R语言用逻辑回归、决策树和随机森林对信贷数据集进行分类预测
原文链接:http://tecdat.cn/?p=17950
在本文中,我们使用了逻辑回归、决策树和随机森林模型来对信用数据集进行分类预测并比较了它们的性能。数据集是
credit=read.csv("german_credit.csv", header = TRUE, sep = ",")看起来所有变量都是数字变量,但实际上,大多数都是因子变量,
> str(credit)
'data.frame': 1000 obs. of 21 variables:
$ Creditability : int 1 1 1 1 1 1 1 1 1 1 ...
$ Account.Balance : int 1 1 2 1 1 1 1 1 4 2 ...
$ Duration : int 18 9 12 12 12 10 8 ...
$ Purpose : int 2 0 9 0 0 0 0 0 3 3 ...让我们将分类变量转换为因子变量,
> F=c(1,2,4,5,7,8,9,10,11,12,13,15,16,17,18,19,20)
> for(i in F) credit[,i]=as.factor(credit[,i])现在让我们创建比例为1:2 的训练和测试数据集
> i_test=sample(1:nrow(credit),size=333)
> i_calibration=(1:nrow(credit))[-i_test]我们可以拟合的第一个模型是对选定协变量的逻辑回归
> LogisticModel <- glm(Creditability ~ Account.Balance + Payment.Status.of.Previous.Credit + Purpose +
Length.of.current.employment +
Sex...Marital.Status, family=binomia基于该模型,可以绘制ROC曲线并计算AUC(在新的验证数据集上)
> AUCLog1=performance(pred, measure = "auc")@y.values[[1]]
> cat("AUC: ",AUCLog1,"\n")
AUC: 0.7340997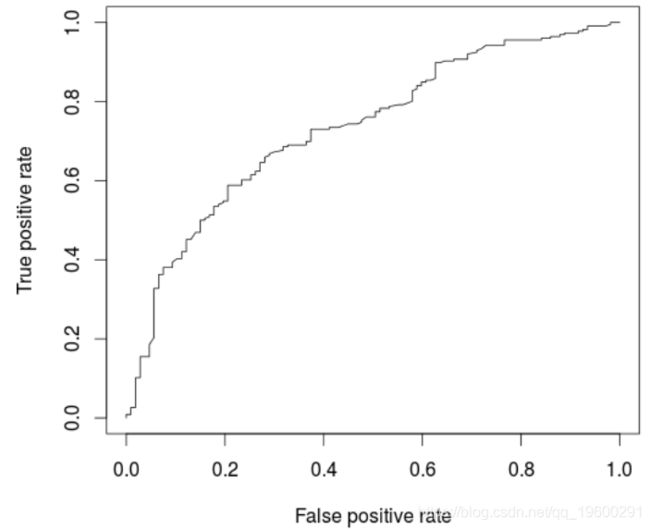
一种替代方法是考虑所有解释变量的逻辑回归
glm(Creditability ~ .,
+ family=binomial,
+ data = credit[i_calibrat我们可能在这里过拟合,可以在ROC曲线上观察到
> perf <- performance(pred, "tpr", "fpr
> AUCLog2=performance(pred, measure = "auc")@y.values[[1]]
> cat("AUC: ",AUCLog2,"\n")
AUC: 0.7609792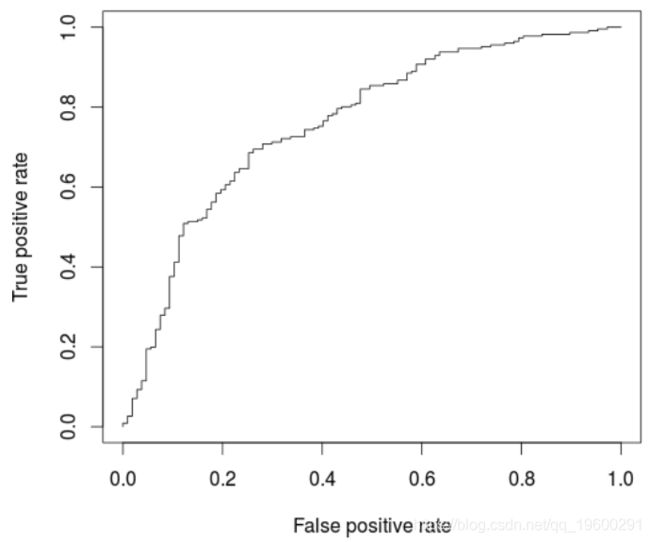
与以前的模型相比,此处略有改善,后者仅考虑了五个解释变量。
现在考虑回归树模型(在所有协变量上)
我们可以使用
> prp(ArbreModel,type=2,extra=1)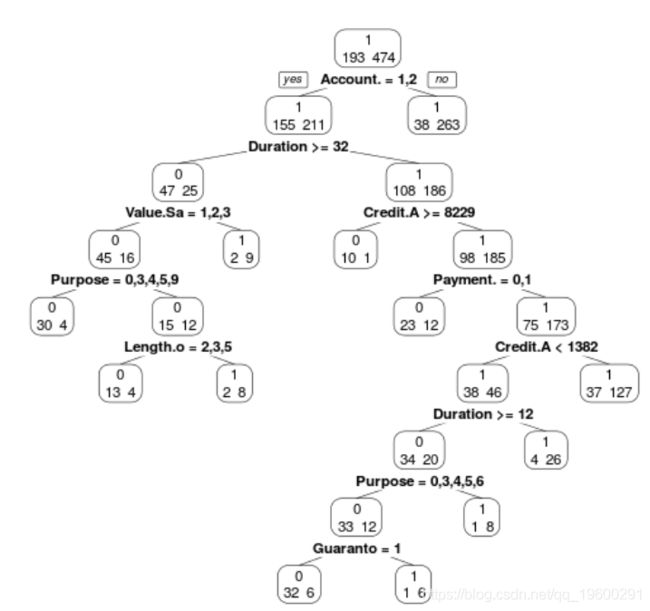
模型的ROC曲线为
(pred, "tpr", "fpr")
> plot(perf)
> cat("AUC: ",AUCArbre,"\n")
AUC: 0.7100323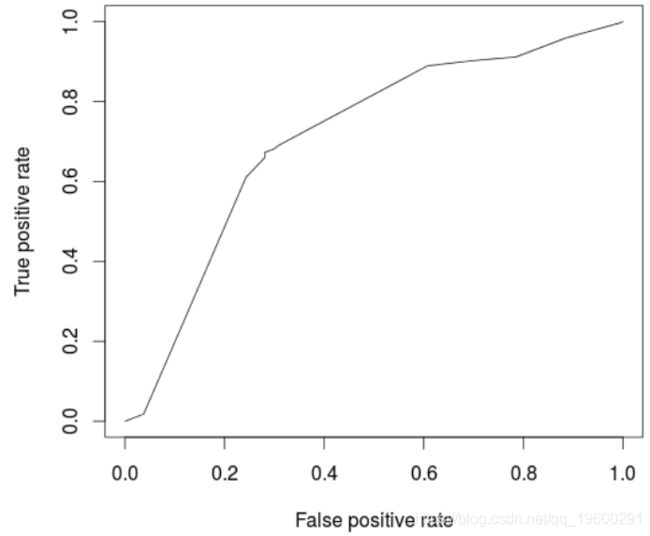
不出所料,与逻辑回归相比,模型性能较低。一个自然的想法是使用随机森林优化。
> library(randomForest)
> RF <- randomForest(Creditability ~ .,
+ data = credit[i_calibration,])
> fitForet <- predict(RF,
> cat("AUC: ",AUCRF,"\n")
AUC: 0.7682367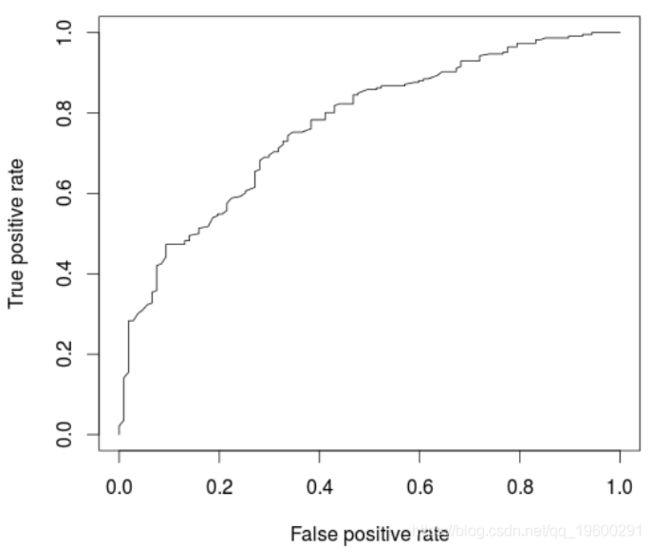
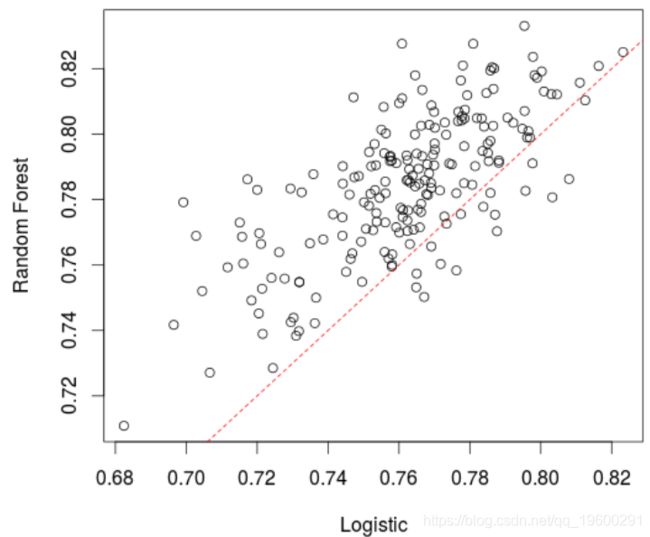
在这里,该模型(略)优于逻辑回归。实际上,如果我们创建很多训练/验证样本并比较AUC,平均而言,随机森林的表现要比逻辑回归好,
> AUCfun=function(i){
+ set.seed(i)
+ i_test=sample(1:nrow(credit),size=333)
+ i_calibration=(1:nrow(credit))[-i_test]
+ summary(LogisticModel)
+ fitLog <- predict(LogisticModel,type="response",
+ newdata=credit[i_test,])
+ library(ROCR)
+ pred = prediction( fitLog, credit$Creditability[i_test])
+ RF <- randomForest(Creditability ~ .,
+ data = credit[i_calibration,])
+ pred = prediction( fitForet, credit$Creditability[i_test])
+ return(c(AUCLog2,AUCRF))
+ }
> plot(t(A))

最受欢迎的见解
1.从决策树模型看员工为什么离职
2.R语言基于树的方法:决策树,随机森林
3.python中使用scikit-learn和pandas决策树
4.机器学习:在SAS中运行随机森林数据分析报告
5.R语言用随机森林和文本挖掘提高航空公司客户满意度
6.机器学习助推快时尚精准销售时间序列
7.用机器学习识别不断变化的股市状况——隐马尔可夫模型的应用
8.python机器学习:推荐系统实现(以矩阵分解来协同过滤)
9.python中用pytorch机器学习分类预测银行客户流失