数仓特征:面向主题,集成,非易失的,时变。数据仓库是在数据库已经大量存在的情况下,为了进一步挖掘数据资源、为了决策需要而产生的,不是所谓的“大型数据库”。
数据库与数据仓库的区别(OLTP 与 OLAP 的区别)
操作型处理,叫联机事务处理 OLTP(On-Line Transaction Processing,),也可以称面向交易的处理系统,它是针对具体业务在数据库联机的日常操作,通常对少数记录进行查询、修改。用户较为关心操作的响应时间、数据的安全性、完整性和并发支持的用户数等问题。传统的数据库系统作为数据管理的主要手段,主要用于操作型处理。
分析型处理,叫联机分析处理 OLAP(On-Line Analytical Processing)一般针对某些主题的历史数据进行分析,支持管理决策。
ETL:抽取 Extra, 转化 Transfer, 装载 Load。
为什么要对数仓分层?
分层:Ods、Dw、Dm、Ads
用空间换时间,通过大量的预处理来提升应用系统的用户体验(效率),因此数据仓库会存在大量冗余的数据;不分层的话,如果源业务系统的业务规则发生变化将会影响整个数据清洗过程,工作量巨大。
数仓元数据管理
元数据(Meta Date), 主要记录数据仓库中模型的定义、各层级间的映射关系、监控数据仓库的数据状态及 ETL 的任务运行状态。可分为技术元数据和业务元数据。
元数据不仅定义了数据仓库中数据的模式、来源、抽取和转换规则等,而且是整个数据仓库系统运行的基础,元数据把数据仓库系统中各个松散的组件联系起来,组成了一个有机的整体。
Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类 SQL 查询功能。 本质是将 SQL 转换为 MapReduce 程序。利用HDFS 存储数据,利用 MapReduce 查询分析数据。

组件:用户接口,元数据存储mysql / derby,解释、编译、优化、执行器。
与数据库的区别
- 数据存储位置不同:Hive存储在HDFS中,数据库存储在块设备或本地文件
- 数据更新:数仓一般不改写数据,数据库增删改查
- 执行延迟:Hive延迟高, mysql延迟低, 只有大规模数据时Hive并行计算的优点才会体现
- 数据规模:Hive大规模计算,数据库规模较小
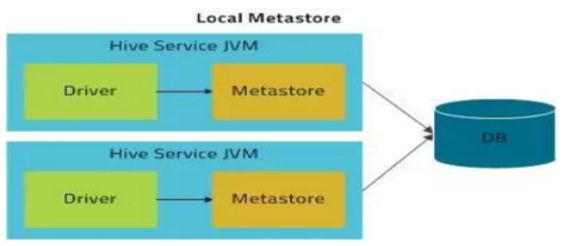
三种配置模式(本地模式、远程模式与mysql是否在远程无关!!!)
- 内嵌模式:使用的是内嵌的Derby数据库来存储元数据,也不需要额外起Metastore服务。
- 本地模式:
本地模式采用外部数据库来存储元数据,目前支持的数据库有:MySQL、Postgres、Oracle、MS SQL Server.
不需要单独起metastore服务,用的是跟hive在同一个进程里的metastore服务。也就是说当你启动一个hive 服务,里面默认会帮我们启动一个metastore服务。hive根据hive.metastore.uris 参数值来判断,如果为空,则为本地模式。
缺点:每启动一次hive服务,都内置启动了一个metastore。本地模式下hive的配置主需要指定mysql的相关信息即可。(ConnectionURL)
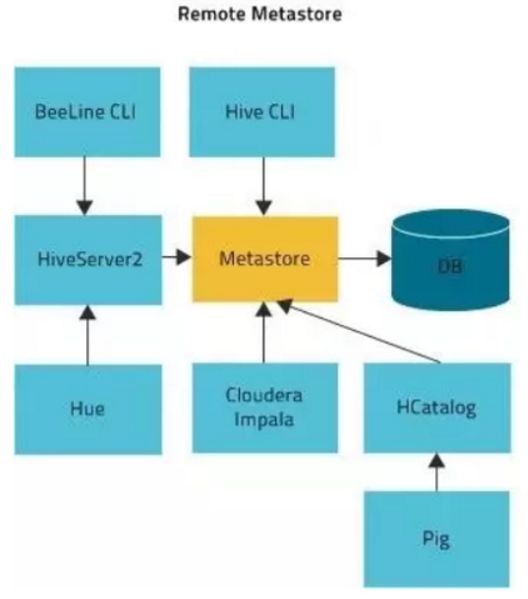
- 远程模式:
需要单独起metastore服务,然后每个客户端都在配置文件里配置连接到该metastore服务。远程模式的metastore服务和hive运行在不同的进程里。
在生产环境中,建议用远程模式来配置Hive Metastore。其他依赖hive的软件都可以通过Metastore访问hive。
远程模式下,需要配置hive.metastore.uris 参数来指定metastore服务运行的机器ip和端口,并且需要单独手动启动metastore服务。
数据模型
- db(库):在 hdfs 中表现为 hive.metastore.warehouse.dir 目录下一个文件夹
- table(内部表):在 hdfs 中表现所属 db 目录下一个文件夹,当我们删除一个内部表时,Hive也会删除这个表中数据。内部表不适合和其他工具共享数据。
- external table(外部表):数据存放位置可以在 HDFS 任意指定路径 ,删除该表并不会删除掉原始数据,删除的是表的元数据
- partition(分区):在 hdfs 中表现为 table 目录下的子目录
DDL操作:
1 create table t_user_part(id int,name string,country string) 2 partitioned by (guojia string) 3 row format delimited fields terminated by ',' ; 4 --注意顺序问题 5 --分区的字段不能是表当中的字段 6 7 load data local inpath './root/4.txt' 8 into table t_user_part partition (guojia='usa'); 9 10 load data local inpath '/root/5.txt' 11 into table t_user_part partition (guojia='china'); 12 --将数据加载到哪个文件夹中 13 14 --多级分区 15 create table t_order(id int,pid int,price double) 16 partitioned by (year string,month string,day string) 17 row format delimited fields terminated by ',' ; 18 19 load data local inpath '/root/5.txt' 20 into table t_order partition (year='2019',month='09',day='18'); 21 22 load data local inpath '/root/4.txt' 23 into table t_order partition (year='2019',month='09',day='18'); 24 25 ALTER TABLE t_user_part ADD PARTITION (guojia='riben') 26 location '/user/hive/warehouse/hadoop32.db/t_user_part/guojia=riben'; 27 --一次添加一个分区 28 29 ALTER TABLE order ADD 30 PARTITION (year='2018', month='09',day="20") 31 location'/user/hive/warehouse/hadoop32.db/t_order' 32 PARTITION (year='2019', month='09',day="20") 33 location'/user/hive/warehouse/hadoop32.db/t_order'; 34 --一次添加多个分区 35 36 --删除分区 37 ALTER TABLE t_user_part DROP IF EXISTS PARTITION (guojia=riben); 38 39 --查看分区 40 show partitions table_name; 41 42 show formatted table_name;
- bucket(分桶):在 hdfs 中表现为同一个表目录下根据 hash 散列之后的多个文件 ,采用对列值哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶当中
DDL操作:
1 create table stu_buck(Sno string,Sname string, 2 Sbrithday string, Sex string) 3 clustered by(Sno) 4 into 4 buckets 5 row format delimited fields terminated by '\t'; 6 --clustered by 根据哪个字段去分桶,这个字段在表中一定存在 7 --into N buckets 分多少个文件 8 --如果该分桶字段是string,会根据字符串的hashcode % bucketsNum 9 --如果该分桶字段是数值类型,数值 % bucketsNum 10 11 create table student(Sno string,Sname string, 12 Sbrithday string, Sex string) 13 row format delimited fields terminated by '\t'; 14 --insert+select 15 insert overwrite table stu_buck select * from student 16 cluster by(Sno); 17 --默认不让直接使用分桶表
DML操作
1 --load加载 推荐方式,最常见 (分桶表是不支持load) 2 load data local inpath '/root/hivedata/students.txt' 3 overwrite into table student; 4 --加载本地数据到表对应的路径下 5 --local表明是本地还是hdfs 6 --overwrite表示覆盖操作(慎用) 7 8 load data inpath '/stu' into table student_ext; 9 --加载hdfs上的文件到表对应的路径下(追加) 10 11 --insert + select导入 12 --insert 主要是结合 select 查询语句使用,将查询结果插入到表中 13 insert overwrite table tablename1 14 [partition (partcol1=val1,partclo2=val2)] 15 select_statement1 from source_table 16 17 --多重插入 18 from source_table 19 insert overwrite table tablename1 20 [partition (partcol1=val1,partclo2=val2)] 21 select_statement1 22 insert overwrite table tablename2 23 [partition (partcol1=val1,partclo2=val2)] 24 select_statement2.. 25 26 --动态插入 substr(day,1,7) as month,day分区的虚拟字段 顺序需要对应 27 insert overwrite table d_p_t partition (month,day) 28 select ip,substr(day,1,7) as month,day 29 from dynamic_partition_table; 30 31 --指定分隔符(复杂类型的数据表) 32 --表1(包含array字段类型) 33 --数据: zhangsan beijing,shanghai,tianjin,hangzhou 34 -- wangwu shanghai,chengdu,wuhan,haerbin 35 create table complex_array(name string, 36 work_locations array<string>) 37 row format delimited fields terminated by '\t' 38 collection items terminated by ','; 39 --collection items array集合分隔符 40 41 --表2(包含map字段类型) 42 create table t_map(id int,name string,hobby map<string,string>) 43 row format delimited 44 fields terminated by ',' 45 collection items terminated by '-' 46 map keys terminated by ':' ; 47 --map keys map中k-v分隔符 48 --数据:1,zhangsan,唱歌:非常喜欢-跳舞:喜欢-游泳:一般般 49 -- 2,lisi,打游戏:非常喜欢-篮球:不喜欢
DQL操作
4个By区别
Sort By:分区内有序,只保证每个 reducer 的输出有序,不保证全局有序。
Order By:全局排序,只有一个Reducer;
Distrbute By:类似MR中Partition,进行分区,结合sort by使用。
Cluster By:当Distribute by和Sorts by字段相同时可以使用Cluster by方式。Cluster by除了具有Distribute by的功能外还兼具Sort by的功能。但是排序只能是升序排序,不能指定排序规则为ASC或者DESC。
如果 distribute 和 sort 的字段是同一个时,此时,cluster by = distribute by + sort by
Join
inner join 内连接,两张表都满足条件的数据
left join 左链接,以左表为主表,主表的数据都显示
left semi join 显示左表的数据部分(内连接)
参数的配置方式优先级别:依次增强
默认的配置(hive-default.xml),自定义的配置(hive-site.xml),shell命令行参数,session的命令行中进行设置
Shell命令行参数(常用) -e "sql" 可以跟上sql的字符串,-f file.sql 可以跟上sql脚本文件
-hiveconf (参数配置,传递参数到脚本文件中)
-hivevar (只能传递参数)
内置函数
查看系统自带的函数:show functions;
显示自带的函数的用法:
#不详细 desc function upper;
#详细 desc function extended upper;
条件判断函数:
CASE
语法 : CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] END
返回值 : T
说明:如果 a 等于 b ,那么返回 c ;如果 a 等于 d ,那么返回 e ;否则返回 f
举例:hive> Select case 100 when 50 then 'tom' when 100 then 'mary' else 'tim' end from dual;
mary
字符串连接函数:CONCAT
带分隔符字符串连接函数:concat_ws
举例:select concat_ws(',', 'abc', '123')
自定义函数
UDF(User-Defined-Function)普通函数 一进一出
继承UDF 重载evaluate方法 打成jar包(胖包)上传到服务器 将jar包添加到 hive 的 classpath hive>add jar /home/hadoop/udf.jar; 创建临时函数与开发好的java class关联 create temporary function tolowercase as 'cn.itcast.hive.UDF_Demo'; (不加temporary就是创建永久函数,需要使用drop手动删除) 在hql中使用自定义的函数tolowercase ip Select tolowercase(name),age from t_test;
UDAF(User-Defined Aggregation Function)聚合函数 多进一出
UDAF是输入多个数据行,产生一个数据行
用户自定义的UDAF必须是继承了UDAF,且内部包含多个实现了exec的静态类
UDTF(User-Defined Table-Generating Functions)表生成函数 一进多出
继承org.apache.hadoop.hive.ql.udf.generic.GenericUDTF, 实现initialize, process, close三个方法。 UDTF首先会调用initialize方法, 此方法返回UDTF的返回行的信息(返回个数,类型)。 初始化完成后,会调用process方法,真正的处理过程在process函数中, 在process中,每一次forward()调用产生一行; 如果产生多列可以将多个列的值放在一个数组中, 然后将该数组传入到forward()函数。 最后close()方法调用,对需要清理的方法进行清理 把程序打成jar包 添加jar包:add jar /run/jar/udf_test.jar; 创建临时函数: CREATE TEMPORARY FUNCTION explode_map AS 'cn.itcast.hive.udtf.ExplodeMap'; 销毁临时函数:hive> DROP TEMPORARY FUNCTION add_example; UDTF有两种使用方法, 一种直接放到select后面(不可以添加其他字段使用,不可以嵌套调用, 不可以和group by/cluster by/distribute by/sort by一起使用) 一种和lateral view一起使用
lateral view(侧视图)与 explode函数
explode可以对数值类型为array,或者为map结构的进行分割处理
对array处理:将array每个元素单独作为一行输出
对map处理:将map中的元素作为一行输出,key作为一列,value作为一列
一般情况下,直接使用即可,也可以根据需要结合lateral view 使用
lateral view为侧视图,意义是为了配合UDTF来使用,把某一行数据拆分成多行数据。不加lateral view的UDTF只能提取单个字段拆分,并不能塞回原来数据表中。
加上lateral view就可以将拆分的单个字段数据与原始表数据关联上。在使用lateral view的时候需要指定视图别名和生成的新列别名。
1 --select 字段1, 字段2, ... 2 --from tabelA lateral view UDTF(xxx) 视图别名(虚拟表名) as a,b,c 3 --例如 4 select name,subview.* from test_message 5 lateral view explode(location) subview as lc;
行列转换
1.多行转多列
col1 col2 col3
a c 1
a d 2
a e 3
b c 4
b d 5
b e 6
现在要将其转化为:
col1 c d e
a 1 2 3
b 4 5 6
此时需要使用到max(case … when … then … else 0 end),仅限于转化的字段为数值类型且为正值的情况
1 select col1, 2 max(case col2 when 'c' then col3 else 0 end) as c, 3 max(case col2 when 'd' then col3 else 0 end) as d, 4 max(case col2 when 'e' then col3 else 0 end) as e 5 from row2col 6 group by col1;
2.多行转单列(重要)
col1 col2 col3
a b 1
a b 2
a b 3
c d 4
c d 5
c d 6
将其转化为:
col1 col2 col3
a b 1,2,3
c d 4,5,6
此时需要两个内置的函数:
a)concat_ws(参数1,参数2),用于进行字符的拼接
参数1—指定分隔符
参数2—拼接的内容
b)collect_set(col3),它的主要作用是将某字段的值进行去重汇总,产生array类型字段,如果不想去重可用collect_list()
1 select collect_set(col3) from row2col_1; 2 --将col3的所有数据放到一个集合中(去重) 3 4 select collect_set(col3) from row2col_1 group by col1,col2; 5 --根据col1,col2进行分组,只有第一列和第二列都相同,认为是同一组 6 7 select col1,col2, collect_set(col3) from row2col_1 8 group by col1,col2; 9 --三列显示,行转列 10 11 select col1, col2, 12 concat_ws(',', collect_set(cast(col3 as string))) as col3 13 from row2col_1 14 group by col1, col2; 15 --cast(col3 as string)将第三列变成string类型 16 --因为concat_ws是对于字符串拼接
3.多列转多行
col1 c d e
a 1 2 3
b 4 5 6
现要将其转化为:
col1 col2 col3
a c 1
a d 2
a e 3
b c 4
b d 5
b e 6
这里需要使用union进行拼接。union 可以结合多个select语句 返回共同的结果集保证每个select语句返回的数据类型个数是一致的。
1 select col1, 'c' as col2, c as col3 from col2row 2 UNION 3 select col1, 'd' as col2, d as col3 from col2row 4 UNION 5 select col1, 'e' as col2, e as col3 from col2row 6 order by col1, col2;
4.单列转多行(重要)
col1 col2 col3
a b 1,2,3
c d 4,5,6
现要将其转化为:
col1 col2 col3
a c 1
a d 2
a e 3
b c 4
b d 5
b e 6
这里需要使用UDTF(表生成函数)explode(),该函数接受array类型的参数,其作用恰好与collect_set相反,实现将array类型数据行转列。explode配合lateral view实现将某列数据拆分成多行。
1 select col1, col2, lv.col3 as col3 2 from col2row_2 3 lateral view explode(split(col3, ',')) lv as col3;
reflect函数
可以支持在 sql 中调用 java 中的自带函数,秒杀一切 udf 函数
--例1 --使用 java.lang.Math 当中的 Max 求两列当中的最大值 select reflect("java.lang.Math","max",col1,col2) from test_udf; --例2 --准备数据 test_udf2.txt java.lang.Math,min,1,2 java.lang.Math,max,2,3 --执行查询 select reflect(class_name,method_name,col1,col2) from test_udf2;
json
什么叫json:原生的js对象
hive处理json数据总体来说有两个方向的路走:
1. 将json以字符串的方式整个导入hive表,然后通过使用UDF函数解析已经导入到hive中的数据,比如使用lateral view json_tuple的方法,获取所需要的列名
- get_json_object(string json_string,string path):第一个参数填写json对象变量,第二个参数使用$表示json变量表示,每次只能返回一个数据项
1 select get_json_object(t.json,'$.id'), 2 get_json_object(t.json,'$.total_number') 3 from tmp_json_test t;
- json_tuple(string json_string,'属性1','属性2')
1 select json_tuple(json,'id','ids','total_number') 2 from tmp_json_test;
2. 在导入之前将json拆成各个字段,导入Hive表的数据是已经解析过的,这将需要使用地方放的SerDe
1 --从http:www.congiu.net/hive-json-serde/下载jar包 2 add jar 3 /root/hivedata/json-serde-1.3.7-jar-with-dependencies.jar; 4 5 create table tmp_json_array(id string, 6 ids array<string>,total_number int) 7 row format SERDE 'org.openx.data.jsonserde.JsonSerDe' 8 stored as textfile; 9 load data local inpath '/root/hivedata/json_test.txt' 10 overwrite into table tmp_json_array;
窗口函数
又叫 OLAP 函数/分析函数,兼具分组和排序功能
窗口函数最重要的关键字是
partition by 和 order by。
具体语法如下:over (partition by xxx order by xxx)
- 如果不指定 rows between,默认为从起点到当前行;
- 如果不指定 order by,则将分组内所有值累加;
- 关键是理解 rows between 含义,也叫做 window 子句:
- preceding:往前
- following:往后
- current row:当前行
- unbounded:起点
- unbounded preceding 表示从前面的起点
- unbounded following:表示到后面的终点
AVG,MIN,MAX,和 SUM 用法一样。
例:
1 select cookieid,createtime,pv, 2 sum(pv) over(partition by cookieid order by createtime) as pv1 3 from itcast_t1; 4 --pv1: 分组内从起点到当前行的 pv 累积, 5 --如,11 号的 pv1=10 号的 pv+11 号的 pv, 12 号=10 号+11 号+12 6 7 select cookieid,createtime,pv, 8 sum(pv) over(partition by cookieid) as pv3 9 from itcast_t1; 10 --pv3: 分组内(cookie1)所有的 pv 累加 11 12 select cookieid,createtime,pv, 13 sum(pv) over(partition by cookieid 14 order by createtime 15 rows between 3 preceding and 1 following) as pv5 16 from itcast_t1; 17 --pv5: 分组内当前行+往前 3 行+往后 1 行, 18 --如,14 号=11 号+12 号+13 号+14 号+15 号=5+7+3+2+4=21 19 20 select cookieid,createtime,pv, 21 sum(pv) over(partition by cookieid 22 order by createtime rows between current row and 23 unbounded following) as pv6 24 from itcast_t1; 25 --pv6: 分组内当前行+往后所有行, 26 --如,13 号=13 号+14 号+15 号+16 号=3+2+4+4=13, 27 --14 号=14 号+15 号+16 号=2+4+4=10
- ROW_NUMBER() 从 1 开始,按照顺序,生成分组内记录的序列。 1 2 3 4
- RANK() 生成数据项在分组中的排名,排名相等会在名次中留下空位 。1 2 2 4
- DENSE_RANK()生成数据项在分组中的排名,排名相等在名次中不会留下空位。1 2 2 3
1 SELECT 2 cookieid, 3 createtime, 4 pv, 5 RANK() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rn1, 6 DENSE_RANK() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rn2, 7 ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY pv DESC) AS rn3 8 FROM itcast_t2 WHERE cookieid = 'cookie1';
NTILE
有时会有这样的需求:如果数据排序后分为三部分,业务人员只关心其中的一部分,如何将这中间的三分之一数据拿出来呢?NTILE 函数即可以满足。 可以看成是:把有序的数据集合平均分配到指定的数量(num)个桶中, 将桶号分配给每一行。如果不能平均分配,则优先分配较小编号的桶,并且各个
桶中能放的行数最多相差 1。 然后可以根据桶号,选取前或后 n 分之几的数据。数据会完整展示出来,只是给相应的数据打标签;具体要取几分之几的数据,需要再嵌套一层根据标签取出。
1 SELECT * FROM 2 (SELECT 3 cookieid, 4 createtime, 5 pv, 6 NTILE(2) OVER(PARTITION BY cookieid ORDER BY createtime) AS rn1, 7 NTILE(3) OVER(PARTITION BY cookieid ORDER BY createtime) AS rn2, 8 NTILE(4) OVER(ORDER BY createtime) AS rn3 9 FROM itcast_t2 ORDER BY cookieid,createtime) temp 10 WHERE cookieid = 'cookie2' AND rn2 = 2;
Lag(col, n)往前n行
Lead(col, n)往后n行
数据压缩
优缺点
优点: 减少存储磁盘空间,降低单节点的磁盘 IO。 由于压缩后的数据占用的带宽更少,因此可以快数据在 Hadoop 集群流动的速度,减少网络传输带宽。
缺点: 需要花费额外的时间/CPU 做压缩和解压缩计算
MR哪些过程可以设置压缩?
需要分析处理的数据在进入map 前可以压缩,然后解压处理,map 处理完成后的输出可以压缩,这样可以减少网络 I/O(reduce 通常和 map 不在同一节点上),reduce 拷贝压缩的数据后进行解压,处理完成后可以压缩存储在 hdfs 上,以减少磁盘占用量。
数据存储格式
- 行式存储
优点: 相关的数据是保存在一起,比较符合面向对象的思维,因为一行数据就是一条记录,这种存储格式比较方便进行 INSERT/UPDATE 操作
缺点: 如果查询只涉及某几个列,它会把整行数据都读取出来,不能跳过不必要的列读取。当然数据比较少,一般没啥问题,如果数据量比较大就比较影响性能 由于每一行中,列的数据类型不一致,导致不容易获得一个极高的压缩比,也就是空间利用率不高 不是所有的列都适合作为索引
- 列式存储
优点: 查询时,只有涉及到的列才会被查询,不会把所有列都查询出来,即可以跳过不必要的列查询; 高效的压缩率,不仅节省储存空间也节省计算内存和 CPU。任何列可以作为索引;
缺点: INSERT/UPDATE 很麻烦或者不方便; 不适合扫描小量的数据
Hive 支持的存储数的格式主要有:TEXTFILE(行式存储) 、SEQUENCEFILE(行式存储)、ORC(列式存储)、PARQUET(列式存储)。

TEXTFILE,行式存储,但使用这种方式,hive 不会对数据进行切分,从而无法对数据进行并行操作
ORC,列式存储,它并不是一个单纯的列式存储格式,仍然是首先根据行组分割整个表,在每一个行组内进行按列存储
优点: ORC 是列式存储,有多种文件压缩方式,并且有着很高的压缩比。 文件是可切分(Split)的。因此,在 Hive 中使用 ORC 作为表的文件存储格式,不仅节省 HDFS 存储资源,查询任务的输入数据量减少,使用的 MapTask 也就减少了。 ORC 可以支持复杂的数据结构(比如 Map 等)。ORC 文件也是以二进制方式存储的,所以是不可以直接读取,ORC 文件也是自解析的。
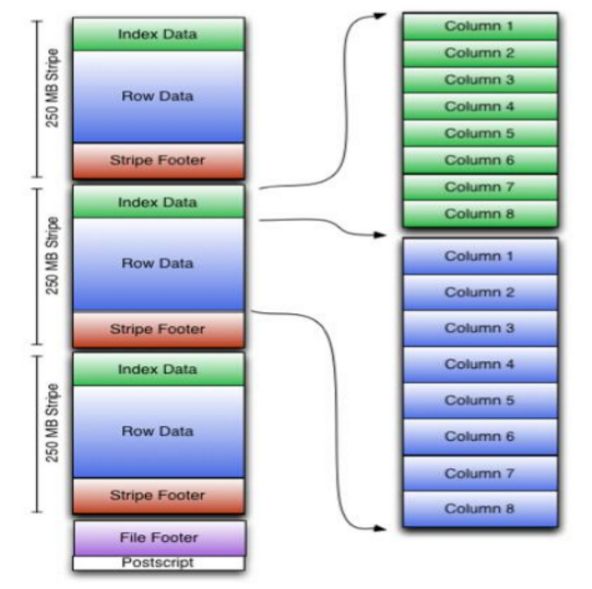
一个 ORC 文件可以分为若干个 Stripe,一个 Stripe可以分为三个部分:
- indexData:某些列的索引数据。一个轻量级的 index,默认是每隔 1W 行做一个索引。这里做的索引只是记录某行的各字段在 Row Data 中的 offset
- rowData :真正的数据存储。,先取部分行,然后对这些行按列进行存储。对每个列进行了编码,分成多个 Stream 来存储。
- StripFooter:存放各个stripe 的元数据信息。每个文件有一个 File Footer,这里面存的是每个 Stripe 的行数,每个 Column的数据类型信息等;每个文件的尾部是一个 PostScript,这里面记录了整个文件的压缩类型以及 FileFooter 的长度信息等。在读取文件时,会 seek 到文件尾部读PostScript,从里面解析到 File Footer 长度,再读 FileFooter,从里面解析到各个Stripe 信息,再读各个 Stripe,即从后往前读。
PARQUET,列式存储,是面向分析型业务的列式存储格式。Parquet 文件是以二进制方式存储的,所以是不可以直接读取的,文件中包括该文件的数据和元数据,因此 Parquet 格式文件是自解析的。 通常情况下,在存储Parquet数据的时候会按照Block大小设置行组的大小,由于一般情况下每一个 Mapper 任务处理数据的最小单位是一个 Block,这样可以把每一个行组由一个 Mapper 任务处理,增大任务执行并行度。
存储格式总结
ORC存储文件默认采用 ZLIB 压缩。比 snappy 压缩的小。 在实际的项目开发当中,hive 表的数据存储格式一般选择:orc 或 parquet。压缩方式一般选择 snappy。
存储文件的压缩比总结: ORC > Parquet > textFile
存储文件查询速度三种差不多
优化
0. 分区分桶技术,行列过滤
1. Fetch 抓取机制
在 hive-default.xml.template 文件中 hive.fetch.task.conversion 默认是 more,老版本 hive 默认是 minimal,该属性修改为 more 以后,在全局查找、字段查找、limit 查找等都不走 mapreduce。
2. mapreduce 本地模式
mapreduce可以使用本地模拟环境运行,此时就不是分布式执行的程序,但是针对小文件小数据处理特别有效果。用户可以通过设置 hive.exec.mode.local.auto 的值为 true,来让 Hive 在适当的时候自动启动这个优化。
3. join优化
1)map join 在 Reduce 阶段完成 join。容易发生数据倾斜。可以用 MapJoin 把小表全部加载到内存在 map 端进行 join,避免 reducer处理。 在实际使用中,只要根据业务把握住小表的阈值标准即可,hive 会自动帮我们完成 mapjoin,提高执行的效率。
2)大表 join 大表
空key过滤,key对应的数据为异常数据,例如空,可进行过滤
空key转换,key对应的数据有用,必须进行join,通过 hive 的 rand 函数,随记的给每一个为空的 id 赋上一个随机值,这样就不会造成数据倾斜。
3)大小表,小大表join 在当下的 hive 版本中,大表 join 小表或者小表 join 大表,就算是关闭 map端 join 的情况下,基本上没有区别了(hive 为了解决数据倾斜的问题,会自动进行过滤) 。
4. group by 优化—map 端聚合
很多聚合操作都可以先在 Map 端进行部分聚合,最后在 Reduce 端得出最终结果。
1)是否在 Map 端进行聚合,默认为 True set hive.map.aggr = true;
2)在 Map 端进行聚合操作的条目数目 set hive.groupby.mapaggr.checkinterval = 100000;
3)有数据倾斜的时候进行负载均衡(默认是 false) set hive.groupby.skewindata = true;
5. 数据倾斜问题
1)调整mapTask个数
在Map执行前合并小文件,减少Map数:CombineHiveInputFormat具有对小文件进行合并的功能(系统默认的格式)。HiveInputFormat没有对小文件合并功能。
当 input 的文件都很大,任务逻辑复杂,map 执行非常慢的时候,可以考虑增加 Map 数
2)调整reduceTask个数,reduce 个数并不是越多越好
1)过多的启动和初始化 reduce 也会消耗时间和资源;
2)另外,有多少reduce,就会有多少输出文件,如果生成很多个小文件,那么如果这些小文件作为下一个任务的输入,则也会出现小文件过多的问题; 在设置 reduce 个数的时候也需要考虑这两个原则:处理大数据量利用合适的 reduce 数;使单个 reduce 任务处理数据量大小要合适。
6. 了解执行计划—explain
7. 并行执行机制
通过设置参数 hive.exec.parallel 值为true,就可以开启并发执行。
8. 严格模式
通过设置属性 hive.mapred.mode 值为默认是非严格模式 nonstrict 。开启严格模式需要修改 hive.mapred.mode 值为 strict,开启严格模式可以禁止 3 种类型的查询。
1)对于分区表,除非 where 语句中含有分区字段过滤条件来限制范围,否
则不允许执行。用户不允许扫描所有分区。
2)对于使用了 order by 语句的查询,要求必须使用 limit 语句。因为 order
by 为了执行排序过程会将所有的结果数据分发到同一个 Reducer 中进行处理,
3)限制笛卡尔积的查询。
9. jvm 重用机制
JVM 重用可以使得 JVM 实例在同一个 job 中重新使用 N 次,这个功能的缺点是,开启 JVM 重用将一直占用使用到的 task 插槽,以便进行重用,直到任务完成后才能释放。
10. 推测执行机制
推测出“拖后腿”的任务,并为这样的任务启动一个备份任务,让该任务与原始任务同时处理同一份数据,并最终选用最先成功运行完成任务的计算结果作为最终结果。