前言
上一篇说到我们让视频中的人脸自动戴上口罩,这一篇谈一下面部遮挡的情况下,怎么把人脸还原回来。

人脸编辑对抗网络 SC-FEGAN
提到图像编辑,大家都熟悉Photoshop这款软件,近乎可以处理日常所有的照片,但是PS不是这么容易操作的,精通PS更是需要专业知识了。如何让小白完成在图像上勾勾画画就能实现图像的编辑?这个任务当然可以交给深度学习来实现了。
1. 论文简介
SC-FEGAN,它具有完全卷积网络,可以进行端到端的训练。提出的网络使用SN-patchGAN判别器来解决和改善不和谐的边缘。该系统不仅具有一般的GAN损失,而且还具有风格损失,即使在大面积缺失的情况下也可以编辑面部图像的各个部分。
总结一下SC-FEGAN的贡献:
- 使用类似于U-Net的网络体系结构,以及gated convolutional layers。对于训练和测试阶段,这种架构更容易,更快捷,与粗糙网络相比,它产生了优越而细致的结果。
- 创建了解码图,颜色图和草图的自由格式域数据,该数据可以处理不完整图像数据输入而不是刻板形式输入。
- 应用了SN-patchGAN判别器,并对模型进行了额外的风格损失。该模型适应于擦除大部分的情况,并且在管理掩模边缘时表现出稳健性。它还允许生成图像的细节,例如高质量的合成发型和耳环。

更详细内容可以阅读论文和开源代码
https://github.com/run-youngjoo/SC-FEGAN
2. 下载源码
克隆代码
git clone https://github.com/run-youngjoo/SC-FEGAN在 Google drive 下载模型,
https://drive.google.com/open?id=1VPsYuIK_DY3Gw07LEjUhg2LwbEDlFpq1放入 ckpt 目录下
mv /${HOME}/SC-FEGAN.ckpt.* /${HOME}/ckpt/
3. 修改配置文件
修改 demo.yaml 文件,设置 GPU_NUM: 0
INPUT_SIZE: 512
BATCH_SIZE: 1
GPU_NUM: 0
# directories
CKPT_DIR: './ckpt/SC-FEGAN.ckpt'Qt5 界面框架
1. 安装 Qt5
sudo apt install qt5-default qtcreator qtmultimedia5-dev libqt5serialport5-dev
pip install pyqt52. 测试窗口
import sys
from PyQt5 import QtCore, QtWidgets
from PyQt5.QtWidgets import QMainWindow, QLabel, QGridLayout, QWidget
from PyQt5.QtCore import QSize
class HelloWindow(QMainWindow):
def __init__(self):
QMainWindow.__init__(self)
self.setMinimumSize(QSize(640, 480))
self.setWindowTitle("Hello world")
centralWidget = QWidget(self)
self.setCentralWidget(centralWidget)
gridLayout = QGridLayout(self)
centralWidget.setLayout(gridLayout)
title = QLabel("Hello World from PyQt", self)
title.setAlignment(QtCore.Qt.AlignCenter)
gridLayout.addWidget(title, 0, 0)
if __name__ == "__main__":
app = QtWidgets.QApplication(sys.argv)
mainWin = HelloWindow()
mainWin.show()
sys.exit( app.exec_() )
万事俱备了。
Tensorflow
1. 模型推理(OOM)
source my_envs/tensorflow/bin/activate
cd SC-FEGAN/
python3 demo.py 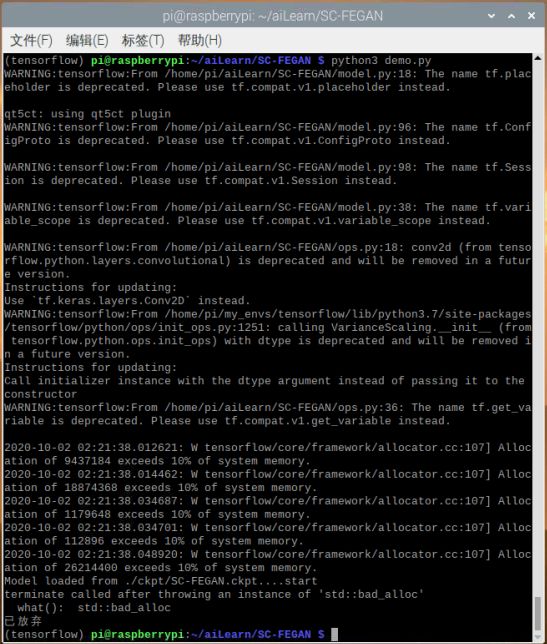
这个权重文件 353M,读入模型的时候发生了内存溢出,仔细看一下内存使用的情况,会发现虽然树莓派有8g的内存,由于我们安装的32位操作系统限制,单进程的内存使用只能到4g。
2. 树莓派32位系统与64位系统选择
这里提一下为什么不选择64位的操作系统,主要基于以下几点:
- 当前64位系统的还很不稳定,官方仍在频繁更新;
- 常用软件针对树莓派的ARM平台,大多以32位系统发布,开源的可以自行编译,商用的只能等待更新(比如 软件);
- 有些外设硬件驱动仍不支持64位(比如 usb 摄像头);
- 一般只在树莓派上做推理,而不是训练,需要超过4g内存的应用场景不多;
- 对于树莓派算力来说,用 tensorflow lite 会更适合,能显著的降低内存,加速推理。

不过随着8g版本的树莓派发布,64位系统会慢慢成熟,让子弹再飞一会儿......
官方的64位系统其实已经发布,有兴趣的朋友可以下载尝试一下,
http://downloads.raspberrypi.org/raspios_arm64/images/还可以考虑 Ubuntu 64位系统,都能充分利用到8g内存。
https://ubuntu.com/download/raspberry-pi在笔记本上实测了一下,这个模型大约需要5.5个g左右的内存就能运行,理论上在64位操作系统上,用8g版本的树莓派可以正常推理。
Tensorflow lite
1. 找到输入输出层
SC-FEGAN 输入是 5 张图片,分别是真实图片、单色线框图、彩色线框图、噪声图、掩码图,先可视化一下,要注意各张图的取值范围。
def visualImageOutput(self, real, sketch, stroke, noise, mask):
"""
:param real: 真实图片
:param sketch: 单色线框图
:param stroke: 彩色线框图
:param noise: 噪声图
:param mask: 掩码图
:return:
"""
temp = (real + 1) * 127.5
temp = np.asarray(temp[0, :, :, :], dtype=np.uint8)
cv2.imwrite('real.jpg', temp)
temp = sketch * 255
temp = np.asarray(temp[0, :, :, 0], dtype=np.uint8)
cv2.imwrite('sketch.jpg', temp)
temp = (stroke + 1) * 127.5
temp = np.asarray(temp[0, :, :, :], dtype=np.uint8)
cv2.imwrite('stroke.jpg', temp)
temp = noise * 255
temp = np.asarray(temp[0, :, :, 0], dtype=np.uint8)
cv2.imwrite('noise.jpg', temp)
temp = mask * 255
temp = np.asarray(temp[0, :, :, 0], dtype=np.uint8)
cv2.imwrite('mask.jpg', temp)输出是一张 GAN 生成的图片,对应输出层是 Tanh。
# Name of the node 0 - real_images
# Name of the node 1 - sketches
# Name of the node 2 - color
# Name of the node 3 - masks
# Name of the node 4 - noises
# Name of the node 1003 - generator/Tanh记住这些网络层的序号和名称,方便后续取用。
2. ckpt 转换为 pb
其中 add 为自定义输出层的别名,保存的 save_model.pb 就是所需的序列化静态网络图文件。
from tensorflow.python.framework import graph_util
constant_graph = graph_util.convert_variables_to_constants(self.sess, self.sess.graph_def,['add'])
# 写入序列化的 PB 文件
with tf.gfile.FastGFile('saved_model.pb', mode='wb') as f:
f.write(constant_graph.SerializeToString())
print('save', 'saved_model.pb')3. pb 转换为 tflite
知道了输入输出层的名称,就能很容易的得到 model_pb.tflite 文件了。
path = 'saved_model.pb'
inputs = ['real_images', 'sketches', 'color', 'masks', 'noises'] # 模型文件的输入节点名称
outputs = ['add'] # 模型文件的输出节点名称
converter = tf.contrib.lite.TocoConverter.from_frozen_graph(path, inputs, outputs)
# converter.post_training_quantize = True
tflite_model = converter.convert()
open("model_pb.tflite", "wb").write(tflite_model)
print('tflite convert done.')可以设置 post_training_quantize 启用压缩,模型体积将减少一半左右。
前面操作在笔记本或服务器上操作完成后,我们将 tflite 文件复制到树莓派上。

4. 激活 tensorflow lite 环境
deactivate
source ~/my_envs/tf_lite/bin/activate5. 读入模型
# Load TFLite model and allocate tensors.
model_path = "./model_pb.tflite"
self.interpreter = tflite.Interpreter(model_path=model_path)
self.interpreter.allocate_tensors()
# Get input and output tensors.
self.input_details = self.interpreter.get_input_details()
self.output_details = self.interpreter.get_output_details()6. 模型推理
要注意这里 batch 的数据结构,要匹配不同输入图片的维度尺寸来拆分 numpy 矩阵。
装填数据则按照网络定义的顺序填入 tensor。
real_images, sketches, color, masks, noises, _ = np.split(batch.astype(np.float32), [3, 4, 7, 8, 9], axis=3)
# 填装数据
interpreter.set_tensor(input_details[0]['index'], real_images)
interpreter.set_tensor(input_details[1]['index'], sketches)
interpreter.set_tensor(input_details[2]['index'], color)
interpreter.set_tensor(input_details[3]['index'], masks)
interpreter.set_tensor(input_details[4]['index'], noises)
# 调用模型
interpreter.invoke()
# 输出图片
result = interpreter.get_tensor(output_details[0]['index'])输出层将归一化数据还原成图像格式。
result = (result + 1) * 127.5
result = np.asarray(result[0, :, :, :], dtype=np.uint8)
self.output_img = result7. 程序运行
python3 demo_tflite_rpi.py 点击 Open Image 打开图片文件,然后点 Mask,涂抹掉眼镜,再点击Complete。
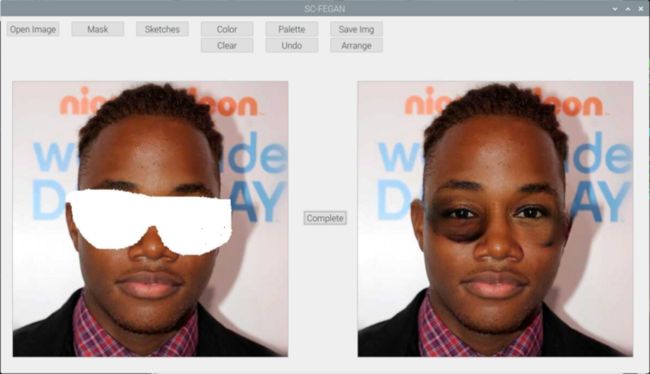

树莓派上推理用时 18 秒,效果还不错,内存只需要 1g 左右就够了。
Tip:
注意打开的图片不要包含中文路径,不然会无法获取到图片对象。
Android 应用部署
既然已经转换为 tensorflow lite了,那参照我们之前的教程,可以方便部署到手机上。
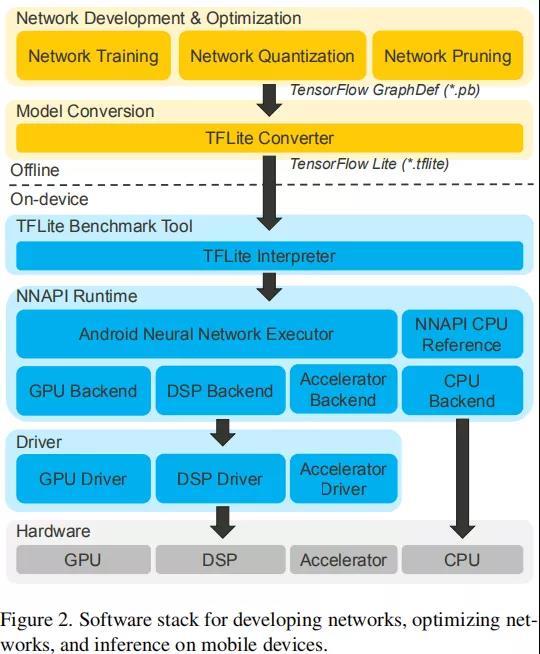
1. 配置依赖
配置好 build.gradle 的 tensorflow lite 依赖
def tfl_version = "0.0.0-nightly"
implementation("org.tensorflow:tensorflow-lite:${tfl_version}") { changing = true }
implementation("org.tensorflow:tensorflow-lite-gpu:${tfl_version}") { changing = true }2. 读入模型
modelName 配置成 model_pb.tflite,用 getInterpreter 函数来导入网络模型。
@Throws(IOException::class)
private fun getInterpreter(
context: Context,
modelName: String,
useGpu: Boolean = false
): Interpreter {
val tfliteOptions = Interpreter.Options()
tfliteOptions.setNumThreads(numberThreads)
gpuDelegate = null
if (useGpu) {
gpuDelegate = GpuDelegate()
tfliteOptions.addDelegate(gpuDelegate)
}
tfliteOptions.setNumThreads(numberThreads)
return Interpreter(loadModelFile(context, modelName), tfliteOptions)
}3. 模型推理
核心代码是定义好输入输出的图片数组
// inputRealImage 1 x 512 x 512 x 3 x 4
// inputSketches 1 x 512 x 512 x 1 x 4
// inputStroke 1 x 512 x 512 x 3 x 4
// inputMask 1 x 512 x 512 x 1 x 4
// inputNoises 1 x 512 x 512 x 1 x 4
val inputs = arrayOf(inputRealImage, inputSketches, inputStroke, inputMask, inputNoises)
val outputs = HashMap()
val outputImage =
Array(1) { Array(CONTENT_IMAGE_SIZE) { Array(
CONTENT_IMAGE_SIZE
) { FloatArray(3) } } }
outputs[0] = outputImage
Log.i(TAG, "init image"+inputRealImage)
styleTransferTime = SystemClock.uptimeMillis()
interpreterTransform.runForMultipleInputsOutputs(
inputs,
outputs
)
styleTransferTime = SystemClock.uptimeMillis() - styleTransferTime
Log.d(TAG, "Style apply Time to run: $styleTransferTime") 4. 打包APP
现在眼镜已无法遮挡你的美丽了。
完美!
好了,从自动戴上口罩到自动卸下面罩,这种左右互搏的AI应用不光有趣,还能互为数据增强,提高彼此的模型效果。
源码下载

下一篇预告
这类左右互搏的AI还有很多,
下一篇,
我们就介绍另一对应用,
周伯通的神技一起学起来吧!
敬请期待...