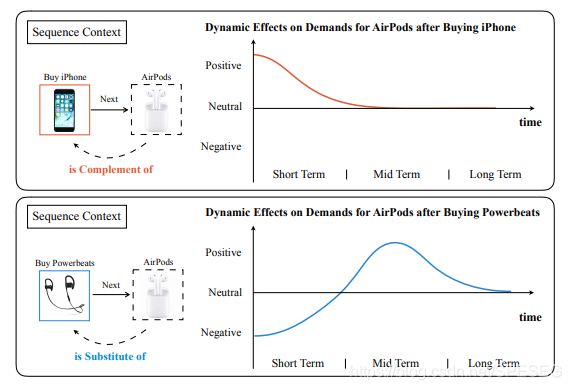
序列背景,当买了iPhone手机后,购买互补的产品airpod耳机的可能性在短期内很大,长期如果不买就一般不会买了。而当购买powerbeat耳机后短期内不会买类似的东西(airpod耳机)了,中期可能会感兴趣,比如耳机坏了、丢了等,都可能会买新类型的。其中手机与耳机是互补的,而airpod与powerbeat是可替代的产品(类似的),这种兴趣随长短期的变化在电商中应该很有效。不知道在信息流中效果如何?下面看看训练数据的构造。
Chorus模型兼顾item相关及时间动态变化,目的在于得到目标item的embedding,方法是采用knowledge-aware和time-aware方式。
3-问题定义
对于一个user u,其点击行为序列时间顺序![]() ,R定义为所有item的相关性,因此有
,R定义为所有item的相关性,因此有
![]() ,M 是item的个数,如果item i和j hold(有关系的意思,下文可知代表互补),则
,M 是item的个数,如果item i和j hold(有关系的意思,下文可知代表互补),则![]() ,否则为0,相关性r可以是互补、可替代等等
,否则为0,相关性r可以是互补、可替代等等
因此item之间组成三元组,(i,r,j)例如,(AirPods,is_complement_o f ,iPhone),但不能反过来说,而是 iPhone is not a complement of AirPods ,因此知识图(knowledge graph)是有方向的。
为了引入相关图的结构信息,需要得到item相关性的语义embedding。在所有的embedding方法中,translation-based的方法是有效和有用的。The inherent idea is embedding items and relations into the same latent space and finding a translation function to minimize the scoring function:本质idea是嵌入item和相关到同样隐空间,寻找一个转换函数最小化评分函数。
![]()
D是评价函数,度量距离(通常是L2距离)用。Trans是任意的转换函数,可以是简单的转换操作,也可为特殊定义的NN。有很多工作用来扩展转换函数的能力,比如TransE、TransH、TransR等,第一个是TransE(i,r)=i+r,L2距离度量则为
![]()
为了学习item和相关的embedding从相关图中,采用margin-based loss,简而言之就是一个loss,公式如下
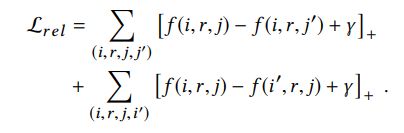
对于每个三元组,最后一个item被随机采样的item j'代替,为了确保 (i,r,j')在知识图中不被观测到,类似的,第一个item被i'代替,因此(i',r,j)不相关。这个目标函数的目的是从所有(corrupted ones)items对中区别观察到的三元组,embedding将会被强制保持item之间的相关性。
For Video Recommendation in Deep learning QQ Group 277356808
4-基本模型
BPR(贝叶斯个性化排序)是广泛应用的矩阵分解方法,GMF(Generalized Matrix Factorization)也是基于NN的较好的模型。
以此作为base model验证我们方法的有效性。
简单回顾下两个CF方法,CF假设相似的user喜欢相似的items。对于BPR,对每个user和item有k维度的隐因子向量,rank score计算如下:
![]() 后面两个分别对每个user和item的偏置。
后面两个分别对每个user和item的偏置。
对于GMF,rank score通过多层NN得到,可表示为:
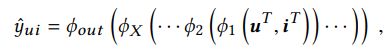 一共有x层CF层。
一共有x层CF层。
为了学习模型参数,pair-wise rank loss可以如下得到:
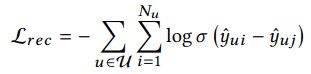
其中是sigmoid函数,j不是user的点击,而是从其他训练实例中随机采样的一个。
5-Chorus模型
两阶段模型,将item相关及随时间变化的效应整合到一起。下面是两个阶段的展示,第一阶段是相关性拟合,图嵌入用来将item的相关性结构信息进行编码到embedding,很多上面提到的translation方法可以灵活的用来平衡此处。相关性图嵌入embedding将用来得到基本的相关的表达。
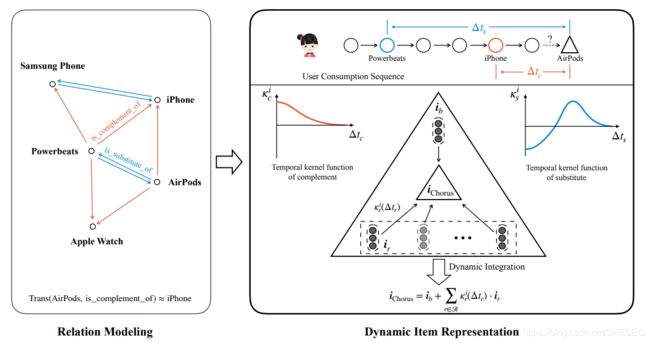
第一阶段图中,airpod耳机与powerbeat耳机是同样的(可替代的),powerbeat是iPhone手机的组成部分(互补的关系)。因此通过转换,基本上(约等于)airpod是iPhone的互补。
第二阶段有两个关键模块,动态整合和时间核函数设计
首先,每个item将得到|R|相关的表达,包括基于转换函数的基本的一个,这个定义了目标item的表达,当在背景中作为不同的角色。然后,这些表达将按照是否有相关的消费(在历史点击序列中)进行动态整合。为将每个相关的时间动态包含,提出相关-特定时间核函数 控制效果的两极化和强度。因此,相关的表达对最终item embedding的贡献在不同背景(点击序列)中是不同的,这就是知识意识的动态item embedding。最后,这种提升的item embedding可用来平衡很多算法计算rank score,并做推荐。下面详细阐述第二阶段:
动态整合:
定义基本表达![]() 对应的相关为
对应的相关为![]() ,基本表达编码item固有特性用于初始化
,基本表达编码item固有特性用于初始化![]() ,转换函数则得到相关的表达。
,转换函数则得到相关的表达。
![]() 其中
其中![]() 是相关embedding,采用这种方法将相关的表达按照每个相关整合语义信息。
是相关embedding,采用这种方法将相关的表达按照每个相关整合语义信息。
【注意:本文有两个词容易混淆,relation及relational,前者翻译为相关,后者是相关的,如果分不清,请看原文】
【在我看来![]() 是其中的相关性,比如上文的互补、可替代的,表示item之间的关系,这里也是embedding的形式】
是其中的相关性,比如上文的互补、可替代的,表示item之间的关系,这里也是embedding的形式】
在得到基本和相关的item表达后,重点放在如何它们按照不同背景联合起来。这是我们Chorus模型的核心idea。注意这里相关的表达是知识意识的,但仍旧是静态的。目的是得到一个背景意识的系数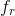 对每个相关的表达——反映实际的影响度(在当前背景中)。最终的背景意识和知识意识的item embedding 表示为:
对每个相关的表达——反映实际的影响度(在当前背景中)。最终的背景意识和知识意识的item embedding 表示为:
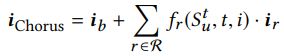
包括两部分,基本的item表达和系数化的相关的部分(第二项),其中背景(历史点击序列![]() ,时间t,目标item i)充当系数的输入,下面将关注如何由背景得到合理系数。
,时间t,目标item i)充当系数的输入,下面将关注如何由背景得到合理系数。
【翻译的好累啊,下班,明天再说吧】
直观上,一些相关的表达可能没有作用或者有副作用,在某些case中。下图示例这些表达对不同背景下最终的embedding的贡献。三角形的三个角代表目标item的不同表达。
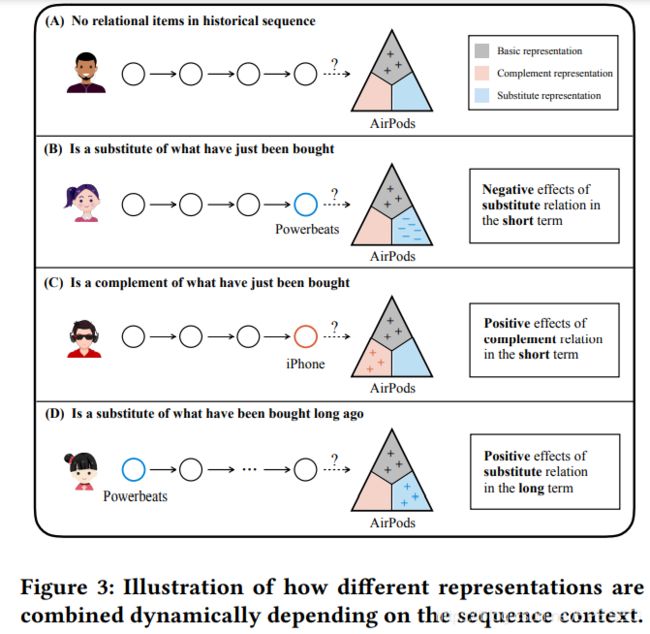
当历史序列中没有相关的item(互补或可替代等),那么最终的item embedding就是基本的item表达,另外两个相关的表达没有作用(分别是红色互补,蓝色可替代),如BC分别是负作用和正作用。
为了整合不同相关的时间动态,对每个相关做时间核函数,这是对消费延迟时间的连续函数。时间核函数目的是控制之前相关的消费的影响度。假设已经获得时间核函数k,那么fr可以得到:
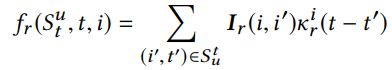
因此,Chorus embedding可以更好的捕获在不同背景下的item含义,也因而更好的拟合用户需求随时间的变化。
为了简化和效果,考虑最后一个相关的item,得到:

下面设计时间核函数,一方面可以按照每个相关特性来设计。比如最上面图的短期互补则是正作用,这种作用随时间衰减。另一方面,可根据系统的主观需要来做。如果在短期内需要可替代的item出现在推荐列表中,时间核函数可以设计为正的初始值,衰减很快。本文工作,集中考虑两个相关:互补、可替代。
对于互补,考虑0均值的正态分布,而不是指数分布(衰减太快)
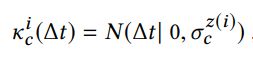
![]() 是均值为u,sigma为标准差的dt 的正态分布。
是均值为u,sigma为标准差的dt 的正态分布。![]() 与item的类别z相关。
与item的类别z相关。
对于可替代,影响作用期望从负的变成正的,因为短期内不会需要类似的东西,但当它的寿命终结了就需要。因而,采用两个相对的正态分布拟合这种特性:
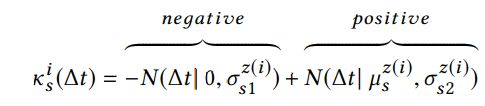
因为刚买过可替代的东西,肯定不会买类似的东西,所以这时是最不需要,所以是0均值代表最强烈,正态分布如下-y
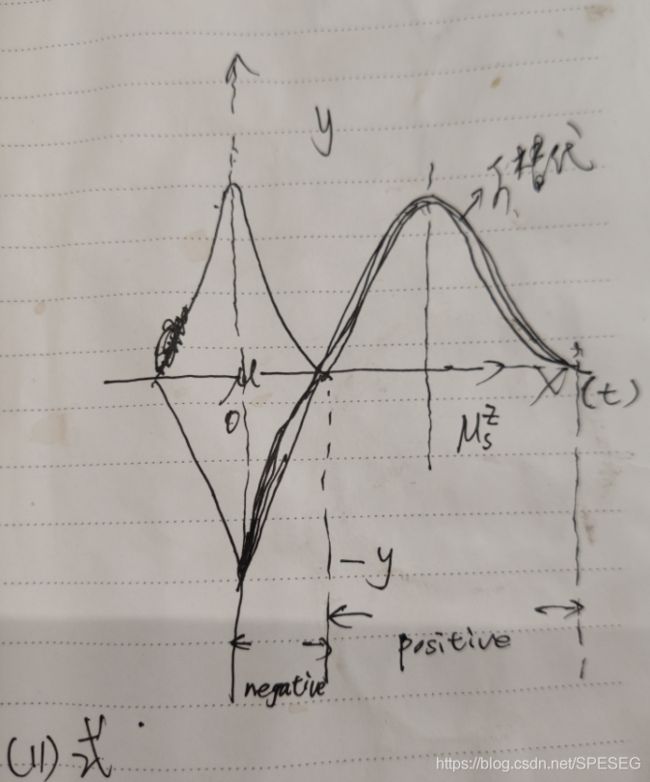
其实这种曲线在第一个图,第二个图中已经表明了。也可设计其他形式的相关或者核函数,比如同一名牌,同一厂家
6-训练及参数学习
第一阶段优化Loss margin学习结构信息得到item和相关 embedding。第二阶段优化L rec
作者所用的第一个数据集

其中item meta为如下格式:

开发集和测试集为:
训练集就是点击日志:
评价指标为HR和NDCG,可参考我的其他博文。
为了对比方便,全部采用的64D embedding。对比结果如下:

就这样吧,其中item_meta数据中相关难构造,这就给模型应用带来了一定麻烦。
但我目的是为了解决score倒排问题,所以先看作者是如何实现这一步的,有没有什么方法避免,当然本文数据集数据量真的小。
拜拜。