从xgboost, lightgbm 到catboost
CSDN
xgboost
目标函数
O b j t = ∑ j = 1 T ( G j w j + 1 2 ( H j + λ ) w j 2 ) Obj^t= \sum_{j=1}^T(G_jw_j + \frac12(H_j+\lambda)w_j^2) Objt=j=1∑T(Gjwj+21(Hj+λ)wj2)
对于每个叶子节点,由最值公式可知:
w j ∗ = − G j H j + λ w_j^* = -\frac{G_j}{H_j+\lambda} wj∗=−Hj+λGj
目标函数变为
O b j t = − 1 2 ∑ j = 1 T G j 2 H j + λ + γ T Obj^t = -\frac12\sum_{j=1}^T \frac{G_j^2}{H_j+ \lambda} + \gamma T Objt=−21j=1∑THj+λGj2+γT
这个值越小越好
最优切分点划分算法
在实际训练过程中,当建立第 棵树时,一个非常关键的问题是如何找到叶子节点的最优切分点,XGBoost支持两种分裂节点的方法——贪心算法和近似算法。
(1)贪心算法
从树的深度为0开始:
- 对每个叶节点枚举所有的可用特征;
- 针对每个特征,把属于该节点的训练样本根据该特征值进行升序排列,通过线性扫描的方式来决定该特征的最佳分裂点,并记录该特征的分裂收益;
- 选择收益最大的特征作为分裂特征,用该特征的最佳分裂点作为分裂位置,在该节点上分裂出左右两个新的叶节点,并为每个新节点关联对应的样本集;
- 回到第1步,递归执行直到满足特定条件为止;
那么如何计算每个特征的分裂收益呢?
假设在某一节点完成分裂,则分裂前的目标函数可写为:
O b j 1 = − 1 2 [ ( G L + G R ) 2 H L + H R + λ ] + γ Obj_1=-\frac12[\frac{(G_L+G_R)^2}{H_L+H_R+\lambda}] + \gamma Obj1=−21[HL+HR+λ(GL+GR)2]+γ
分裂后的目标函数:
O b j 2 = − 1 2 [ G L 2 H L + λ + G R 2 H R + λ ] + 2 γ Obj_2 = -\frac12[\frac{G_L^2}{H_L+\lambda} +\frac{G_R^2}{H_R+\lambda}] + 2\gamma Obj2=−21[HL+λGL2+HR+λGR2]+2γ
分裂后的收益
G a i n = O b j 1 − O b j 2 = 1 2 [ G L 2 H L + λ + G R 2 H R + λ − ( G L + G R ) 2 H L + H R + λ ] Gain = Obj_1-Obj_2 = \frac12[\frac{G_L^2}{H_L+\lambda} +\frac{G_R^2}{H_R+\lambda}-\frac{(G_L+G_R)^2}{H_L+H_R+\lambda}] Gain=Obj1−Obj2=21[HL+λGL2+HR+λGR2−HL+HR+λ(GL+GR)2]
注意: 该特征收益也可作为特征重要性输出的重要依据。
对于每次分裂,我们都需要枚举所有特征可能的分割方案,如何高效地枚举所有的分割呢?
假设我们要枚举某个特征所有x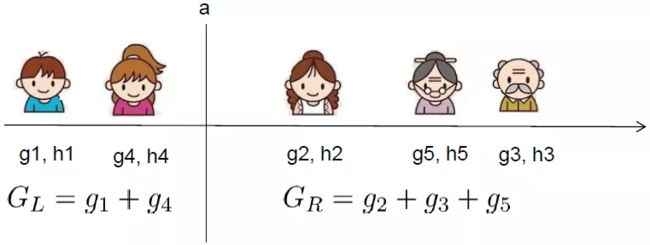
观察分裂后的收益,我们会发现节点划分不一定会使得结果变好,因为我们有一个引入新叶子的惩罚项,也就是说引入的分割带来的增益如果小于一个阀值的时候,我们可以剪掉这个分割。
(2)近似算法
贪心算法可以得到最优解,但当数据量太大时则无法读入内存进行计算,近似算法主要针对贪心算法这一缺点给出了近似最优解。
对于每个特征,只考察分位点可以减少计算复杂度。
该算法首先根据特征分布的分位数提出候选划分点,然后将连续型特征映射到由这些候选点划分的桶中,然后聚合统计信息找到所有区间的最佳分裂点。
在提出候选切分点时有两种策略:
- Global:学习每棵树前就提出候选切分点,并在每次分裂时都采用这种分割;
- Local:每次分裂前将重新提出候选切分点。直观上来看,Local策略需要更多的计算步骤,而Global策略因为节点已有划分所以需要更多的候选点。
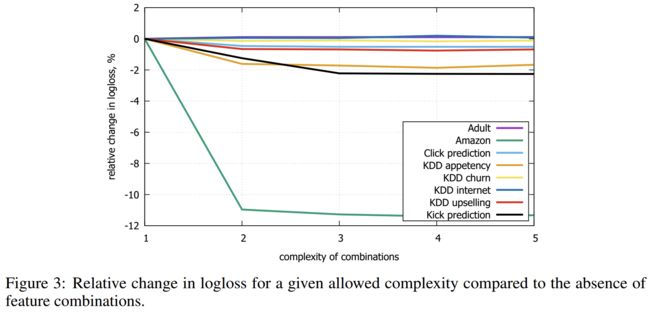
下图给出不同种分裂策略的AUC变化曲线,横坐标为迭代次数,纵坐标为测试集AUC,eps为近似算法的精度,其倒数为桶的数量。
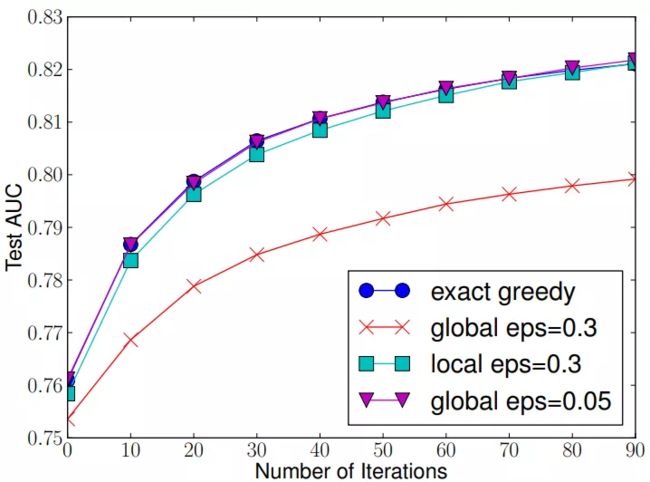
从上图我们可以看到, Global 策略在候选点数多时(eps 小)可以和 Local 策略在候选点少时(eps 大)具有相似的精度。此外我们还发现,在eps取值合理的情况下,分位数策略可以获得与贪心算法相同的精度。
近似算法简单来说,就是根据特征 k的分布来确定l个候选切分点 S k = { s k 1 , s k 2 , s k 3 , . . . , s k l } S_k = \{s_{k1},s_{k2},s_{k3},...,s_{kl}\} Sk={ sk1,sk2,sk3,...,skl},然后根据这些候选切分点把相应的样本放入对应的桶中,对每个桶的G, H进行累加。最后在候选切分点集合上贪心查找。该算法描述如下:

- 第一个for循环:对特征根据该特征分布的分位数找到切割点的候选集合 S k = { s k 1 , s k 2 , s k 3 , . . . , s k l } S_k = \{s_{k1},s_{k2},s_{k3},...,s_{kl}\} Sk={ sk1,sk2,sk3,...,skl}。这样做的目的是提取出部分的切分点不用遍历所有的切分点。其中获取某个特征的候选切割点的方式叫proposal(策略)。XGBoost 支持 Global 策略和 Local 策略。
- 第二个for循环:将每个特征的取值映射到由该特征对应的候选点集划分的分桶区间,即 s k , v ≥ x j k ≥ s k , v − 1 s_{k,v}\ge x_{jk} \ge s_{k, v-1} sk,v≥xjk≥sk,v−1 。对每个桶区间内的样本统计值G, H并进行累加,最后在这些累计的统计量上寻找最佳分裂点。这样做的目的是获取每个特征的候选分割点的G, H值。
 根据样本特征进行排序,然后基于分位数进行划分,并统计三个桶内的G, H 值,最终求解节点划分的增益。
根据样本特征进行排序,然后基于分位数进行划分,并统计三个桶内的G, H 值,最终求解节点划分的增益。
加权分位数缩略图
实际上,XGBoost不是简单地按照样本个数进行分位,而是以二阶导数值 作为样本的权重进行划分。为了处理带权重的候选切分点的选取,作者提出了Weighted Quantile Sketch算法。加权分位数略图算法提出了一种数据结构,这种数据结构支持merge和prune操作。作者在论文中给出了该算法的详细描述和证明链接,现在链接已经失效,但是在arXiv的最新版XGBoost论文中APPENDIX部分有该算法详细的描述,地址:https://arxiv.org/abs/1603.02754 。现在我们简单介绍加权分位数略图侯选点的选取方式,如下

稀疏感知算法
实际工程中一般会出现输入值稀疏的情况。比如数据的缺失、one-hot编码都会造成输入数据稀疏。XGBoost在构建树的节点过程中只考虑非缺失值的数据遍历,而为每个节点增加了一个缺省方向,当样本相应的特征值缺失时,可以被归类到缺省方向上,最优的缺省方向可以从数据中学到。至于如何学到缺省值的分支,其实很简单,分别枚举特征缺省的样本归为左右分支后的增益,选择增益最大的枚举项即为最优缺省方向。
在构建树的过程中需要枚举特征缺失的样本,乍一看这个算法会多出相当于一倍的计算量,但其实不是的。因为在算法的迭代中只考虑了非缺失值数据的遍历,缺失值数据直接被分配到左右节点,所需要遍历的样本量大大减小。作者通过在Allstate-10K数据集上进行了实验,从结果可以看到稀疏算法比普通算法在处理数据上快了超过50倍。

- pre-sorted& Histogram-based algorithm
- pre-sorted algorithm
- 对于每个节点,遍历所有的特征
- 对于每一个特征,以特征值大小进行排序
- 使用一个线性扫描方式,基于信息增益,选取最佳分隔点
- 在所有的特征中,决定最佳分隔特征及分隔点。
- 对于每个节点,遍历所有的特征
- Histogram-base algorithm
- 对每个特征,将其进行分桶(bins),利用bins去找最佳分隔点,而不是遍历所有可能可能的分隔点。
- pre-sorted algorithm
工程优化
列块并行学习
在树生成过程中,最耗时的一个步骤就是在每次寻找最佳分裂点时都需要对特征的值进行排序。而 XGBoost 在训练之前会根据特征对数据进行排序,然后保存到块结构中,并在每个块结构中都采用了稀疏矩阵存储格式(Compressed Sparse Columns Format,CSC)进行存储,后面的训练过程中会重复地使用块结构,可以大大减小计算量。
作者提出通过按特征进行分块并排序,在块里面保存排序后的特征值及对应样本的引用,以便于获取样本的一阶、二阶导数值。具体方式如图:

通过顺序访问排序后的块遍历样本特征的特征值,方便进行切分点的查找。此外分块存储后多个特征之间互不干涉,可以使用多线程同时对不同的特征进行切分点查找,即特征的并行化处理。在对节点进行分裂时需要选择增益最大的特征作为分裂,这时各个特征的增益计算可以同时进行,这也是 XGBoost 能够实现分布式或者多线程计算的原因。
缓存访问
列块并行学习的设计可以减少节点分裂时的计算量,在顺序访问特征值时,访问的是一块连续的内存空间,但通过特征值持有的索引(样本索引)访问样本获取一阶、二阶导数时,这个访问操作访问的内存空间并不连续,这样可能造成cpu缓存命中率低,影响算法效率。
为了解决缓存命中率低的问题,XGBoost 提出了缓存访问算法:为每个线程分配一个连续的缓存区,将需要的梯度信息存放在缓冲区中,这样就实现了非连续空间到连续空间的转换,提高了算法效率。此外适当调整块大小,也可以有助于缓存优化。
即将原来的梯度信息从内存放到缓存区中。
“核外”块计算
当数据量非常大时,我们不能把所有的数据都加载到内存中。那么就必须将一部分需要加载进内存的数据先存放在硬盘中,当需要时再加载进内存。这样操作具有很明显的瓶颈,即硬盘的IO操作速度远远低于内存的处理速度,肯定会存在大量等待硬盘IO操作的情况。针对这个问题作者提出了“核外”计算的优化方法。**具体操作为,将数据集分成多个块存放在硬盘中,使用一个独立的线程专门从硬盘读取数据,加载到内存中,这样算法在内存中处理数据就可以和从硬盘读取数据同时进行。**此外,XGBoost 还用了两种方法来降低硬盘读写的开销:
- 块压缩(Block Compression)。论文使用的是按列进行压缩,读取的时候用另外的线程解压。对于行索引,只保存第一个索引值,然后用16位的整数保存与该block第一个索引的差值。作者通过测试在block设置为 个样本大小时,压缩比率几乎达到 。
- 块分区(Block Sharding )。块分区是将特征block分区存放在不同的硬盘上,以此来增加硬盘IO的吞吐量。
总结
优点
- 精度更高: GBDT 只用到一阶泰勒展开,而 XGBoost 对损失函数进行了二阶泰勒展开。XGBoost 引入二阶导一方面是为了增加精度,另一方面也是为了能够自定义损失函数,二阶泰勒展开可以近似大量损失函数;
- 灵活性更强: GBDT 以 CART 作为基分类器,XGBoost 不仅支持 CART 还支持线性分类器,使用线性分类器的 XGBoost 相当于带 和 正则化项的逻辑斯蒂回归(分类问题)或者线性回归(回归问题)。此外,XGBoost 工具支持自定义损失函数,只需函数支持一阶和二阶求导;
- 正则化: XGBoost 在目标函数中加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、叶子节点权重的 范式。正则项降低了模型的方差,使学习出来的模型更加简单,有助于防止过拟合,这也是XGBoost优于传统GBDT的一个特性。
- Shrinkage(缩减): 相当于学习速率。XGBoost 在进行完一次迭代后,会将叶子节点的权重乘上该系数,主要是为了削弱每棵树的影响,让后面有更大的学习空间。传统GBDT的实现也有学习速率;
- 列抽样: XGBoost 借鉴了随机森林的做法,支持列抽样,不仅能降低过拟合,还能减少计算。这也是XGBoost异于传统GBDT的一个特性;
- 缺失值处理: 对于特征的值有缺失的样本,XGBoost 采用的稀疏感知算法可以自动学习出它的分裂方向;
- XGBoost工具支持并行: boosting不是一种串行的结构吗?怎么并行的?注意XGBoost的并行不是tree粒度的并行,XGBoost也是一次迭代完才能进行下一次迭代的(第次迭代的代价函数里包含了前面次迭代的预测值)。XGBoost的并行是在特征粒度上的。我们知道,决策树的学习最耗时的一个步骤就是对特征的值进行排序(因为要确定最佳分割点),XGBoost在训练之前,预先对数据进行了排序,然后保存为block结构,后面的迭代中重复地使用这个结构,大大减小计算量。这个block结构也使得并行成为了可能,在进行节点的分裂时,需要计算每个特征的增益,最终选增益最大的那个特征去做分裂,那么各个特征的增益计算就可以开多线程进行。
- 可并行的近似算法: 树节点在进行分裂时,我们需要计算每个特征的每个分割点对应的增益,即用贪心法枚举所有可能的分割点。当数据无法一次载入内存或者在分布式情况下,贪心算法效率就会变得很低,所以XGBoost还提出了一种可并行的近似算法,用于高效地生成候选的分割点。
缺点
- 虽然利用预排序和近似算法可以降低寻找最佳分裂点的计算量,但在节点分裂过程中仍需要遍历数据集;
- 预排序过程的空间复杂度过高,不仅需要存储特征值,还需要存储特征对应样本的梯度统计值的索引,相当于消耗了两倍的内存。
它是基于预排序方法的决策树算法。这种构建决策树的算法基本思想是:首先,对所有特征都按照特征的数值进行预排序。其次,在遍历分割点的时候用的代价找到一个特征上的最好分割点。最后,在找到一个特征的最好分割点后,将数据分裂成左右子节点。
- 首先,空间消耗大。这样的算法需要保存数据的特征值,还保存了特征排序的结果(例如,为了后续快速的计算分割点,保存了排序后的索引),这就需要消耗训练数据两倍的内存。
- 其次,时间上也有较大的开销,在遍历每一个分割点的时候,都需要进行分裂增益的计算,消耗的代价大。
- 最后,对cache优化不友好。在预排序后,特征对梯度的访问是一种随机访问,并且不同的特征访问的顺序不一样,无法对cache进行优化。同时,在每一层长树的时候,需要随机访问一个行索引到叶子索引的数组,并且不同特征访问的顺序也不一样,也会造成较大的cache miss。
XGBoost与GBDT的联系和区别有哪些?
(1)GBDT是机器学习算法,XGBoost是该算法的工程实现。
(2)正则项: 在使用CART作为基分类器时,XGBoost显式地加入了正则项来控制模型的复杂度,有利于防止过拟合,从而提高模型的泛化能力。
(3)导数信息: GBDT在模型训练时只使用了代价函数的一阶导数信息,XGBoost对代价函数进行二阶泰勒展开,可以同时使用一阶和二阶导数。简单来说,相对于GBDT的一阶泰勒展开,XGBoost采用二阶泰勒展开,可以更为精准的逼近真实的损失函数。
(4)基分类器: 传统的GBDT采用CART作为基分类器,XGBoost支持多种类型的基分类器,比如线性分类器。
(5)子采样: 传统的GBDT在每轮迭代时使用全部的数据,XGBoost则采用了与随机森林相似的策略,支持对数据进行采样。
(6)缺失值处理: 传统GBDT没有设计对缺失值进行处理,XGBoost能够自动学习出缺失值的处理策略。
(7)并行化: 传统GBDT没有进行并行化设计,注意不是tree维度的并行,而是特征维度的并行。XGBoost预先将每个特征按特征值排好序,存储为块结构,分裂结点时可以采用多线程并行查找每个特征的最佳分割点,极大提升训练速度。
lightgbm
为了避免上述XGBoost的缺陷,并且能够在不损害准确率的条件下加快GBDT模型的训练速度,lightGBM在传统的GBDT算法上进行了很多优化:
-
基于Histogram的决策树算法,来寻找特征分割点
-
单边梯度采样 Gradient-based One-Side Sampling(GOSS):使用GOSS可以减少大量只具有小梯度的数据实例,这样在计算信息增益的时候只利用剩下的具有高梯度的数据就可以了,相比XGBoost遍历所有特征值节省了不少时间和空间上的开销。
-
互斥特征捆绑 Exclusive Feature Bundling(EFB):使用EFB可以将许多互斥的特征绑定为一个特征,这样达到了降维的目的,这在维度较高时有效减少特征的数量。
-
带深度限制的Leaf-wise的叶子生长策略:大多数GBDT工具使用低效的按层生长 (level-wise) 的决策树生长策略,因为它不加区分的对待同一层的叶子,带来了很多没必要的开销。实际上很多叶子的分裂增益较低,没必要进行搜索和分裂。LightGBM使用了带有深度限制的按叶子生长 (leaf-wise) 算法。
-
直接支持类别特征(Categorical Feature)
-
支持高效并行
-
Cache命中率优化

基于Histogram的决策树算法
(1)直方图算法
Histogram algorithm应该翻译为直方图算法,直方图算法的基本思想是:先把连续的浮点特征值离散化成k个整数,同时构造一个宽度为k的直方图。在遍历数据的时候,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点。
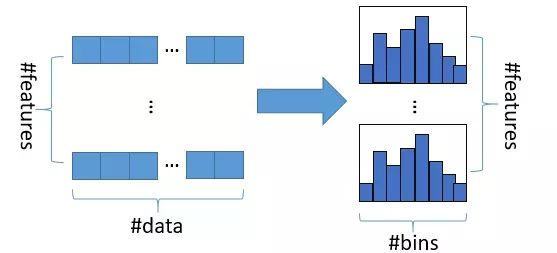
直方图算法简单理解为:首先确定对于每一个特征需要多少个箱子(bin)并为每一个箱子分配一个整数;然后将浮点数的范围均分成若干区间,区间个数与箱子个数相等,将属于该箱子的样本数据更新为箱子的值;最后用直方图(#bins)表示。看起来很高大上,其实就是直方图统计,将大规模的数据放在了直方图中。
我们知道特征离散化具有很多优点,如存储方便、运算更快、鲁棒性强、模型更加稳定等。对于直方图算法来说最直接的有以下两个优点:
- 内存占用更小: 直方图算法不仅不需要额外存储预排序的结果,而且可以只保存特征离散化后的值,而这个值一般用8位整型存储就足够了,内存消耗可以降低为原来的 1 8 \frac18 81。也就是说XGBoost需要用32位的浮点数去存储特征值,并用32位的整形去存储索引,而 LightGBM只需要用8位去存储直方图,内存相当于减少为 1 8 \frac18 81。
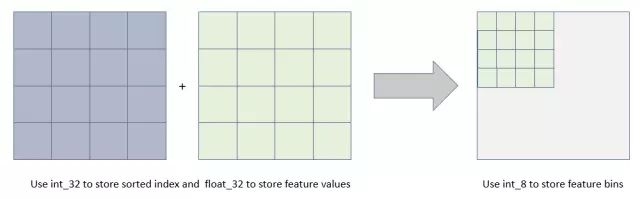
- 计算代价更小: 预排序算法XGBoost每遍历一个特征值就需要计算一次分裂的增益,而直方图算法LightGBM只需要计算k次(k可以认为是常数),直接将时间复杂度从O(#data*#feature)降低到O(k*#feature),而我们知道#data>>k。
当然,Histogram算法并不是完美的。由于特征被离散化后,找到的并不是很精确的分割点,所以会对结果产生影响。但在不同的数据集上的结果表明,离散化的分割点对最终的精度影响并不是很大,甚至有时候会更好一点。原因是决策树本来就是弱模型,分割点是不是精确并不是太重要;较粗的分割点也有正则化的效果,可以有效地防止过拟合;即使单棵树的训练误差比精确分割的算法稍大,但在梯度提升(Gradient Boosting)的框架下没有太大的影响。
(2) 直方图做差加速
LightGBM另一个优化是Histogram(直方图)做差加速。一个叶子的直方图可以由它的父亲节点的直方图与它兄弟的直方图做差得到,在速度上可以提升一倍。通常构造直方图时,需要遍历该叶子上的所有数据,但直方图做差仅需遍历直方图的k个桶。在实际构建树的过程中,LightGBM还可以先计算直方图小的叶子节点,然后利用直方图做差来获得直方图大的叶子节点,这样就可以用非常微小的代价得到它兄弟叶子的直方图。

注意: XGBoost 在进行预排序时只考虑非零值进行加速,而 LightGBM 也采用类似策略:只用非零特征构建直方图。
带深度限制的 Leaf-wise 算法
在Histogram算法之上,LightGBM进行进一步的优化。首先它抛弃了大多数GBDT工具使用的按层生长 (level-wise) 的决策树生长策略,而使用了带有深度限制的按叶子生长 (leaf-wise) 算法。
因此同Level-wise相比,
- Leaf-wise的优点是:在分裂次数相同的情况下,Leaf-wise可以降低更多的误差,得到更好的精度;
- Leaf-wise的缺点是:可能会长出比较深的决策树,产生过拟合。因此LightGBM会在Leaf-wise之上增加了一个最大深度的限制,在保证高效率的同时防止过拟合。
单边梯度采样算法
Gradient-based One-Side Sampling 应该被翻译为单边梯度采样(GOSS)。GOSS算法从减少样本的角度出发,排除大部分小梯度的样本,仅用剩下的样本计算信息增益,它是一种在减少数据量和保证精度上平衡的算法。
GOSS是一个样本的采样算法,目的是丢弃一些对计算信息增益没有帮助的样本留下有帮助的。根据计算信息增益的定义,梯度大的样本对信息增益有更大的影响。因此,GOSS在进行数据采样的时候只保留了梯度较大的数据,但是如果直接将所有梯度较小的数据都丢弃掉势必会影响数据的总体分布。
GOSS首先将要进行分裂的特征的所有取值按照绝对值大小降序排序(XGBoost一样也进行了排序,但是LightGBM不用保存排序后的结果),选取绝对值最大的a100%个数据。然后在剩下的较小梯度数据中随机选择 个数据。接着将这b100%个数据乘以一个常数 1 − a b \frac{1-a}{b} b1−a,这样算法就会更关注训练不足的样本,而不会过多改变原数据集的分布。最后使用这(a+b)*100%个数据来计算信息增益。下图是GOSS的具体算法:

互斥特征捆绑算法
高维度的数据往往是稀疏的,这种稀疏性启发我们设计一种无损的方法来减少特征的维度。通常被捆绑的特征都是互斥的(即特征不会同时为非零值,像one-hot),这样两个特征捆绑起来才不会丢失信息。如果两个特征并不是完全互斥(部分情况下两个特征都是非零值),可以用一个指标对特征不互斥程度进行衡量,称之为冲突比率,当这个值较小时,我们可以选择把不完全互斥的两个特征捆绑,而不影响最后的精度。互斥特征捆绑算法(Exclusive Feature Bundling, EFB)指出如果将一些特征进行融合绑定,则可以降低特征数量。这样在构建直方图时的时间复杂度从O(#data*#feature)变为O(#data*#bundle) ,这里#bundle指特征融合绑定后特征包的个数,且#bundle远小于#feature 。
针对这种想法,我们会遇到两个问题:
- 怎么判定哪些特征应该绑在一起(build bundled)?
- 怎么把特征绑为一个(merge feature)?
(1)解决哪些特征应该绑在一起
将相互独立的特征进行绑定是一个 NP-Hard 问题,LightGBM的EFB算法将这个问题转化为图着色的问题来求解,将所有的特征视为图的各个顶点,将不是相互独立的特征用一条边连接起来,边的权重就是两个相连接的特征的总冲突值,这样需要绑定的特征就是在图着色问题中要涂上同一种颜色的那些点(特征)。此外,我们注意到通常有很多特征,尽管不是
%
相互排斥,但也很少同时取非零值。如果我们的算法可以允许一小部分的冲突,我们可以得到更少的特征包,进一步提高计算效率。经过简单的计算,随机污染小部分特征值将影响精度最多 O ( [ ( 1 − γ ) n ] − 2 / 3 ) O([(1-\gamma) n]^{-2/3}) O([(1−γ)n]−2/3)
, γ \gamma γ是每个绑定中的最大冲突比率,当其相对较小时,能够完成精度和效率之间的平衡。具体步骤可以总结如下:
- 构造一个加权无向图,顶点是特征,边有权重,其权重与两个特征间冲突相关;
- 根据节点的度进行降序排序,度越大,与其它特征的冲突越大;
- 遍历每个特征,将它分配给现有特征包,或者新建一个特征包,使得总体冲突最小。
算法允许两两特征并不完全互斥来增加特征捆绑的数量,通过设置最大冲突比率 来平衡算法的精度和效率。EFB 算法的伪代码如下所示:

算法3的时间复杂度是 O ( # f e a t u r e 2 ) O(\#feature^2) O(#feature2),训练之前只处理一次,其时间复杂度在特征不是特别多的情况下是可以接受的,但难以应对百万维度的特征。为了继续提高效率,LightGBM提出了一种更加高效的无图的排序策略:将特征按照非零值个数排序,这和使用图节点的度排序相似,因为更多的非零值通常会导致冲突,新算法在算法3基础上改变了排序策略。
(2)解决怎么把特征绑为一捆
特征合并算法,其关键在于原始特征能从合并的特征中分离出来。绑定几个特征在同一个bundle里需要保证绑定前的原始特征的值可以在bundle中识别,考虑到histogram-based算法将连续的值保存为离散的bins,我们可以使得不同特征的值分到bundle中的不同bin(箱子)中,这可以通过在特征值中加一个偏置常量来解决。比如,我们在bundle中绑定了两个特征A和B,A特征的原始取值为区间[0, 10)],B特征的原始取值为区间[0, 20),我们可以在B特征的取值上加一个偏置常量10,将其取值范围变为[10,30),绑定后的特征取值范围为[0,30)],这样就可以放心的融合特征A和B了。具体的特征合并算法如下所示:

工程优化
直接支持类别特征
实际上大多数机器学习工具都无法直接支持类别特征,一般需要把类别特征,通过 one-hot 编码,转化到多维的特征,降低了空间和时间的效率。
LightGBM优化了对类别特征的支持,可以直接输入类别特征,不需要额外的展开。LightGBM采用 many-vs-many 的切分方式将类别特征分为两个子集,实现类别特征的最优切分。假设某维特征有k个类别,则有 2 k − 1 − 1 2^{k-1}-1 2k−1−1种可能,时间复杂度为O(2^k) ,LightGBM 基于 Fisher的《On Grouping For Maximum Homogeneity》论文实现了O(klogk)的时间复杂度。
算法流程如下图所示:
- 在枚举分割点之前,先把直方图按照每个类别对应的label均值进行排序;
- 然后按照排序的结果依次枚举最优分割点。
从下图可以看到, s u m ( y ) c o u n t ( y ) \frac{sum(y)}{count(y)} count(y)sum(y)为类别的均值。当然,这个方法很容易过拟合,所以LightGBM里面还增加了很多对于这个方法的约束和正则化。
 在Expo数据集上的实验结果表明,相比展开的方法,使用LightGBM支持的类别特征可以使训练速度加速倍,并且精度一致。更重要的是,LightGBM是第一个直接支持类别特征的GBDT工具。
在Expo数据集上的实验结果表明,相比展开的方法,使用LightGBM支持的类别特征可以使训练速度加速倍,并且精度一致。更重要的是,LightGBM是第一个直接支持类别特征的GBDT工具。
支持高效并行
(1) 特征并行
特征并行的主要思想是不同机器在不同的特征集合上分别寻找最优的分割点,然后在机器间同步最优的分割点。XGBoost使用的就是这种特征并行方法。
这种特征并行方法有个很大的缺点:就是对数据进行垂直划分,每台机器所含数据不同,然后使用不同机器找到不同特征的最优分裂点,划分结果需要通过通信告知每台机器,增加了额外的复杂度。
LightGBM 则不进行数据垂直划分,而是在每台机器上保存全部训练数据,在得到最佳划分方案后可在本地执行划分而减少了不必要的通信。比如,不需要传其他节点划分的样本的索引,只需要把最优特征以及分裂点告诉其他节点即可,具体过程如下图所示。
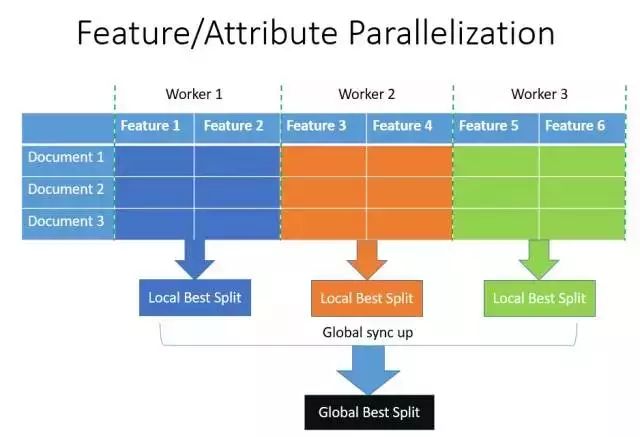
然而,当数据量很大时,特征并行算法还是受限于特征分裂效率。因此,当数据量大时,推荐使用数据并行算法。
(2) 数据并行
传统的数据并行策略主要为水平划分数据,让不同的机器先在本地构造直方图,然后进行全局的合并,最后在合并的直方图上面寻找最优分割点。该方法不能有效地加速特征选择的效率,当数据量#data很大时,该并行方法不能加快效率。并且,最优的分裂结果需要在worker之间进行传输,需要消耗很多的传输资源以及传输时间。
这种数据划分有一个很大的缺点:通讯开销过大。如果使用点对点通信,一台机器的通讯开销大约为 O(#machine*#features*#bins)
;如果使用集成的通信,则通讯开销为O(2*#features*#bins)。
LightGBM在数据并行中使用
- 分散规约 (Reduce scatter) 把直方图合并的任务分摊到不同的机器,降低通信和计算
- 利用直方图做差,进一步减少了一半的通信量。
具体过程如下图所示。

(3) 投票并行
基于投票的数据并行则进一步优化数据并行中的通信代价,使通信代价变成常数级别。在数据量很大的时候,使用投票并行的方式只合并部分特征的直方图从而达到降低通信量的目的,可以得到非常好的加速效果。具体过程如下图所示。
大致步骤为两步:
- 本地找出 Top K 特征,并基于投票筛选出可能是最优分割点的特征;
- 合并时只合并每个机器选出来的特征。
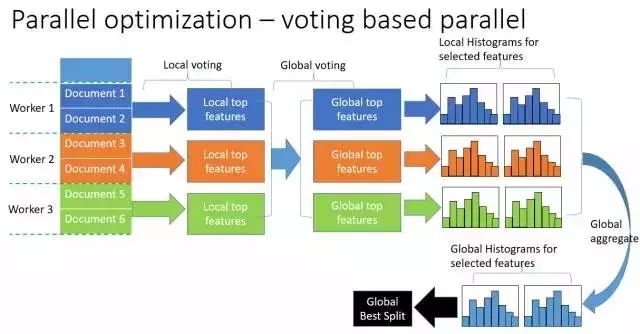
有理论证明,这种voting parallel以很大的概率选出实际最优的特征,因此不用担心top k的问题。
Cache命中率优化
XGBoost对cache优化不友好,如下图所示。在预排序后,特征对梯度的访问是一种随机访问,并且不同的特征访问的顺序不一样,无法对cache进行优化。同时,在每一层长树的时候,需要随机访问一个行索引到叶子索引的数组,并且不同特征访问的顺序也不一样,也会造成较大的cache miss。为了解决缓存命中率低的问题,XGBoost 提出了缓存访问算法进行改进。
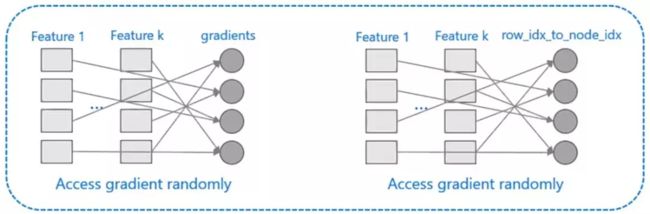
而 LightGBM 所使用直方图算法对 Cache 天生友好:
- 首先,所有的特征都采用相同的方式获得梯度(区别于XGBoost的不同特征通过不同的索引获得梯度),只需要对梯度进行排序并可实现连续访问,大大提高了缓存命中率;
- 其次,因为不需要存储行索引到叶子索引的数组,降低了存储消耗,而且也不存在 Cache Miss的问题。
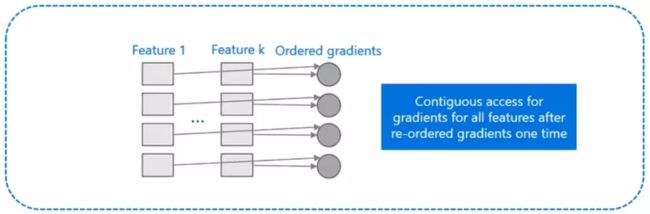
lightgbm首先计算所以样本的一阶,二阶梯度后,将其排序,然后利用GOSS采样得到所需的所有样本后,直接利用得到样本的所有特征构建直方图。
总结
这部分主要总结下 LightGBM 相对于 XGBoost 的优点,从内存和速度两方面进行介绍。
(1)速度更快
- LightGBM 采用了直方图算法将遍历样本转变为遍历直方图,极大的降低了时间复杂度;
- LightGBM 在训练过程中采用单边梯度算法过滤掉梯度小的样本,减少了大量的计算;
- LightGBM 采用了基于 Leaf-wise 算法的增长策略构建树,减少了很多不必要的计算量;
- LightGBM 采用优化后的特征并行、数据并行方法加速计算,当数据量非常大的时候还可以采用投票并行的策略;
- LightGBM 对缓存也进行了优化,增加了缓存命中率;
(2)内存更小
- XGBoost使用预排序后需要记录特征值及其对应样本的统计值的索引,而 LightGBM 使用了直方图算法将特征值转变为 bin 值,且不需要记录特征到样本的索引,将空间复杂度从O(2*#data)降低为O(#data),极大的减少了内存消耗;
- LightGBM 采用了直方图算法将存储特征值转变为存储 bin 值,降低了内存消耗;
- LightGBM 在训练过程中采用互斥特征捆绑算法减少了特征数量,降低了内存消耗。
缺点
- 可能会长出比较深的决策树,产生过拟合。因此LightGBM在Leaf-wise之上增加了一个最大深度限制,在保证高效率的同时防止过拟合;
- Boosting族是迭代算法,每一次迭代都根据上一次迭代的预测结果对样本进行权重调整,所以随着迭代不断进行,误差会越来越小,模型的偏差(bias)会不断降低。由于LightGBM是基于偏差的算法,所以会对噪点较为敏感;
- 在寻找最优解时,依据的是最优切分变量,没有将最优解是全部特征的综合这一理念考虑进去;
优点
- 更快的训练速度和高效率: 由于使用histogram基的算法,能够将连续值进行分桶(bins),这将加速训练过程。
- 更低的内存: 将值进行分桶后将降低内存的使用
- 更好的准确率 比其他boosting 算法: 由于采用leaf-wise 分裂的策略,能够产生更加复杂的树,这是比其他利用level-wise生成树主要的方式算法效果好的主要因素。 但该方法会导致过拟合,我们可以利用设置max_depth参数来避免过拟合。
- 处理大数据:由于其更低的内存即训练速度,能够处理更大的数据。
原因
在adboost中,样本的权重在训练中扮演一个重要的角色。但在一般的GBDT中,没有对样本权重的考虑。Lightgbm 基于改进xgboost 的训练速度,提出了考虑样本权重的gradient-based sampling(GOSS)。
-
GOSS (Gradient Based on side sampling)
我们知道,具有小梯度的样本已经被训练的很好,大梯度的样本还有待进一步训练。GOSS训练策略是,保留大梯度的样本,并对小梯度的样本进行采样的方式来进行训练,这能同样保存同样的数据分布。GOSS在减少训练数据量和保存学习率上获得 另一个良好的balance。 -
leaf-wise split
catboost
CatBoost是俄罗斯的搜索巨头Yandex在2017年开源的机器学习库,是Boosting族算法的一种。CatBoost和XGBoost、LightGBM并称为GBDT的三大主流神器,都是在GBDT算法框架下的一种改进实现。XGBoost被广泛的应用于工业界,LightGBM有效的提升了GBDT的计算效率,而Yandex的CatBoost号称是比XGBoost和LightGBM在算法准确率等方面表现更为优秀的算法。
CatBoost是一种基于对称决策树(oblivious trees)为基学习器实现的参数较少、支持类别型变量和高准确性的GBDT框架,主要解决的痛点是高效合理地处理类别型特征,这一点从它的名字中可以看出来,CatBoost是由Categorical和Boosting组成。此外,CatBoost还解决了梯度偏差(Gradient Bias)以及预测偏移(Prediction shift)的问题,从而减少过拟合的发生,进而提高算法的准确性和泛化能力。
与XGBoost、LightGBM相比,CatBoost的创新点有:
- 嵌入了自动将类别型特征处理为数值型特征的创新算法。首先对categorical features做一些统计,计算某个类别特征(category)出现的频率,之后加上超参数,生成新的数值型特征(numerical features)。
- Catboost还使用了组合类别特征,可以利用到特征之间的联系,这极大的丰富了特征维度。
- 采用ordered boost的方法避免梯度估计的偏差,进而解决预测偏移的问题。
- 采用了完全对称树作为基模型。
类别型特征
类别型特征的相关工作
所谓类别型特征,即这类特征不是数值型特征,而是离散的集合,比如省份名(山东、山西、河北等),城市名(北京、上海、深圳等),学历(本科、硕士、博士等)。在梯度提升算法中,最常用的是将这些类别型特征转为数值型来处理,一般类别型特征会转化为一个或多个数值型特征。
-
如果某个类别型特征基数比较低(low-cardinality features),即该特征的所有值去重后构成的集合元素个数比较少,一般利用One-hot编码方法将特征转为数值型。One-hot编码可以在数据预处理时完成,也可以在模型训练的时候完成,从训练时间的角度,后一种方法的实现更为高效,CatBoost对于基数较低的类别型特征也是采用后一种实现。
-
在高基数类别型特征(high cardinality features) 当中,比如 user ID,这种编码方式会产生大量新的特征,造成维度灾难。一种折中的办法是可以将类别分组成有限个的群体再进行One-hot编码。上述方法的一种常用解决方法是根据目标变量统计(Target Statistics,以下简称TS)进行分组,目标变量统计用于估算每个类别的目标变量期望值。甚至有人直接用TS作为一个新的数值型变量来代替原来的类别型变量。
重要的是,可以通过对TS数值型特征的阈值设置,基于对数损失、基尼系数或者均方差,得到一个对于训练集而言将类别一分为二的所有可能划分当中最优的那个,即对于不同的损失函数,使用TS数据能活动最有解。在LightGBM当中,类别型特征用每一步梯度提升时的梯度统计(Gradient Statistics,以下简称GS)来表示。虽然为建树提供了重要的信息,但是这种方法有以下两个缺点:
- 增加计算时间,因为需要对每一个类别型特征,在迭代的每一步,都需要对GS进行计算;
- 增加存储需求,对于一个类别型变量,需要存储每一次分离每个节点的类别;
为了克服这些缺点,LightGBM以损失部分信息为代价将所有的长尾类别归为一类,作者声称这样处理高基数类别型特征时比One-hot编码还是好不少。另外对于采用TS特征,仅仅为每个类别计算和存储一个数字。
采用TS作为一个新的数值型特征是最有效、信息损失最小的处理类别型特征的方法。TS也被广泛应用在点击预测任务当中,这个场景当中的类别型特征有用户、地区、广告、广告发布者等。接下来我们着重讨论TS,暂时将One-hot编码和GS放一边。
目标变量统计(Target Statistics)
-
CatBoost算法的设计初衷是为了更好的处理GBDT特征中的categorical features。在处理 GBDT特征中的categorical features的时候,最简单的方法是用 categorical feature 对应的标签的平均值来替换。在决策树中,标签平均值将作为节点分裂的标准。这种方法被称为 Greedy Target-based Statistics , 简称 Greedy TS,用公式来表达就是:
x i , k = ∑ j = 1 n [ x j , k = x i , k ] ⋅ Y j ∑ j = 1 n [ x j , k = x i , k ] x_{i,k} = \frac{\sum\limits_{j=1}^n[x_{j,k}=x_{i,k}]\cdot Y_j}{\sum\limits_{j=1}^n[x_{j,k}=x_{i,k}]} xi,k=j=1∑n[xj,k=xi,k]j=1∑n[xj,k=xi,k]⋅Yj
这种方法有一个显而易见的缺陷,就是通常特征比标签包含更多的信息,如果强行用标签的平均值来表示特征的话,当训练数据集和测试数据集数据结构和分布不一样的时候会出条件偏移问题。 -
一个标准的改进 Greedy TS的方式是添加先验分布项,这样可以减少噪声和低频率类别型数据对于数据分布的影响
x i , k = ∑ j = 1 p − 1 [ x σ j , k = x σ p , k ] ⋅ Y j + a ⋅ p ∑ j = 1 p − 1 [ x σ j , k = x σ p , k ] + a x_{i,k} = \frac{\sum\limits_{j=1}^{p-1}[x_{\sigma_{j,k}}=x_{\sigma_{p,k}}]\cdot Y_j + a\cdot p}{\sum\limits_{j=1}^{p-1}[x_{\sigma_{j,k}}=x_{\sigma_{p,k}}] + a} xi,k=j=1∑p−1[xσj,k=xσp,k]+aj=1∑p−1[xσj,k=xσp,k]⋅Yj+a⋅p
其中p是添加的先验项,a通常是大于0的权重系数。添加先验项是一个普遍做法,针对类别数较少的特征,它可以减少噪声数据。。对于回归问题,一般情况下,先验项可取数据集label的均值。对于二分类,先验项是正例的先验概率。
当然,在论文《CatBoost: unbiased boosting with categorical features》中,还提到了其它几种改进Greedy TS的方法,分别有:Holdout TS、Leave-one-out TS、Ordered TS。我这里就不再翻译论文中的这些方法了,感兴趣的同学可以自己翻看一下原论文。
- Ordered TS
它是catboost的主要思想,依赖于排序,受online learning algorithms的启发得到,对于某一个样本,TS的值依赖于观测历史,为了在离线的数据上应用该思想,我们将数据随机排序,对于每一个样本,利用该样本之前数据计算该样本类别值的TS值。如果仅仅使用一个随机序列,那么计算得到值会有较大的方差,因此我们使用不同的随机序列来计算。
CatBoost处理Categorical features总结
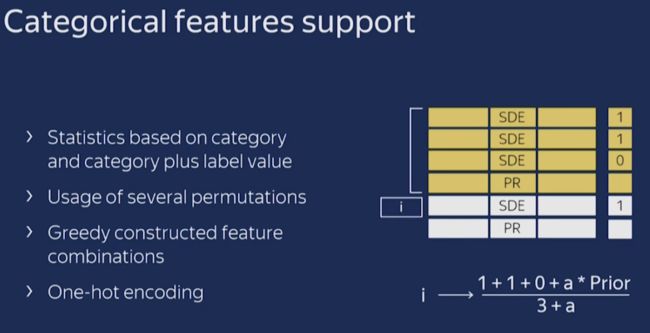
- 首先会计算一些数据的statistics。计算某个category出现的频率,加上超参数,生成新的numerical features。这一策略要求同一标签数据不能排列在一起(即先全是之后全是这种方式),训练之前需要打乱数据集。
- 第二,使用数据的不同排列(实际上是个)。在每一轮建立树之前,先扔一轮骰子,决定使用哪个排列来生成树。
- 第三,考虑使用categorical features的不同组合。例如颜色和种类组合起来,可以构成类似于blue dog这样的特征。当需要组合的categorical features变多时,CatBoost只考虑一部分combinations。在选择第一个节点时,只考虑选择一个特征,例如A。在生成第二个节点时,考虑A和任意一个categorical feature的组合,选择其中最好的。就这样使用贪心算法生成combinations。
- 第四,除非向gender这种维数很小的情况,不建议自己生成One-hot编码向量,最好交给算法来处理。
梯度偏差/预测偏移
- 为什么会有梯度偏差?
- 梯度偏差造成了什么问题?
- 如何解决梯度偏差?
为什么会有梯度偏差?
CatBoost和所有标准梯度提升算法一样,都是通过构建新树来拟合当前模型的梯度。然而,所有经典的提升算法都存在由有偏的点态梯度估计引起的过拟合问题。在每个步骤中使用的梯度都使用当前模型中的相同的数据点来估计,这导致估计梯度在特征空间的任何域中的分布与该域中梯度的真实分布相比发生了偏移,从而导致过拟合。
即一般得到一个基分类器如下(我们使用最小二乘法)
h t = a r g min h ∈ H E ( − g t ( x , y ) − h ( x ) ) 2 h^t = \underset{h\in H}{arg\min} \mathbb E(-g^t(x,y)-h(x))^2 ht=h∈HargminE(−gt(x,y)−h(x))2
理论上,我们应该使用数据真实分布来计算 g t ( x , y ) g^t(x,y) gt(x,y),但实际上,我们使用已知有标签但数据样本来计算。这样导致在测试样本中 g t ( x , y ) ∣ x g^t(x,y)|x gt(x,y)∣x中分布不同于在训练样本中 g t ( x k , y k ) ∣ x k g^t(x_k,y_k)|x_k gt(xk,yk)∣xk,这样得到的基分类器偏离真实,引起预测偏移,影响模型的泛化能力。
梯度偏差造成了什么问题?
模型过拟合,预测偏移,在预测偏移里,论文提到不仅对特征对处理存储target leak,在普通对gdbt算法中,也就是样本分布不同引起对梯度偏差问题中,也存储target leak问题。
如何解决梯度偏差?
为了解决这个问题,CatBoost对经典的梯度提升算法进行了一些改进,简要介绍如下:
许多利用GBDT技术的算法(例如,XGBoost、LightGBM),构建下一棵树分为两个阶段:选择树结构和在树结构固定后计算叶子节点的值。为了选择最佳的树结构,算法通过枚举不同的分割,用这些分割构建树,对得到的叶子节点计算值,然后对得到的树计算评分,最后选择最佳的分割。两个阶段叶子节点的值都是被当做梯度或牛顿步长的近似值来计算。
在CatBoost中,第一阶段采用梯度步长的无偏估计,第二阶段使用传统的GBDT方案执行。既然原来的梯度估计是有偏的,那么怎么能改成无偏估计呢?
设 F i F^i Fi为构建i棵树后的模型, g i ( X k , y k ) g^i(X_k, y_k) gi(Xk,yk)为构建i棵树后第k个训练样本上面的梯度值。**为了使得 g i ( X k , y k ) g^i(X_k, y_k) gi(Xk,yk)无偏于模型 F i F^i Fi,我们需要在没有 X k X_k Xk参与的情况下对模型 F i F^i Fi进行训练。**我们需要对所有训练样本计算无偏的梯度估计
我们运用下面这个技巧来处理这个问题:对于每一个样本 X k X_k Xk,我们训练一个单独的模型 M k M_k Mk(该模型由多颗树组成),且该模型从不使用基于该样本的梯度估计进行更新。我们使用 M k M_k Mk估计上 X k X_k Xk的梯度(即叶子节点的值),并使用这个估计对结果树进行评分。用伪码描述如下,其中 L o s s ( y i , a ) Loss(y_i, a) Loss(yi,a)是需要优化的损失函数,y是标签值,a是公式计算值。
 值得注意的是模型的建立并没有样本 的参与,并且CatBoost中所有的树的共享同样的结构。
值得注意的是模型的建立并没有样本 的参与,并且CatBoost中所有的树的共享同样的结构。
也即在不使用样本 X i X_i Xi的情况下对 M i M_i Mi进行训练,并且训练得到对所有 M i M_i Mishare同样对树结构。 M i ( X i ) M_i(X_i) Mi(Xi)表示模型 M i M_i Mi对 X i X_i Xi进行打分。
这里为了进一步减少过拟合,会使用若干不同对扰动来加强算法鲁棒性。也即上述提到对用于计算类别特征的方法,我们获取s个随机扰动排列,对于每个排列,我们又训练n个不同的模型 M i M_i Mi,这样模型模型复杂度为 O ( s n 2 ) O(sn^2) O(sn2),后续进行优化,具体算法流程部分;
其他
特征组合
CatBoost的另外一项重要实现是将不同类别型特征的组合作为新的特征,以获得高阶依赖(high-order dependencies),比如在广告点击预测当中用户ID与广告话题之间的联合信息,又或者在音乐推荐引用当中,用户ID和音乐流派,如果有些用户更喜欢摇滚乐,那么将用户ID和音乐流派分别转换为数字特征时,这种用户内在的喜好信息就会丢失。然而,组合的数量会随着数据集中类别型特征的数量成指数增长,因此在算法中考虑所有组合是不现实的。为当前树构造新的分割点时,CatBoost会采用贪婪的策略考虑组合。对于树的第一次分割,不考虑任何组合。对于下一个分割,CatBoost将当前树的所有组合、类别型特征与数据集中的所有类别型特征相结合,并将新的组合类别型特征动态地转换为数值型特征。CatBoost还通过以下方式生成数值型特征和类别型特征的组合:树中选定的所有分割点都被视为具有两个值的类别型特征,并像类别型特征一样地被进行组合考虑。
当特征组合由原始的1到2时,logloss的logloss部分提升(logloss实际数值降低的)为1.86%,从1到3提升2.04%
快速评分
CatBoost使用对称树(oblivious trees)作为基预测器。在这类树中,相同的分割准则在树的整个一层上使用。这种树是平衡的,不太容易过拟合。梯度提升对称树被成功地用于各种学习任务中。在对称树中,每个叶子节点的索引可以被编码为长度等于树深度的二进制向量。这在CatBoost模型评估器中得到了广泛的应用:我们首先将所有浮点特征、统计信息和独热编码特征进行二值化,然后使用二进制特征来计算模型预测值。
另外,对于最终模型的评价,对于训练样本i,使用 l e a f 0 ( i ) leaf_0(i) leaf0(i)来表示预测结果。对于测试集合,我们根据整个训练的TS计算相应类别的值
基于GPU实现快速训练
密集的数值特征。 对于任何GBDT算法而言,最大的难点之一就是搜索最佳分割。尤其是对于密集的数值特征数据集来说,该步骤是建立决策树时的主要计算负担。CatBoost使用oblivious 决策树作为基模型,并将特征离散化到固定数量的箱子中以减少内存使用。就GPU内存使用而言,CatBoost至少与LightGBM一样有效。主要改进之处就是利用了一种不依赖于原子操作的直方图计算方法。
类别型特征。 CatBoost实现了多种处理类别型特征的方法,并使用完美哈希来存储类别型特征的值,以减少内存使用。由于GPU内存的限制,在CPU RAM中存储按位压缩的完美哈希,以及要求的数据流、重叠计算和内存等操作。通过哈希来分组观察。在每个组中,我们需要计算一些统计量的前缀和。该统计量的计算使用分段扫描GPU图元实现。
多GPU支持。 CatBoost中的GPU实现可支持多个GPU。分布式树学习可以通过数据或特征进行并行化。CatBoost采用多个学习数据集排列的计算方案,在训练期间计算类别型特征的统计数据。
算法流程
建树的流程:
开始阶段:CatBoost对训练集随机生成s+1个不同对序列,其中 σ 1 , σ 2 , . . . , σ n \sigma_1, \sigma_2,...,\sigma_n σ1,σ2,...,σn用于定义树结构,分裂节点的计算。 σ 0 \sigma_0 σ0用于对生成树结构选择叶子节点对值。
在catboost中,基分类器是对称树,该类树平衡,能够减弱过拟合,加速预测,整体流程为:

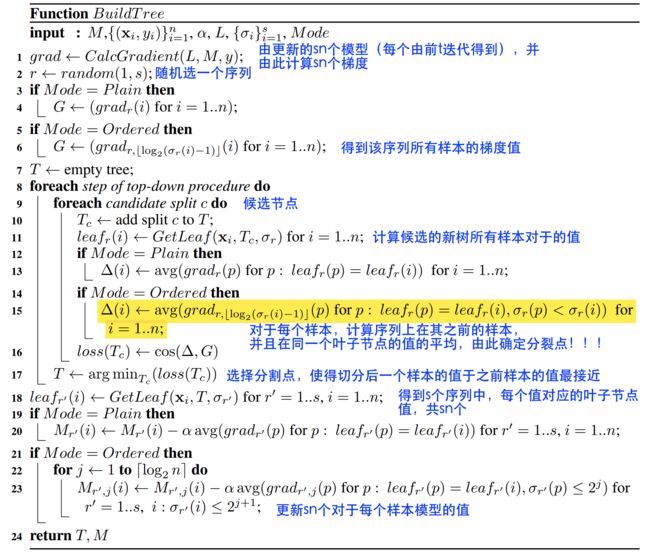
- 其中ordered boosting如下,ordered boosting不仅对类别进行特征处理,还处理引起梯度偏差对问题, 其会训练n个模型,这也会n倍地增加了时间复杂度,为了简化,我们优化其时间复杂度,仅仅储存和计算 M r , j ′ ( i ) : = M , 2 j f o r j = 1 , . . . , [ l o g 2 n ] M'_{r,j}(i):=M_{,2^j} for j=1,...,[log_2 n] Mr,j′(i):=M,2jforj=1,...,[log2n],并且有 σ r ( i ) ≤ 2 j + 1 \sigma_r(i)\leq 2^{j+1} σr(i)≤2j+1,这样总体时间复杂度由 O ( s n 2 ) O(sn^2) O(sn2)转化为 O ( s n ) O(sn) O(sn):


总结
优点
- 性能卓越: 在性能方面可以匹敌任何先进的机器学习算法;
- 鲁棒性/强健性: 无需调参即可获得较高的模型质量,采用默认参数就可以获得非常好的结果,减少在调参上面花的时间,减少了对很多超参数调优的需求
- 易于使用: 提供与scikit集成的Python接口,以及R和命令行界面;
- 实用: 可以处理类别型、数值型特征,支持类别型变量,无需对非数值型特征进行预处理=
-
- 可扩展: 支持自定义损失函数;
有以下优势:
- 快速、可扩展的GPU版本,可以用基于GPU的梯度提升算法实现来训练你的模型,支持多卡并行提高准确性,
- 提出一种全新的梯度提升机制来构建模型以减少过拟合
- 快速预测,即便应对延时非常苛刻的任务也能够快速高效部署模型
缺点
对于类别型特征的处理需要大量的内存和时间;
不同随机数的设定对于模型预测结果有一定的影响;
https://www.cnblogs.com/nxf-rabbit75/p/10923549.html
https://blog.csdn.net/friyal/article/details/82758532
https://blog.csdn.net/appleyuchi/article/details/85413352
问题
XGBoost中如何对树进行剪枝
在目标函数中增加了正则项:使用叶子结点的数目和叶子结点权重的L2模的平方,控制树的复杂度。
在结点分裂时,定义了一个阈值,如果分裂后目标函数的增益小于该阈值,则不分裂。
当引入一次分裂后,重新计算新生成的左、右两个叶子结点的样本权重和。如果任一个叶子结点的样本权重低于某一个阈值(最小样本权重和),也会放弃此次分裂。
XGBoost 先从顶到底建立树直到最大深度,再从底到顶反向检查是否有不满足分裂条件的结点,进行剪枝。
XGBoost如何选择最佳分裂点?
Xgboost支持两种分裂节点的算法,一是exact greedy algorithm 精确贪心算法,另一个是approximate algorithm 近似算法
- exact greedy algorithm
对于exact greedy算法来说,Xgboost将所有的数据放到了一个Block中。在Block中,可以同时对所有叶子进行分裂点的计算,因此对Block进行一次扫描将可以得到所有叶子的分割特征点候选者的统计数据。
树的深度为0开始,整个过程为:
- 对每个叶节点枚举所有的可用特征;
- 针对每个特征,把属于该节点的训练样本根据该特征值进行升序排列,通过线性扫描的方式来决定该特征的最佳分裂点,并记录该特征的分裂收益;
- 选择收益最大的特征作为分裂特征,用该特征的最佳分裂点作为分裂位置,在该节点上分裂出左右两个新的叶节点,并为每个新节点关联对应的样本集;
- 回到第1步,递归执行直到满足特定条件为止;
- 具体在做时,我们事先计算每个点的一阶 g i g_i gi和二阶梯度 h i h_i hi,然后线性扫描分别得到左右的值,如下图,其中二阶导数亦直接相加:


- approximate algorithm
贪心算法可以得到最优解,但当数据量太大时则无法读入内存进行计算,近似算法主要针对贪心算法这一缺点给出了近似最优解。
为了解决上述为了,对于每个特征,不在遍历所有的点,而且根据数据的特征分布,划分各个小区间,遍历时仅仅考虑边界点,根据聚合信息找出最佳的边界点。
在提出候选切分点时有两种策略:
- Global: 学习每棵树前就提出候选切分点,并在每次分裂时都采用这种分割;
- Local:每次分裂前将重新提出候选切分点。直观上来看,Local策略需要更多的计算步骤,而Global策略因为节点已有划分所以需要更多的候选点。
算法流程:
- 首先对k个特征,依次根据特征分布找到l个切分点 S k = { s k 1 , s k 2 , . . . , s k l } S_k=\{s_{k1},s_{k2},...,s_{kl}\} Sk={ sk1,sk2,...,skl},分为global和local
- 根据划分点,计算每个分桶区间 s k , v ≥ x j k > s k , v − 1 s_{k,v}\geq x_{jk} > s_{k,v-1} sk,v≥xjk>sk,v−1内G,H的累加
- 最后依次扫描切分点,得到最佳分裂点。

举例,根据特征的三分位点来划分:
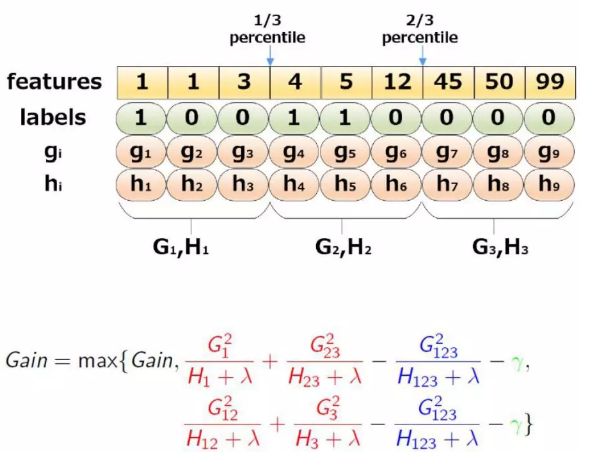
- 加权分位数
我们在approximate 算法中,实际上并不是单纯根据数据个数来进行分位,而是是二阶导数值 h i h_i hi作为样本的权重进行划分。为了处理带权重的候选节点的选取,作者提出Weighted Quantile Sketch算法。举例说明:

为什么使用二阶导数 h i h_i hi作为样本加权呢?
我们知道目标函数可转为,其中t表示第t颗函数(树)
o b j t ≃ ∑ i = 1 n [ g i f t ( x i ) + 1 2 h i f t 2 ( x i ) ] + ∑ i = 1 t Ω ( f t ) = ∑ i = 1 n 1 2 h i [ f t ( x i ) + g i h i ] 2 + Ω ( f t ) − c o n s t a n t \begin{aligned} obj^t \simeq & \sum\limits_{i=1}^n[g_i f_t(x_i) + \frac12h_i f_t^2(x_i)] +\sum\limits_{i=1}^t \Omega(f_t) \\ =& \sum\limits_{i=1}^n \frac12 h_i[f_t(x_i)+\frac{g_i}{h_i}]^2 + \Omega(f_t)-constant \end{aligned} objt≃=i=1∑n[gift(xi)+21hift2(xi)]+i=1∑tΩ(ft)i=1∑n21hi[ft(xi)+higi]2+Ω(ft)−constant
其中 1 2 g i 2 h i \frac12\frac{g_i^2}{h_i} 21higi2为常数,是因为此值为上一轮损失函数求导,从最终式子可以看到 h i h_i hi就是平方损失函数样本的权重。
- 缺失值处理
分布枚举特征缺省的样本归为左右分支后的增益,选择增益最大的枚举项即为最优缺省方向
Xgboost 工程上对于加速怎么处理的?
- 列块并行学习
在树生成过程中,最耗时的一个步骤就是在每次寻找最佳分裂点时都需要对特征的值进行排序。而 XGBoost 在训练之前会根据特征对数据进行排序,然后保存到块结构中,并在每个块结构中都采用了稀疏矩阵存储格式(Compressed Sparse Columns Format,CSC)进行存储,后面的训练过程中会重复地使用块结构,可以大大减小计算量。
作者提出通过按特征进行分块并排序,在块里面保存排序后的特征值及对应样本的引用,以便于获取样本的一阶、二阶导数值。具体方式如图:

实验证明,Global策略在设置候选节点多时可以和Local策略在候选节点少时具有相似的精度,此外,在候选节点设置合理的情况下,分位数策略可以获得与贪心算法相同的精度。
对于approximate算法来说,Xgboost使用了多个Block,存在多个机器上或者磁盘中。每个Block对应原来数据的子集。不同的Block可以在不同的机器上计算。该方法对Local策略尤其有效,因为Local策略每次分支都重新生成候选切分点。
通过特征的分布,按照分布式加权直方图算法确定一组候选分裂点,通过遍历所有的候选分裂点来找到最佳分裂点。
在寻找split point的时候,不会枚举所有的特征值,而会对特征值进行聚合统计,然后形成若干个bucket(桶),只将bucket边界上的特征值作为split point的候选,从而获得性能提升。
Block结构还有其它好处,数据按列存储,可以同时访问所有的列,很容易实现并行的寻找分裂点算法。缺点是空间消耗大了一倍。
Xgboost特征重要性
提供了三种特征重要性的方法
- weight 就是所有树中特征用来分隔的节点个数总和;
the number of times a feature is used to split the data across all trees. - gain 特征用户分隔的平均增益
the average gain across all splits the feature is used in - cover, 被分到该节点的样本的二阶导数之和,而特征度量的标注就是平均voverage值。the sum of second order gradient of training data classified to the leaf, if it is square loss, this simply corresponds to the number of instances in that branch. Deeper in the tree a node is, lower this metric will be
- total_gain
- total_cover
特征重要性可以用来做模型可解释性,这在风控等领域是非常重要的方面。xgboost实现中Booster类get_score方法输出特征重要性,其中importance_type参数支持三种特征重要性的计算方法:
- importance_type=weight(默认值),特征重要性使用特征在所有树中作为划分属性的次数。
- importance_type=gain,特征重要性使用特征在作为划分属性时loss平均的降低量。
- importance_type=cover,特征重要性使用特征在作为划分属性时对样本的覆盖度。(划分多次时采用的是平均样本覆盖度)
-
gbdt的特征重要性
-
根据分裂前后impurity的减少量来评估,分裂标准有
- Entropy:熵,适用分类树
- Gini:基尼系数,适用分类树
- MSE:均方误差,适用回归树
- MAE:平均绝对误差,适用回归树
node.weighted_n_node_samples * node.impurity - left.weighted_n_node_samples * left.impurity - right.weighted_n_node_samples * right.impurity
参考
- CatBoost vs. Light GBM vs. XGBoost
- catboost tutorial
- 深入理解LightGBM
- LightGBM的并行优化
- LightGBM详解之常用并行计算算子原理及其在LightGBM中的实现
- 对缓存的思考——提高命中率
- 深入理解XGBoost
- 一文详尽系列之CatBoost
[](https://mp.weixin.qq.com/s/E3pSPsG18053F5GG1Z8jNQ)