看到学习群中有战友自行开始研究pandas等相关库的数据分析应用,自愧不如,得抓紧脚步,只能在其基础上自己试试文件操作该如何实现。
1、实现环境python3;需要的包:os,pandas_datareader中的data,matplotlib,pandas;
2、pandas_datareader库可用于从不同财经数据平台读取需要的数据,数据全面,包含全球主要股市。我们选择雅虎财经来获取数据。将其读取的数据存储在本地,因为需要翻墙所以存储于本地方便代码调试,防止网络不稳定重复链接增加链接中断的风险。先看看其中的属性和方法都有哪些:

表示看不懂,具体参数使用见链接
https://www.jianshu.com/p/ed947ada9331?utm_campaign=haruki&utm_content=note&utm_medium=reader_share&utm_source=weixin
3、将其可按照json格式存储为csv文件,但是默认会将日期列剔除,(补充:看了官方文档才知道,并不是把日期剔除人是默认按照列的名字为第一关键字columns,索引——日期为第二关键字进行的数据存储,如果要把每一天的数据一一对应,需要orient关键字指定为index,并且默认存储日期为时间戳的格式),不利于可视化;

pd.read_json()
读取文件默认是按照日期索引读取,但读取出的文件并不包括日期;文件的每一列相当于一个带关键字的列表;可通过.key或['key']方式直接调用;具体操作可见C12-3。在这里不建议用json格式读取和存储。
4、将其按照csv格式存储;
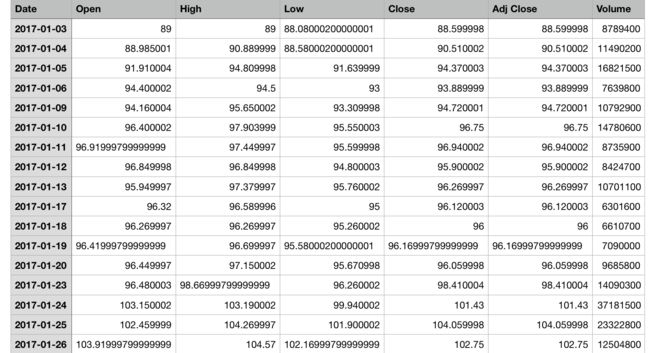
pd.read_csv()
读取出的是标准csv格式文件,但需要对日期做额外的处理;
dateparse1 = lambda dates: pd.datetime.strptime(dates, '%Y-%m-%d')
需要注意的是python3默认就是用utf-8方式编码,读取时对日期这样的字节格式并不需要再去定义编码方式,也就是说直接去掉python2中要用到的encoding='utf-8'就好;否则会引发“UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 0: invalid start byte”,这样的错误。
将日期作为索引去读取文件时,读取的数据会自动忽略日期这一关键字,相当于被覆盖;并且读取为日期格式时,以ns(纳秒)为默认转换方式。

因为我们需要得出每只股票的年增长率,所以需要很方便的得到第一个日期的收盘价和最后一个日期的收盘价,然后算出年增长率。
def c_ratio(d_close):
"""
analyse the incresing ratio of a stock
:param d_close:
:return: a num
"""
o_price = d_close.Close[0]
c_price = d_close.Close[-1]
# 跟上述方式效果相同
# o_price = d_close['Close'][0]
# c_price = d_close['Close'][-1]
# 计算数据,通过round方法四舍五入,取小数点后四位数,在换算为百分比
ratio = '%.2f%%' % (round(((c_price - o_price) / o_price), ndigits=4) * 100)
return ratio
需要注意的是,按照指定索引去读取的数据结构,每一列相当于列表,可通过[-1]的方式轻松找到最后一个数;如果不指定日期为索引,pandas默认会为数据建立相应的索引,值得注意的是并不会对每列数据按照索引进行深加工将其转变为Series,而是ndarray。如此将不能很方便的找到最后一个数据用于计算(如果用的话);因为按csv格式读取是按行读取,如果不事先看数据,不知道最后一行到底是多少。
但通过指定索引,如果用plt.plot(data)的方式将不能自动按照日期来成图,而是按照默认索引;如果要用上述方式成图需指定日期列,会发现日期列被覆盖,将索引重新赋给日期字典,还需要对每一行都用apply方法建立关联。所以二者是一对矛盾,还未研究透。如果用别的列来建立索引,仍然不能当做Series来看待,求增长率时将不能用[0]、[-1]的方式轻松找到最后一个数。
所以最简便的办法就是指定日期为索引,直接使用指定数据列去绘图的方式来可视化,也就是df['key].plot(自定义设置)(补充:看文档之后,原来这种成图方式是pandas自带的成图模式,可直接用索引成图,并非pyplot中的方式),不再需要指定横坐标——日期;
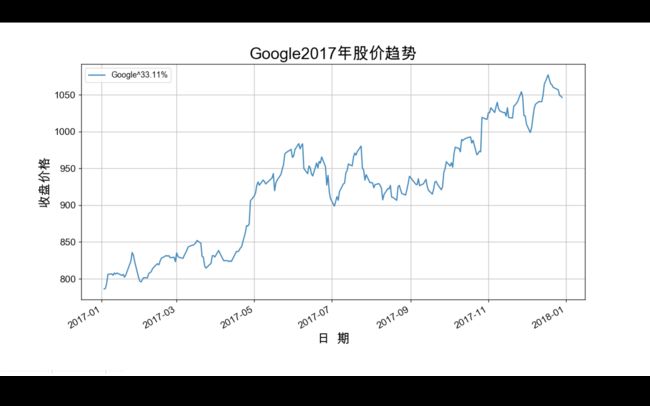
d_g['Close'].plot(label="Google" + '^' + str(c_ratio(d_g)))
pandas不能直接用文件格式不匹配的方式读取相应文件,会出错,但csv和json可以通过运算方式转换;
最终结果是这样:
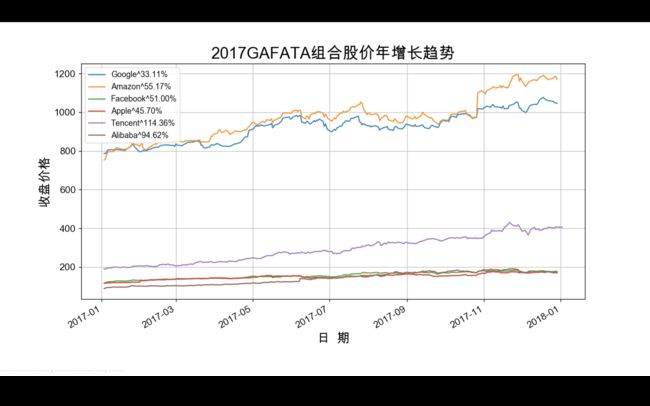
代码如下:
# !/usr/bin/env python
# -*- encoding: utf-8 -*-
"""
Attempt to make a graph compare with some stocks
"""
import os
import pandas as pd
from pandas_datareader import data
import matplotlib.pyplot as plt
# 对应股票名称和对应代码
dic = {'谷歌': 'GOOG', '亚马逊': 'AMZN', '脸书': 'FB',
'阿里巴巴': 'BABA', '腾讯': '0700.hk', '苹果': 'AAPL', }
# Set the date
start_date = '2017-1-1'
end_date = '2018-1-1'
# Attempt to check the files, if it does'n exit,try to get it.
if (os.path.exists('./google_to.csv') and os.path.exists('./Amazon_to.csv') and
os.path.exists('./FB_to.csv') and os.path.exists('./ali_to.csv') and
os.path.exists('./apple_to.csv') and os.path.exists('./tencent_to.csv')
):
dateparse1 = lambda dates: pd.datetime.strptime(dates, '%Y-%m-%d')
d_g = pd.read_csv('./google_to.csv',skiprows=0, index_col='Date',
date_parser=dateparse1, parse_dates=True,
)
d_am = pd.read_csv('./Amazon_to.csv', skiprows=0, index_col='Date',
date_parser=dateparse1, parse_dates=True,
)
d_f = pd.read_csv('./FB_to.csv', skiprows=0, index_col='Date',
date_parser=dateparse1, parse_dates=True,
)
d_a = pd.read_csv('./apple_to.csv', skiprows=0, index_col='Date',
date_parser=dateparse1, parse_dates=True,
)
d_ten = pd.read_csv('./tencent_to.csv', skiprows=0, index_col='Date',
date_parser=dateparse1, parse_dates=True,
)
d_baba = pd.read_csv('./ali_to.csv', skiprows=0, index_col='Date',
date_parser=dateparse1, parse_dates=True,
)
else:
d_g = data.get_data_yahoo(dic['谷歌'], start_date, end_date)
try:
with open('./google_to.csv', 'w') as f:
f.write(d_g.to_csv())
except IOError:
print ("Please check your code,dedicate space.")
else:
d_g.head() #文件操作后会释放变量,这一行在执行时并不显示
d_am = data.get_data_yahoo(dic['亚马逊'], start_date, end_date)
try:
with open('./Amazon_to.csv', 'w') as f:
f.write(d_am.to_csv())
except IOError:
print ("Please check your code,dedicate space.")
else:
pass
d_f = data.get_data_yahoo(dic['脸书'], start_date, end_date)
try:
with open('./FB_to.csv', 'w') as f:
f.write(d_f.to_csv())
except IOError:
print ("Please check your code,dedicate space.")
else:
pass
d_a = data.get_data_yahoo(dic['苹果'], start_date, end_date)
try:
with open('./apple_to.csv', 'w') as f:
f.write(d_a.to_csv())
except IOError:
print ("Please check your code,dedicate space.")
else:
pass
d_ten = data.get_data_yahoo(dic['腾讯'], start_date, end_date)
try:
with open('./tencent_to.csv', 'w') as f:
f.write(d_ten.to_csv())
except IOError:
print ("Please check your code,dedicate space.")
else:
pass
d_baba = data.get_data_yahoo(dic['阿里巴巴'], start_date, end_date)
try:
with open('./ali_to.csv', 'w') as f:
f.write(d_baba.to_csv())
except IOError:
print ("Please check your code,dedicate space.")
else:
pass
def c_ratio(d_close):
"""
analyse the incresing ratio of a stock
:param d_close:
:return: a num
"""
o_price = d_close.Close[0]
c_price = d_close.Close[-1]
# o_price = d_close['Close'][0]
# c_price = d_close['Close'][-1]
ratio = '%.2f%%' % (round(((c_price - o_price) / o_price), ndigits=4) * 100)
return ratio
# print(c_ratio(d_g)) # 测试代码用
# Set the font to support Chinese
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
# Let's make grapha
fig = plt.figure(dpi=128, figsize=(10, 6))
# d_g['date'] = d_g.index
# plt.plot(d_g['date'], d_g['Close'], color='r',
# label='Google'+ '^' + str(c_ratio(d_g)))
d_g['Close'].plot(label="Google" + '^' + str(c_ratio(d_g)))
d_am['Close'].plot(label='Amazon' + '^' + str(c_ratio(d_am)))
d_f['Close'].plot(label='Facebook' + '^' + str(c_ratio(d_f)))
d_a['Close'].plot(label='Apple' + '^' + str(c_ratio(d_a)))
d_ten['Close'].plot(label='Tencent' + '^' + str(c_ratio(d_ten)))
d_baba['Close'].plot(label='Alibaba' + '^' + str(c_ratio(d_baba)))
plt.title('2017GAFATA组合股价年增长趋势', fontsize=20)
plt.xlabel('日 期', fontsize=16)
plt.ylabel('收盘价格', fontsize=16)
plt.tick_params(axis='both', labelsize=12, which='major')
plt.grid(True)
plt.legend(loc=2)
plt.show()
# plt.savefig('GAFATA.png', bbox='tight')
编写代码过程中的不足:
1、对pandas还是不熟,需要看文档系统学习,对不同格式数据操作和优劣要有系统认知;
2、对matplotlib还是不熟,图层设置总是想不起该是哪些方法,还需要多练习;
3、文件操作要考虑很多因素,所以需要经常锻炼用try方法来写代码;如果有比较有效的内建函数可以判断,就直接用函数;
4、对python的错误类型了解不深入,还需加强;
5、利用单个股票数据首先验证想法,再去实现全部会是个不错的选择;
6、为实现某一功能的代码块编写代码注释是需要养成的习惯;
7、因为有时候偶要用python2,见C12-5,重写了一份matplotlibrc文件内容是TkAGG模式,python3中不太支持plot,移动图层会出现编码错误的警告,所以还是需要删除该文件,使用3默认的API。