复旦大学汪励颢:基于对抗样本的语法纠错研究
⬆⬆⬆ 点击蓝字
关注我们
AI TIME欢迎每一位AI爱好者的加入!
语法纠错任务,即Grammatical Error Correction(简称,GEC)被广泛地应用于文本编辑、搜索、抽取中,但语法纠错任务仍然面临样本不足,模型易受攻击等问题。讲者将从文本对抗攻击角度出发,提出了一种适用于GEC任务的对抗攻击算法,以产生高质量的对抗样本来进行数据增强。实验证明了,生成的对抗样本,既能增强模型的泛化性,也能增强模型的鲁棒性。
本期AI TIME PhD直播间,我们有幸邀请到复旦大学研究生汪励颢为我们进行分享,本次分享的主题是——基于对抗样本的语法纠错研究。

汪励颢:复旦大学自然语言处理组2019级在读研究生,导师郑骁庆副教授和黄萱菁教授,研究方向为语法纠错。

一、 使用对抗样本方式对语法纠错任务进行数据增强的原因
语法纠错任务可以改正文本中各种各样的语法错误。
通常,语法改错主要有三个级别的错误:
第一个级别:字符级别错误,主要是拼写、标点等类型的错误;
第二个级别:词级别的错误,比如词的时态语态、单复数,或者一些词的选择;
第三个级别:一般认为是词组级别或者句子级别的一些错误,包括词序、搭配不当等错误。
讲者强调,GEC任务的研究主要关注在第二和第三级别错误,也就是词级别和句子级别的错误。一种主流做法是,把它当作低资源的同语料机器翻译任务,输入是具有语法错误的句子,输出是一个没有语法错误的句子,使其通过翻译的方式完成语法纠错任务。
那么,GEC任务也同样可以使用sequence to sequence的框架进行处理。但相比单纯的机器翻译任务,GEC主要存在两点区别:
第一个区别:GEC处理的句子相比机器翻译,对句子的改动是很少的,句子中可能零星的几个地方犯有错误,修正以后,句子没有大的变化,许多词语得以保留,故一些研究引入copy机制来适配这个任务;
第二个区别:GEC任务的语料是非常稀缺的。目前官方给出的语料大约是70万个句子,这对于一些data-hungry的模型(例如transformer),是远远不够的。要提升GEC任务的性能,语料不足是一个很大的瓶颈。因此,通过数据增强的方式来提升模型性能,已经成为近年来GEC任务的不可或缺的步骤。
那么如何进行数据增强呢?没有语法错误的句子是容易获得的,关键在于如何产生有语法错误的句子。主流的两种数据增强方式:一种是direct noise,一种是back translation。
第一种direct noise的方式是通过加词、删词、改词,交换词的位置来在句子中引入一些噪声,但这样产生的错误与人类所犯的语法错误是非常不一样的,如图1的表1所示,direct noise生成的句子有很大噪声,但并不含有有价值的语法错误;
第二种是用back translation的方式,仍然使用原数据集,训练的模型输入的是没有语法错误的句子,让其输出有语法错误的句子。但是back translation这种数据增强方式有两个问题:第一个问题是,该方法生成的错误大部分集中在一些冠词错误,一些名词,动词的错误却很少;第二个问题,这样的模型只会产生语料集的错误,而不会产生其他的扩展错误,这大大地限制了错误的种类。

此外,语法纠错模型仍然是非常脆弱的,依然有许多错误是改不出来的。讲者以一个良好性能的语法纠错系统举例,起初原句的大概为0.592;当对原句中的每一句子注入一个错误,试图去改正,性能就会降到0.434左右;当对原句中每句增加三个错误,性能会大概降到仅0.317左右,这说明语法纠错模型对新加入错误的防御是非常脆弱的。
由此启发,讲者提出了用对抗样本的方式来对GEC这个任务进行数据增强。意义在于:首先,对抗样本是更加具有价值的,对于语法纠错任务是更加有帮助的。其次,对抗样本,通过加入对抗训练的方式,能增强模型的鲁棒性。大致上对抗样本的生成方法主要包括两步:第一步是找到一个易被攻击的token;第二个是通过换词方式来产生对抗样本。

二、生成对抗样本的方法
对于GEC任务来说,它的对抗样本是具有语法错误但模型不能正确改正的句子。我们希望从没有语法错误的句子中产生对抗样本,首先需要定位攻击点。
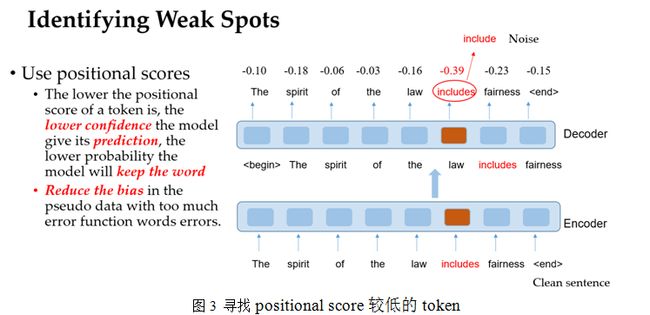
将clean的句子输入到语法改错模型中,采用positional score(logit)的方式去定位一个易被攻击的token。若得分较低,模型对其预测的confidence是较低,那么模型会以更低的概率来维持这个词。
以例子来看,如图3,在clean句子中的“includes”,吐出概率是较低,即这个模型在扰动过程中,更难保持住“includes”,若将其替换成“include”,则很有可能成为一个对抗样本。由于功能词的positional score往往是比较高的,名词、动词等实义词的positional score是比较低的,这减少了原来这些数据增强方法过多产生功能词错误的数据偏差。
定位到了易被攻击词语应该被替换成什么词?与其他NLP对抗攻击任务的近义词替换策略不同的,GEC的对抗样本需要产生语法错误,而大部分情况下近义词替换并不能产生语法错误。第一种方法是看看训练集是如何进行替换的。通过训练集提取句子中的错误及其改正词,从而构造correction-to-error的映射。一个词可以有多个错误的选择,通过比较训练集中的句子的上下文与需要生成错误的句子的上下文相似度作为采样的权重,得到一个可能的error。

但如果在训练集中找不到这样的映射,应该如何实现替换?功能词在训练集中都出现过,可以被映射替换所覆盖,但一些稀有词,可能在训练中根本没有出现过,这就需要通过预先定义一些rule-based的方法对不同词性的词语替换成它的语法错误形式(见图5 表2)。例如,对名词进行单复数互相转换,对动词进行时态、语态以及第三人称单数等各种形式的转化;对形容词副词,可进行相互转换;对于标点符号,可以删除;对于其他错误,可以替换成unknown标志或者删除。

整个对抗样本生成的算法如图5右栏所示。首先通过positional score,找到需要攻击的词。然后若能在训练集中找到词语替换映射,则采样出错误;若找不到,通过rule-based的方法进行转换。最后把改过的相关句子,放到原来的GEC 模型中验证是否能被改正,如果无法改正,则认为该对抗样本就生成成功了。
生成对抗样本之后,就可以把这些样本加入到训练集进行对抗训练,而讲者使用对抗样本进行预训练。总的步骤是,第一步训练一个基本模型,第二步攻击该模型产生对抗样本,第三步使用对抗样本进行预训练,第四步在原训练集上精调模型。如果想要继续提升模型的鲁棒性,可以继续攻击模型,并将对抗样本加入到训练集中训练。

三、实验验证
实验结果如表1所示,首先表上半部分是和其他数据增强模型的对比。这些模型都是用transformer模型作为seq2seq框架的组件,且都在增强数据集上进行预训练,在原数据集上进行精调。实验表明:ADV模型和direct noise和back translation相比,性能有明显提升;对ADV模型的消融实验也可以看出,不同的组件对模型的性能都是有帮助的。
表的下半部分是和其他语法纠错模型进行对比的结果,这些对比模型不仅仅进行了数据增强,还在模型的结构上做了一些新的改进。实验结果表明:讲者提出的模型Grunkdiewicz、Lichtarge的模型性能表现相当,但是这些模型的预训练数据量大概是在千万级别,然而ADV模型是120万级别的数据,这说明讲者所提出模型的数据性能,数据效率是比其他模型高很多。进一步,讲者解释到,这些模型的性能提升主要靠预训练语言模型,是大语料上在学语言模型的知识,而非针对语法错误进行修改。

除了模型性能之外,还设计关于模型鲁棒性的实验。在测试集的句子中,通过攻击算法新引入一个错误或者三个错误的攻击,实验结果表明:所提模型性能下降的偏少,对新加入错误的改正率较其他模型有很大提升。同时,如果不断进行模型对抗训练,模型在性能上会有一定牺牲,但其鲁棒性会不断提升。

通过对抗训练之后的模型,对于名词、动词、形容词和副词这些实义词,在新加入错误的改正率提升是很大的。若没有这样的一个对抗预训练,形容词与副词上的改正几乎是不可能的。而现有的GEC模型对于介词错误改正上,仍然是一个可探索的点。

负采样
总结
讲者设计了一种对抗攻击的算法,通过引入大量的语法错误来产生高质量的对抗样本,并将这些对抗样本来预训练语法纠错模型,既提升模型的泛化性也提升了鲁棒性。

论文数据及代码:
https://github.com/zhijing-jin/ARTS_TestSet
论文链接:
https://www.aclweb.org/anthology/2020.emnlp-main.228.pdf
负采样
整理:刘美珍
排版:岳白雪
审稿:汪励颢
本周直播预告:


AI TIME欢迎AI领域学者投稿,期待大家剖析学科历史发展和前沿技术。针对热门话题,我们将邀请专家一起论道。同时,我们也长期招募优质的撰稿人,顶级的平台需要顶级的你,请将简历等信息发至[email protected]!
微信联系:AITIME_HY

AI TIME是清华大学计算机系一群关注人工智能发展,并有思想情怀的青年学者们创办的圈子,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法、场景、应用的本质问题进行探索,加强思想碰撞,打造一个知识分享的聚集地。

更多资讯请扫码关注
(直播回放:https://b23.tv/AQ9ZwP)
(点击“阅读原文”下载本次报告ppt)