【社区分享】玩转社区开源贡献,看这篇就够了!
如何成为 TensorFlow 中文社区的 Contributor?蚂蚁集团技术专家唐源围绕4个方面,教你如何玩转 TensorFlow 社区开源贡献。
本文来自社区投稿与征集。作者唐源,现任蚂蚁集团技术专家,目前专注于建立 AI 基础架构和自动机器学习平台。
本文转自:https://zhuanlan.zhihu.com/p/165098355
作为最早一批非谷歌的 TensorFlow 社区贡献者,同时也是 TensorFlow committer 和 SIG IO maintainer,我将在这篇文章里分享一下自己贡献 TensorFlow 的经历以及一些收获,希望能对大家有启发,鼓励大家一起参与进来。大家如果感兴趣可以去我的 GitHub 查找相关的贡献,以及关注我的 Twitter 来得到第一时间的更新。
参与 TensorFlow 社区进行贡献有多种形式,这里我主要围绕 4 个方面来谈谈我对 TensorFlow 社区的贡献:
-
贡献 TensorFlow 高阶 API 代码
-
积极参与 TensorFlow 社区的管理
-
贡献 TensorFlow 延伸出来的开源项目
-
传播知识和分享经验
从用户到贡献者
TensorFlow 是在 2015 年年底开源在 GitHub 上的。在这之前我一直在参与贡献 Apache MXNet 的 Scala API,在深度学习系统的设计方面也有了一定经验的积累。那个时候我的日常工作主要是使用 R 和 Python 来实现各种算法,所以 TensorFlow 这种一开始就比较注重 Python 的框架一下子就吸引到了我们团队的注意力,我也开始利用业余时间尝试使用 TensorFlow 搭建一些简单的神经网络以及传统的机器学习算法。
当时在早期的 TensorFlow 版本中都是需要对低阶的 API 有深度的理解才能实现这些。数据科学从事者没有必要为了使用最新的算法和技术花许多时间来学习这些实现的细节,通过这一套高阶的 API,他们可以很快地直接将这些使用在工作和研究中。当时作为数据科学从事者的一员,我看到了这一块的需求,即使自己比较熟悉 TensorFlow 也仍然感到实现算法特别繁琐。
不久后,tensorflow/skflow (Scikit Flow) 开源了,这是当时谷歌工程师 Illia Polosukhin 最早在谷歌内部创立的项目,这个项目的目的是降低大家使用分布式机器学习和深度学习的门槛,让大家可以像使用 Scikit-learn 那样快速地搭建自己的机器学习和深度学习模型,用仅仅几行代码就能使用 TensorFlow 实现的深度学习算法,甚至是传统的机器学习算法,比如逻辑回归、随机森林等等。我也作为种子用户开始试用,发现很多的功能还不成熟,也缺少很多实用的 API,于是我在项目很早期的时候就开始参与贡献,主要设计和贡献了许多新的 API 来提升用户体验。
获得支持和认可
当然,TensorFlow 团队也逐渐意识到了高阶 API 对社区用户的重要性。在他们的支持下,我们把 Scikit Flow 贡献到了 tf.estimator 模块,TensorFlow 团队也开始积极地参与进来,改进了很多分布式训练的逻辑,添加了 feature_column、layers 等新的模块。为了能够更好地和 TensorFlow 生态融合,他们也在谷歌内部各个项目和场景中开始使用和落地,比如 YouTube Watch Next 的推荐系统。
关于模块的设计和一些经验的分享,可以参考我们在 2017 年 KDD 会议上发表的文章 TensorFlow Estimators: Managing Simplicity vs. Flexibility in High-Level Machine Learning Frameworks。
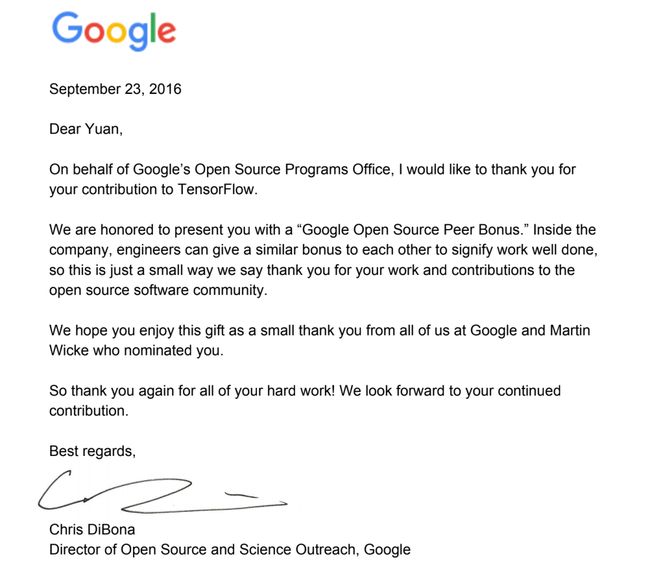
当时也因为我对 TensorFlow 的贡献,谷歌开源部门在 2016 年颁给了我 Open Source Peer Bonus。这个奖项是由内部员工提名推荐,然后再经过内部审核和讨论得到最后的获奖人名单,我通过持续对 TensorFlow 的贡献吸引到了他们的注意并得到肯定,这在当时对我来说是很大的鼓励和认可。在这里我也鼓励大家重在坚持,相信一切的付出都是值得的。
参与 TensorFlow 社区的管理
TensorFlow 社区现在也分为了很多子项目以及不同的特别兴趣小组 SIGs,比如 SIG IO 维护着 TensorFlow I/O 这个 TensorFlow 子项目,这个项目支持从各种格式以及文件系统(比如 Apache Arrow、Kafka、Alibaba OSS、等等)来读写数据,以供 TensorFlow 模型训练使用。作为 SIG IO 管理者的一员,在这里也邀请大家在使用的同时,有什么问题和想法都可以在社区通过邮件、Gitter、或者 GitHub issues 等不同的形式提出来,贡献不仅仅限于贡献代码,很多时候贡献文档、参与讨论也会给社区带来非常大的帮助。大家可以参考社区 tensorflow/community 里的一些文档了解到不同 SIG 的运作方式积极参与进来。
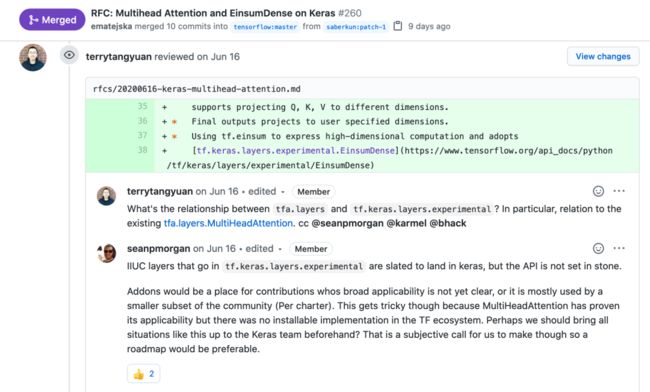
另外,社区的一些新的 API 提案也会通过 tensorflow/community 里的 Request for Comments (RFC) 的形式公开和社区讨论,举一个近期的例子,谷歌团队以 RFC 的形式提出了在 Keras 里添加 Multihead Attention 和 EinsumDense layers ,我当时看到了这个提案,第一个反应就很好奇这个和社区 SIG Addons 以及 Keras experimental 里现有的 layers 之间有什么区别和联系,于是在提案底下评论并且邀请了社区几位相关的开发者来一起讨论。
除此之外,社区的不同 SIG 也会定期举办社区会议,感兴趣的开发者可以一起加入讨论遇到的问题,这也会带来潜在的跨公司、跨社区之间的交流与合作等等。
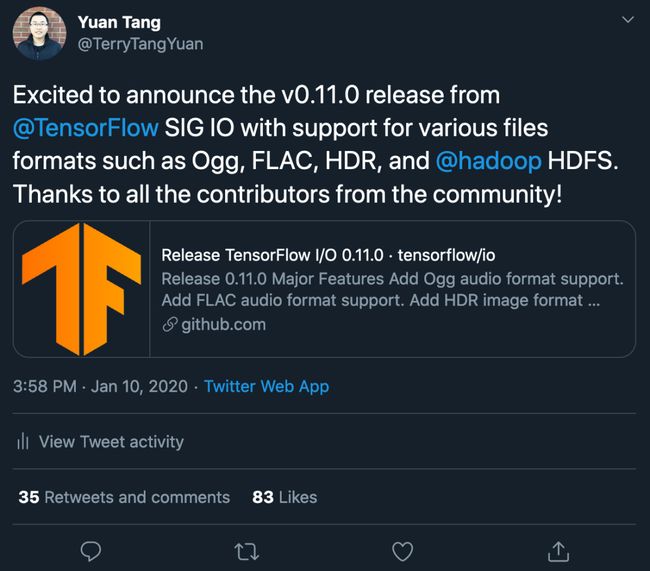
TensorFlow 在 Twitter 上也非常活跃,重要通知以及新颖与优质的案例也会在上面推广,社区的 SIG 管理者也会经常在上面宣布新的版本发布并与社区互动。下图是我们在 Twitter 上宣布 TensorFlow IO v0.11.0 版本发布的一个例子。
贡献开源社区生态
参与 TensorFlow 社区贡献,也不仅仅限于 TensorFlow GitHub 组织下的项目,在这我也简单介绍一下在加入 TensorFlow 社区之后围绕 TensorFlow 生态做的一些工作。
-
Kubeflow 支持在 Kubernetes 集群上很方便地运行各种机器学习框架,这其中也包括通过 TF Operator 执行 TensorFlow 原生分布式训练、通过 MPI Operator 执行 Horovod 支持的 TensorFlow 分布式训练。
-
ElasticDL 支持在 Kubernetes 集群上运行 TensorFlow,并且支持容错和弹性调度,提升集群利用率。
-
和 RStudio 合作的 TensorFlow in R,提供了非常友好的 API 让用户能够使用 R 语言来调用 TensorFlow,支持包括所有的低阶 API,也包括 tf.keras、tf.data、tf.estimator 等等。
技术推广和知识传播
由于当时 TensorFlow 刚开源不久,官方文档以及用例还不完善,一些网上的学习资源也都是以英文为主。与国外相比,国内学习条件乃至中文版的学习课程与资源、专业图书、都非常匮乏。
为了帮助更多国内的爱好者学习,让 TensorFlow 能在国内更好地推广,我写了当时第一本 TensorFlow 中文教材《TensorFlow实战》,在当时也很荣幸地获得了 Jeff Dean 以及 TensorFlow 团队的推荐,更多的背景可以参考 CSDN 的专访。

最近我也参与了《动手学深度学习》英文版 的 TensorFlow 实现,这是一本结合算法、图示和代码的深度学习教材,每个章节就是一个可执行的 Jupyter Notebook,可在本地执行或者 Google Colab 等云上环境运行。目前已经有至少 85 所大学使用它作为教材,包括斯坦福、伯克利、清华、北大、浙大、等等。项目开源在 d2l-ai/d2l-en,在这里我也鼓励大家一起参与进来,让有用的知识和技术能够得到更好更快地传播。
写在最后
从个人的角度来说,参与开源能够塑造个人品牌、认识各地的开发者、促进世界范围内的合作、提升个人技术、思考,以及交流能力等等。
从公司的角度来说,参与开源能够提升社区影响力、引导社区发展、提升团队整体能力、避免重造轮子、复用现有技术,以及鼓励创新等等。
我从参与开源软件这个过程中获得了许多帮助,学到了很多,认识了许多志同道合的人,我也希望通过我的贡献来报答社区对我的帮助。我相信付出越多,获得的回报也越多。
关于作者
唐源,现任蚂蚁集团技术专家,目前专注于建立 AI 基础架构和自动机器学习平台。一直积极参与开源软件的开发,是多个开源软件的作者,XGBoost 和 Apache MXNet 的 PMC 成员, 同时也是 TensorFlow、Kubeflow、以及 ElasticDL 的 Committer,著有《TensorFlow实战》。
想了解更多大神的经验分享?扫码关注 TensorFlow 官方微信公众号( TensorFlow_official ),产品更新、课程教学、技术实践、应用实例等精彩内容一网打尽!
