Joshua Bloch错了? ——适当改变你的Builder模式实现
注:这一系列都是小品文。它们偏重的并不是如何实现模式,而是一系列在模式实现,使用等众多方面绝对值得思考的问题。如果您仅仅希望知道一个模式该如何实现,那么整个系列都会让您失望。如果您希望更深入地了解各个模式的常用法,并对各个模式进行深入地思考,那么希望您能喜欢这一系列文章。
在昏黄的灯光下,我开始了晚间阅读。之所以有这个习惯的主要原因还是因为我的睡眠一直不是很好。所以我逐渐养成了在晚九点以后看一会儿技术书籍以辅助睡眠的习惯。
今天随手拿起的是Effective Java的英文第二版。说实话,由于已经看过了Effective Java的第一版,因此我一直没有将它的第二版放在心上。
这是Builder么?
在看到第二个条目的时候,我就产生了一个大大的疑惑。该条目说如果一个构造函数或工厂模式拥有太多的可选参数,那么Builder模式是一个很好的选择。但是该条目所给出的Builder模式实现却非常奇怪(Java代码):
// JAVA代码 // Builder Pattern public class NutritionFacts { private final int servingSize; private final int servings; private final int calories; private final int fat; private final int sodium; private final int carbohydrate; public static class Builder { // Required parameters private final int servingSize; private final int servings; // Optional parameters - initialized to default values private int calories = 0; private int fat = 0; private int carbohydrate = 0; private int sodium = 0; public Builder(int servingSize, int servings) { this.servingSize = servingSize; this.servings = servings; } public Builder calories(int val) { calories = val; return this; } public Builder fat(int val) { fat = val; return this; } public Builder carbohydrate(int val) { carbohydrate = val; return this; } public Builder sodium(int val) { sodium = val; return this; } public NutritionFacts build() { return new NutritionFacts(this); } } private NutritionFacts(Builder builder) { servingSize = builder.servingSize; servings = builder.servings; calories = builder.calories; fat = builder.fat; sodium = builder.sodium; carbohydrate = builder.carbohydrate; } }
或许您脑中的疑问和我一样,这是Builder么?
标准的Builder实现
既然有了这个疑问,我就开始在脑中回忆起Builder模式标准实现的类图:
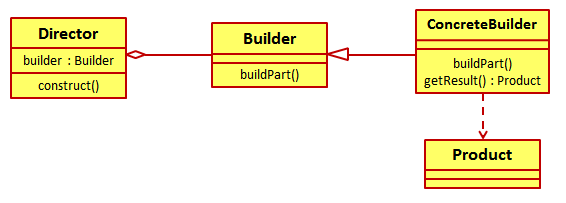
在该类图中主要有两部分组成:Director以及Builder。Director用来制定产品的创建步骤,而Builder则用来为Director提供产品的各个组件。而在这两部分组成中,Director表示的是产品组装步骤,是Builder模式中的不变。而Builder类则是一个基类。各个ConcreteBuilder从它派生并定义组成产品的各个组成,是Builder模式中变化的部分,也是Builder模式中可以扩展的部分。
因此,其标准实现应如下所示:
// C++代码 #include <iostream> using namespace std; class Builder; class Director; class Product; class ConcreteBuilder; // Builder的公共接口,提供接口给Director以允许调用Builder类的各成员以控制流程 class Builder { // 由于各个build*函数需要按照一定次序调用才能成功地创建产品,因此为了避免 // 由于外部误调用而影响状态机,因此将Builder的各个build*函数设置为私有 // 并声明Director为其友元类 friend class Director; private: // Builder中的各个build*函数一般无返回值。这是因为每次build*的结果实际上 // 与所创建的产品相关。如果将其作为返回值返回,那么就会强制要求所有的 // ConcreteBuilder返回同一类型数据,而且Director也需要知道并使用这些数据, // 进而造成了Director,Builder以及产品之间的耦合 virtual void buildPartA() = 0; virtual void buildPartB() = 0; public: virtual Product* GetResult() = 0; }; // 控制产品的创建流程,是Builder模式中的不变 class Director { Builder* m_pBuilder; public: Director(Builder* pBuilder) { m_pBuilder = pBuilder; } // 启动Builder模式的产品创建流程,而具体创建方式则由Builder类自行决定 void Construct() { m_pBuilder->buildPartA(); m_pBuilder->buildPartB(); } }; class Product { // 由于产品的创建都是通过ConcreteBuilder来完成的,因此声明产品类的各个 // 成员为私有,并声明ConcreteBuilder为其友元,从而达到只允许通过 // ConcreteBuilder创建产品实例的目的 friend class ConcreteBuilder; private: struct PartA {}; struct PartB {}; // 传入指针,而不是引用,以允许某些part为空的情况 Product(PartA* pPartA, PartB* pPartB) { …… } public: void printInfo(); }; // Builder的实际实现 class ConcreteBuilder : public Builder { Product::PartA* m_pPartA; Product::PartB* m_pPartB; private: // 重写私有虚函数以提供实际的组成的实际创建逻辑。私有并不会阻止虚函数的 // 调用及重写。这是两个完全不相干的特性,彼此不会相互影响,也不会由于私有 // 函数无法被派生类访问而无法被重写 virtual void buildPartA(); virtual void buildPartB(); public: virtual Product* GetResult(); }; void ConcreteBuilder::buildPartA() { m_pPartA = new Product::PartA(); }; void ConcreteBuilder::buildPartB() { m_pPartB = new Product::PartB(); }; Product* ConcreteBuilder::GetResult() { return new Product(m_pPartA, m_pPartB); }; void Product::printInfo() { cout << "Product constructed by builder pattern." << endl; }; int _tmain(int argc, _TCHAR* argv[]) { // 创建Builder及Director,并通过调用Director的Construct()函数来创建实例 Builder* pBuilder = new ConcreteBuilder(); Director* pDirector = new Director(pBuilder); pDirector->Construct(); // 通过调用Builder的GetResult()函数得到产品实例 Product* pProduct = pBuilder->GetResult(); pProduct->printInfo(); return 0; }
Joshua没有错
“标准实现和Joshua所提供的Builder模式实现竟然有如此大的差别,难道是Joshua错了吗?”我躺在床上想到。仔细地查看了Joshua所提供的Builder模式实现,发现其和标准的Builder模式有以下一系列不同:
- 没有Director类,对产品的创建是通过Builder的build()函数来完成的。
- 没有基类Builder,而每个ConcreteBuilder都被实现为产品的嵌套类。
那省略掉的这两个组成在Builder模式中都是用来做什么的呢?在Builder模式中,Director用来表示一个产品的固定的创建步骤,它操作的是基类Builder所定义的接口。该接口定义了Director和各个ConcreteBuilder进行沟通的契约,而各个ConcreteBuilder都需要按照这些接口来组织自己的产品创建逻辑。
也就是说,Director和各个Builder之间的关系实际上就是对产品创建这一个任务执行开闭原则(Open-Close Principle)所产生的结果:Director和基类Builder定义了产品创建的“闭”,即固定的不应被修改的逻辑。而各个ConcreteBuilder则通过从基类Builder派生来自行定义产品中的各个组成的创建逻辑,也即是Builder模式中的“开”。这样Director中所定义的产品创建步骤可以被各个产品的创建过程重用了。
而对Director和基类Builder的省略实际上就是将Builder中固定的产品创建步骤省略了,剩下的仅仅是开放的用来创建产品的实际逻辑。这实际上就是Builder模式中产品创建步骤退化所产生的效果。
“既然Builder模式已经退化成了单个的彼此不再相关的类,那它还叫Builder模式么?”我问自己。显然,从开闭原则的角度来解释仅仅能说明这种使用方法可以被认为是从Builder模式演化过来的,却不能说服我这是一个Builder模式。
我再次拿起了书,想从书中寻找一些线索。在读到这节中间的时候,我便有了答案。该条目所说的实际上是在利用Builder模式中各个ConcreteBuilder的一个特性:如果将Builder中的各个ConcreteBuilder当作是一个Context,那么其将在可选值方面提供较大的灵活度。
所有的一切都是从一个非常复杂的构造函数开始说起的。如果创建一个对象需要向构造函数中传入非常多的参数,而且有些参数是可选的,那么为了使用方便,我们需要提供一个包含了所有参数的构造函数:
// Java代码 public class NutritionFacts { public NutritionFacts(int servingSize, int servings, int calories, int fat, int sodium, int carbohydrate) { …… } }
在这种情况下,我们就需要按照如下的方法对该构造函数进行调用:
NutritionFacts cocaCola = new NutritionFacts(240, 8, 100, 0, 35, 27);
但这种方法对可选的营养成分而言并不友好。因此另一种选择被提出了,那就是JavaBean模式:
// Java代码 public class NutritionFacts { public void setServingSize(int servingSize) …... public void setServings(int servings) …… public void setCalories(int calories) …… …… }
但这种解决方案还是有问题,那就是各个参数之间的关联关系。例如食物中所有的卡路里实际上是与该食物的重量以及单位重量中所包含的卡路里相关的。因此我们还需要在setCalories(),setServings()以及setServingSize()中执行输入数据是否正确的检查。而这些检查需要放在哪里呢?setCalories()等函数中?那么这些检查逻辑需要考虑到calories,servings以及servingSize等参数还没有被设置的情况,而且每次对这些数据的更改都会导致该检查的执行。
Joshua提出的解决方案则是Builder模式。该方案所利用的就是Builder模式中的ConcreteBuilder可以很好地处理可选组成并支持数据检查的特性:
// Java代码 NutritionFacts cocaCola = new NutritionFacts.Builder(240, 8) .calories(100) .sodium(35) .carbohydrate(27) .build();
上面的代码主要分为三个部分:对NutritionFacts.Builder的创建,通过.calories()等函数对可选组成的设置,以及通过.build()函数创建NutritionFacts实例。其中在创建NutritionFacts.Builder时我们需要为该类型的构造函数指定构造函数所需要的参数,实际上也就是在指定各个必选组成。接下来,我们就可以根据需要调用.calories()等函数完成对可选参数的设置。这两部分代码实际上就是在对各个必选组成和可选组成进行处理。而最后对.build()函数的调用则用来创建NutritionFacts实例,也是在该解决方案中执行各设置检查的地方。
简单地说,在Builder模式中,ConcreteBuilder具有如下两个特点:
- 非常适合处理一个实例具有一系列可选组成的情况
- 可以在创建产品实例前执行额外的自定义逻辑
这些特点实际上在Gang of Four的设计模式一书中并没有被显式提及,而Joshua却对这些特征好好地加以了利用。
“啊”,我恍然大悟。实际上并不是Joshua不知道一个标准的Builder模式是如何实现的。只是因为这个条目中所需要处理的情况实际上可以通过Builder模式中的ConcreteBuilder一个组成就能够解决这种问题,因此他提供了一个简化的,或者说是退化的Builder模式实现,从而更清楚地表明自己的想法。反过来,如果各个产品的创建步骤相同,我们仍然可以很容易地抽象出一个基类Builder,并为公有的创建步骤添加相应的Director。
Fluent Interface
但是Joshua给出的Builder模式中,另一处实现引起了我的注意。在Builder类中,他使用了Fluent Interface模式:
// Java代码 public Builder sodium(int val) { sodium = val; return this; }
这是在Martin Fowler的一篇文章中所列出的一种模式。该模式的最大优点就是大大地提高了代码的可读性。在一个标准的Fluent Interface模式实现的帮助下,软件开发人员可以编写出非常易懂的代码。但是从Joshua给出的示例来看,似乎这种可读性的提高并不明显:
// Java代码 NutritionFacts cocaCola = new NutritionFacts.Builder(240, 8) .calories(100).sodium(35).carbohydrate(27).build();
当其它软件开发人员遇到该段代码的时候,他立刻理解函数调用calories(),sodium(),carbohydrate()等函数的意义么?
“如果是我,我会使用一个’with-’前缀吧”,我想到:
// Java代码 NutritionFacts cocaCola = new NutritionFacts.Builder(240, 8) .withCalories(100).withSodium(35).withCarbohydrate(27).build();
这样这些函数中所使用的小小的前缀“with-”就能让其他软件开发人员在阅读食品的营养成分时在脑中所形成相应的语义:这份营养成分表中有100卡路里,35毫克钠,以及27克碳水化合物。
当然,这只是一部分人在使用Fluent Interface模式时一种常用的命名规范。由于我们在日常生活中所使用的语言则不仅仅有“XX包含什么”这种表述,更需要表达“在什么情况下”,“什么时候”等一系列条件。因此像“where-”,“when-”等前缀也是常常用到的。
当然,计算机语言和自然语言之间还是有一定的差距的。确切来说,是很大的差距。这种差距的根源主要是由于我们每天所说的语言很多时候都没有编程语言那么严谨。因此在实现Fluent Interface模式的时候,要尽量平衡使用Fluent Interface模式组织代码所带来的额外负担以及从Fluent Interface模式所带来的可读性以及可维护性的提高。
“拿使用Fluent Interface模式后有没有什么损失呢?”我躺在床上自己问自己。由于Fluent Interface模式是使用在各个Builder之上的,因此首先我就开始思考它的扩展性是否会受到影响。
虽然说Fluent Interface模式并不要求返回的都是当前实例,但是在Builder模式中,Fluent Interface中的各个接口所返回的常常是Builder类实例自身:
// Java代码 public Builder withSodium(int val) { sodium = val; return this; }
这显示了Fluent Interface模式的另一个问题,那就是对派生并不友好。从上面的代码可以看到,该函数所返回的是一个Builder类实例。如果我们希望从Builder类派生,那么对Builder类实例所提供的函数的调用就需要放到最后:
// Java代码 AllNutritionFacts.Builder(240, 8).withTotalEnergy(1400) .withNote(“饮料内若有部分沉淀为果肉,并不影响饮用”) .withCalories(100).withSodium(35).withCarbohydrate(27).build();
这似乎就不太合常理了:由NutritionFacts.Builder类所提供的最主要营养成分竟然被放到了最后。这实际上并没有提高什么可读性,反而会使得其它软件开发人员看到这段代码时感到困惑。
当然,我们还可以尝试利用C++中有关虚函数的一个特殊性质:如果一个派生类中重写了基类中的虚函数,那么该虚函数的返回值可以适当发生改变。例如在基类中的虚函数返回基类指针或引用的时候,派生类中的相应的虚函数可以返回派生类的指针或引用。
class Base { public: // 基类中定义一个虚函数,返回类型是Base类的引用 virtual Base& self() { return *this; } }; class Derive : public Base { public: // 派生类中重写虚函数,返回类型是Derive类的引用 virtual Derive& self() { return *this; } };
这样,我们可以通过重写基类中的虚函数,使其返回派生类实例来部分解决Fluent Interface模式对派生不友好的情况。这种技术也被称为Covariant Return Type。
另一种解决方案就是尽量使用组合,而不是派生。也就是说,如果Builder模式中的产品类可以由组合来完成,而不是派生,那么它就可以通过各个组成的Builder 来完成对各个组成的生产,再通过自身的Builder来产生最后的产品:
// Java代码 Benz.Builder() .withBody(BenzBody.Builder() .withColor() .withDoorCount() .build()) .withEngine(Engine.Builder() .withPower() .build()) .withWheel(Wheel.Builder() .withSize() .build()) .build();
这样,各个子组成通过定义自己的Builder一方面可以提高重用性,另一方面也可以通过组合的方式避免使用继承,进而在按照Fluent Interface组织接口时遇到麻烦。
同系列其它文章:http://www.cnblogs.com/loveis715/category/672735.html
转载请注明原文地址并标明转载:http://www.cnblogs.com/loveis715/p/4539505.html
商业转载请事先与我联系:[email protected]