转载;面试官:请谈谈写入消息中间件的数据,如何保证不丢失?
原创 石杉的架构笔记 2019-03-06 08:30:00
欢迎关注头条号:石杉的架构笔记
周一至周五早八点半!精品技术文章准时送上!!!
精品学习资料获取通道,参见文末
目录
1、背景引入
2、Kafka分布式存储架构
3、Kafka高可用架构
4、画图复现Kafka的写入数据丢失问题
5、Kafka的ISR机制是什么?
6、Kafka写入的数据如何保证不丢失?
7、总结
(1)背景引入
这篇文章,给大家聊一下写入Kafka的数据该如何保证其不丢失?
看过之前的文章面试官:消息中间件如何实现每秒几十万的高并发写入?的同学,应该都知道写入Kafka的数据是会落地写入磁盘的。
我们暂且不考虑写磁盘的具体过程,先大致看看下面的图,这代表了Kafka的核心架构原理。
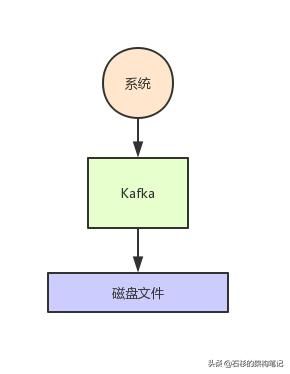
(2)Kafka分布式存储架构
那么现在问题来了,如果每天产生几十TB的数据,难道都写一台机器的磁盘上吗?这明显是不靠谱的啊!
所以说,这里就得考虑数据的分布式存储了,其实关于消息中间件的分布式存储以及高可用架构,之前的一篇文章面试一线互联网大厂?那这道题目你必须得会!也分析过了,但是这里,我们结合Kafka的具体情况来说说。
在Kafka里面,有一个核心的概念叫做“Topic”,这个topic你就姑且认为是一个数据集合吧。
举个例子,如果你现在有一份网站的用户行为数据要写入Kafka,你可以搞一个topic叫做“user_access_log_topic”,这里写入的都是用户行为数据。
然后如果你要把电商网站的订单数据的增删改变更记录写Kafka,那可以搞一个topic叫做“order_tb_topic”,这里写入的都是订单表的变更记录。
然后假如说咱们举个例子,就说这个用户行为topic吧,里面如果每天写入几十TB的数据,你觉得都放一台机器上靠谱吗?
明显不太靠谱,所以Kafka有一个概念叫做Partition,就是把一个topic数据集合拆分为多个数据分区,你可以认为是多个数据分片,每个Partition可以在不同的机器上,储存部分数据。
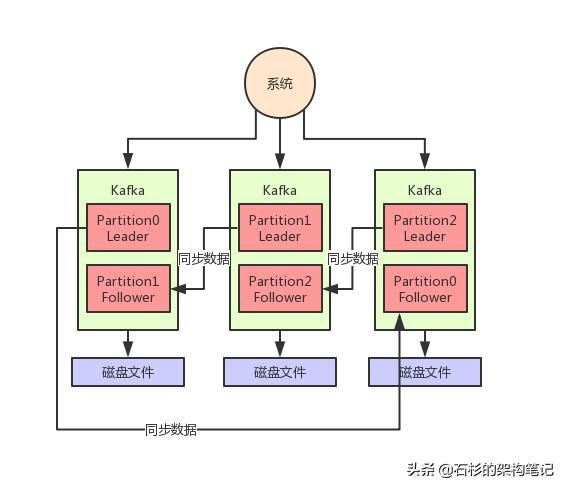
这样,不就可以把一个超大的数据集合分布式存储在多台机器上了吗?大家看下图,一起来体会一下。

(3)Kafka高可用架构
但是这个时候,我们又会遇到一个问题,就是万一某台机器宕机了,这台机器上的那个partition管理的数据不就丢失了吗?
所以说,我们还得做多副本冗余,每个Partition都可以搞一个副本放在别的机器上,这样某台机器宕机,只不过是Partition其中一个副本丢失。
如果某个Partition有多副本的话,Kafka会选举其中一个Parititon副本作为Leader,然后其他的Partition副本是Follower。
只有Leader Partition是对外提供读写操作的,Follower Partition就是从Leader Partition同步数据。
一旦Leader Partition宕机了,就会选举其他的Follower Partition作为新的Leader Partition对外提供读写服务,这不就实现了高可用架构了?
大家看下面的图,看看这个过程。
(4)Kafka写入数据丢失问题
现在我们来看看,什么情况下Kafka中写入数据会丢失呢?
其实也很简单,大家都知道写入数据都是往某个Partition的Leader写入的,然后那个Partition的Follower会从Leader同步数据。
但是万一1条数据刚写入Leader Partition,还没来得及同步给Follower,此时Leader Partiton所在机器突然就宕机了呢?
大家看下图:
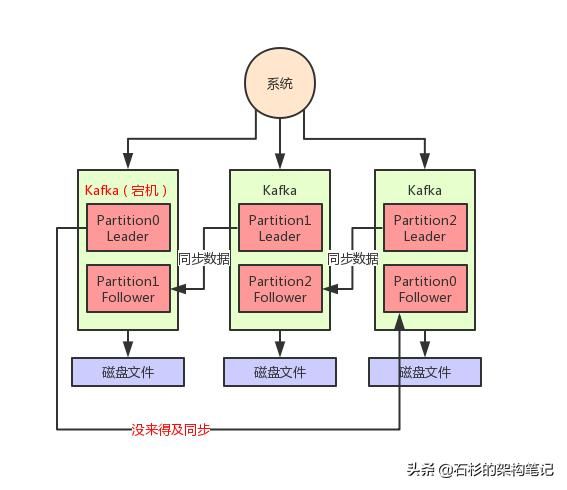
如上图,这个时候有一条数据是没同步到Partition0的Follower上去的,然后Partition0的Leader所在机器宕机了。
此时就会选举Partition0的Follower作为新的Leader对外提供服务,然后用户是不是就读不到刚才写入的那条数据了?
因为Partition0的Follower上是没有同步到最新的一条数据的。
这个时候就会造成数据丢失的问题。
(5)Kafka的ISR机制是什么?
现在我们先留着这个问题不说具体怎么解决,先回过头来看一个Kafka的核心机制,就是ISR机制。
这个机制简单来说,就是会自动给每个Partition维护一个ISR列表,这个列表里一定会有Leader,然后还会包含跟Leader保持同步的Follower。
也就是说,只要Leader的某个Follower一直跟他保持数据同步,那么就会存在于ISR列表里。
但是如果Follower因为自身发生一些问题,导致不能及时的从Leader同步数据过去,那么这个Follower就会被认为是“out-of-sync”,从ISR列表里踢出去。
所以大家先得明白这个ISR是什么,说白了,就是Kafka自动维护和监控哪些Follower及时的跟上了Leader的数据同步。
(6)Kafka写入的数据如何保证不丢失?
所以如果要让写入Kafka的数据不丢失,你需要要求几点:
每个Partition都至少得有1个Follower在ISR列表里,跟上了Leader的数据同步
每次写入数据的时候,都要求至少写入Partition Leader成功,同时还有至少一个ISR里的Follower也写入成功,才算这个写入是成功了
如果不满足上述两个条件,那就一直写入失败,让生产系统不停的尝试重试,直到满足上述两个条件,然后才能认为写入成功
按照上述思路去配置相应的参数,才能保证写入Kafka的数据不会丢失
好!现在咱们来分析一下上面几点要求。
第一条,必须要求至少一个Follower在ISR列表里。
那必须的啊,要是Leader没有Follower了,或者是Follower都没法及时同步Leader数据,那么这个事儿肯定就没法弄下去了。
第二条,每次写入数据的时候,要求leader写入成功以外,至少一个ISR里的Follower也写成功。
大家看下面的图,这个要求就是保证说,每次写数据,必须是leader和follower都写成功了,才能算是写成功,保证一条数据必须有两个以上的副本。
这个时候万一leader宕机,就可以切换到那个follower上去,那么Follower上是有刚写入的数据的,此时数据就不会丢失了。
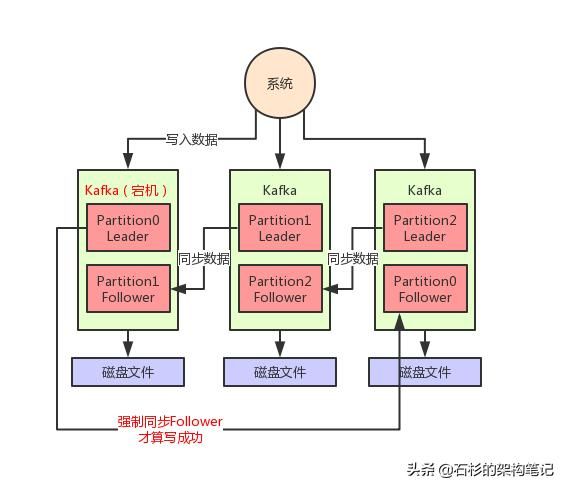
如上图所示,假如现在leader没有follower了,或者是刚写入leader,leader立马就宕机,还没来得及同步给follower。
在这种情况下,写入就会失败,然后你就让生产者不停的重试,直到kafka恢复正常满足上述条件,才能继续写入。
这样就可以让写入kafka的数据不丢失。
(7)总结
最后总结一下,其实kafka的数据丢失问题,涉及到方方面面。
譬如生产端的缓存问题,包括消费端的问题,同时kafka自己内部的底层算法和机制也可能导致数据丢失。
但是平时写入数据遇到比较大的一个问题,就是leader切换时可能导致数据丢失。所以本文仅仅是针对这个问题说了一下生产环境解决这个问题的方案。
End
(封面图源网络,侵权删除)
私信头条号,发送:“资料”,获取更多“秘制” 精品学习资料
如有收获,请帮忙转发,您的鼓励是作者最大的动力,谢谢!
一大波微服务、分布式、高并发、高可用的原创系列文章正在路上,
欢迎关注头条号:石杉的架构笔记
周一至周五早八点半!精品技术文章准时送上!!!
十余年BAT架构经验倾囊相授
推荐阅读
1、拜托!面试请不要再问我Spring Cloud底层原理!
2、微服务注册中心如何承载大型系统的千万级访问?
3、「性能优化之道」每秒上万并发下的Spring Cloud参数优化实战
4、「“剁手党”狂欢的背后」微服务架构如何保障99.99%的高可用?
5、兄弟,用大白话告诉你小白都能看懂的Hadoop架构原理
6、大规模集群下Hadoop NameNode如何承载每秒上千次的高并发访问
7、「性能优化的秘密」Hadoop如何将TB级大文件的上传性能优化上百倍
8、拜托,面试请不要再问我TCC分布式事务的实现原理!
9、最终一致性分布式事务如何保障实际生产中99.99%高可用?
10、拜托,面试请不要再问我Redis分布式锁的实现原理
11、Hadoop底层算法如何优雅的将大规模集群性能提升10倍以上?
12、亿级流量系统架构之如何支撑百亿级数据的存储与计算
13、亿级流量系统架构之如何设计高容错分布式计算系统
14、亿级流量系统架构之如何设计承载百亿流量的高性能架构
15、亿级流量系统架构之如何设计每秒十万查询的高并发架构
16、亿级流量系统架构之如何设计全链路99.99%高可用架构
17、七张图彻底讲清楚ZooKeeper分布式锁的实现原理
18、大白话聊聊Java并发面试问题之volatile到底是什么?
19、大白话聊聊Java并发面试问题之Java 8如何优化CAS性能?
20、大白话聊聊Java并发面试问题之谈谈你对AQS的理解?
21、大白话聊聊Java并发面试问题之微服务注册中心的读写锁优化
22、互联网公司的面试官是如何360°无死角考察候选人的?(上篇)
23、互联网公司面试官是如何360°无死角考察候选人的?(下篇)
24、「Java进阶面试系列之一」你们系统架构中为何要引入消息中间件?
25、「Java进阶面试系列之二」系统架构引入消息中间件有什么缺点
26、「行走的Offer收割机」一位朋友斩获BAT技术专家Offer的面试经历
27、「Java进阶面试系列之三」消息中间件在你们项目里是如何落地的?
28、扎心!线上服务宕机时,如何保证数据100%不丢失?
29、 一次JVM FullGC的背后,竟隐藏着惊心动魄的线上生产事故!
30、「高并发优化实践」10倍请求压力来袭,你的系统会被击垮吗?
31、消息中间件集群崩溃,如何保证百万生产数据不丢失?
32、亿级流量系统架构之如何在上万并发场景下设计可扩展架构(上)?
33、亿级流量系统架构之如何在上万并发场景下设计可扩展架构(中)?
34、亿级流量系统架构之如何在上万并发场景下设计可扩展架构(下)?
35、亿级流量架构第二弹:你的系统真的无懈可击吗?
36、亿级流量系统架构之如何保证百亿流量下的数据一致性(上)
37、亿级流量系统架构之如何保证百亿流量下的数据一致性(中)?
38、亿级流量系统架构之如何保证百亿流量下的数据一致性(下)?
39、互联网面试必杀:如何保证消息中间件全链路数据100%不丢失(1)
40、互联网面试必杀:如何保证消息中间件全链路数据100%不丢失(2)
41、面试大杀器:消息中间件如何实现消费吞吐量的百倍优化?
42、兄弟,用大白话给你讲小白都能看懂的分布式系统容错架构
43、从团队自研的百万并发中间件系统的内核设计看Java并发性能优化
44、如果20万用户同时访问一个热点缓存,如何优化你的缓存架构?
45、「非广告,纯干货」英语差的程序员如何才能无障碍阅读官方文档?
46、面试最让你手足无措的一个问题:你的系统如何支撑高并发?
47、Java进阶必备:优雅的告诉面试官消息中间件该如何实现高可用架构
48、「非广告,纯干货」中小公司的Java工程师应该如何逆袭冲进BAT?
49、拜托,面试请不要再问我分布式搜索引擎的架构原理!
50、互联网大厂Java面试题:使用无界队列的线程池会导致内存飙升吗?
51、「码农打怪升级之路」行走江湖,你需要解锁哪些技能包?
52、「来自一线的血泪总结」你的系统上线时是否踩过这些坑?
53、【offer收割机必备】我简历上的Java项目都好low,怎么办?
54、【offer去哪了】我一连面试了十个Java岗,统统石沉大海!
55、支撑日活百万用户的高并发系统,应该如何设计其数据库架构?
56、高阶Java开发必备:分布式系统的唯一id生成算法你了解吗?
57、尴尬了!Spring Cloud微服务注册中心Eureka 2.x停止维护了咋办?
58、【Java高阶必备】如何优化Spring Cloud微服务注册中心架构?
59、面试官:消息中间件如何实现每秒几十万的高并发写入?
60、【非广告,纯干货】三四十岁大龄程序员,该如何保持职场竞争力?