⭐ 李宏毅2020机器学习课程笔记(一)
文章目录
- 1. 课程简介
-
- Course Introduction(P1)
- Rule of ML 2020(P2)
- 2. Regression
-
- Case Study (P3)
- Basic concept(P4)
- Gradient Descent(P5、P6、P7)
- Optimization for Deep Learning(P8、P9)
- Classification(P10)
- Logistic Regression(P11)
- 3. Deep Learning
-
- Brief Introduction of Deep Learning(P12)
- Backpropagation(P13)
- Tips for Training DNN(P14)
- Why Deep-(P15)
- PyTorch Tutorial(P16)
1. 课程简介
Course Introduction(P1)
2020版课程介绍,李宏毅老师详细解释本课程的学习路线
2020版少了一个机器学习的整体介绍,建议点击2019年视频补充,关于监督学习、半监督学习、无监督学习、迁移学习、强化学习的简介。
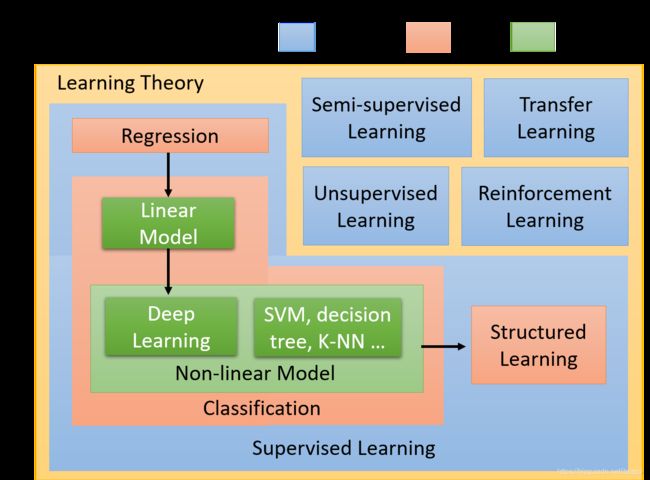
机器学习中所谓的模型其实是指一个函数。
Rule of ML 2020(P2)
助教介绍pyenv的安装和使用、kaggle,学生如何利用github完成作业,评分以及助教的联系方式。
2. Regression
Case Study (P3)
机器学习入门——回归,预测准确的数值。
非常有趣的一课,以“预测宝可梦的CP值”作引,李宏毅老师介绍了回归(同时,也是机器学习)的整体过程。
整体过程(后面会反复用到,博主称它叫机器学习三步骤吧):
- 定义模型集合/函数集合。
- 定义损失函数(LOSS)来评价模型/函数好坏。
- 选择最好的模型/函数。
这里的模型实际上就是函数 y = f ( x ) y=f(x) y=f(x),后面可能会直接简称模型。
简述梯度下降(Gradient Descent ):
- 单个参数的梯度下降。
- 两个参数的梯度下降。
回归问题的损失函数是凸函数(convex),意味着一定会找到全局最优解。但是,其它的机器学习问题中,多个参数的梯度下降可能会陷入局部最优解。
过拟合、欠拟合的问题及解决方法。
过拟合时,一个方法是使用正则化。
正则化的作用是降低模型的泛化误差。
选择模型时,更倾向于选择“平滑”的模型。因为当数据有噪声干扰时,越平滑的函数受到噪声的干扰越小。
回归问题的机器学习三步骤:
- 定义模型集合:
f = w ⋅ x + b = ∑ i w i x i + b f=\boldsymbol w \cdot \boldsymbol x+\boldsymbol b=\sum_{i} w_{i} x_{i}+\boldsymbol b f=w⋅x+b=i∑wixi+b- 定义损失函数(LOSS)来评价模型好坏:
L ( f ) = L ( w , b ) = 1 2 ∑ n ( f ( x n ) − y ^ n ) 2 = 1 2 ∑ n ( w ⋅ x n + b − y ^ n ) 2 \begin{aligned} L(f)&=L(w,b)\\ &=\frac{1}{2} \sum_{n}\left(f\left(x^{n}\right)-\hat{y}^{n}\right)^{2}\\ &=\frac{1}{2} \sum_{n}\left( w \cdot x^n+b-\hat{y}^{n}\right)^{2} \end{aligned} L(f)=L(w,b)=21n∑(f(xn)−y^n)2=21n∑(w⋅xn+b−y^n)2- 选择最好的模型:
梯度下降法
w ∗ , b ∗ = arg min w , b L ( w , b ) w^{*}, b^{*}=\arg \min\limits_{w, b} L(w, b) w∗,b∗=argw,bminL(w,b)
梯度
∇ L = [ ∂ L ∂ w ∂ L ∂ b ] g r a d i e n t = [ − 2 ∑ i = 1 n ( y ^ n − ( b + w ⋅ x n ) ) 2 x i n − 2 ∑ i = 1 n ( y ^ n − ( b + w ⋅ x n ) ) 2 ] \nabla L=\left[\begin{array}{l}\frac{\partial L}{\partial w} \\ \frac{\partial L}{\partial b}\end{array}\right]_{g r a d i e n t} =\left[\begin{array}{l} -2\sum\limits_{i=1}^n{\left(\hat{y}^{n}-\left(b+w \cdot x_{}^{n}\right)\right)}^2x_i^n\\ -2\sum\limits_{i=1}^n{\left(\hat{y}^{n}-\left(b+w \cdot x_{}^{n}\right)\right)}^2 \end{array}\right] ∇L=[∂w∂L∂b∂L]gradient=⎣⎢⎡−2i=1∑n(y^n−(b+w⋅xn))2xin−2i=1∑n(y^n−(b+w⋅xn))2⎦⎥⎤
其中, x i n x_i^n xin表示向量 x n = [ x 1 n , x 2 n , . . . , x i n , . . . ] x^n=[x^n_1,x^n_2,...,x^n_i,...] xn=[x1n,x2n,...,xin,...]中第i维的值。
Basic concept(P4)
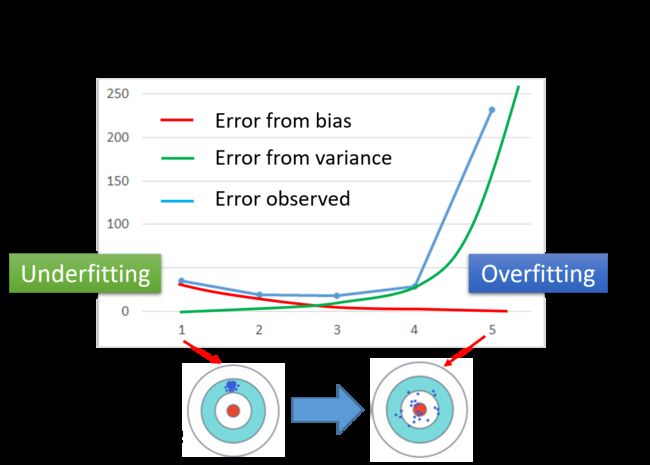
理论解释“误差来自哪里?”——偏差(bias)和方差(variance)
回归中,复杂的模型包含简单的模型(令高次项系数为0)。模型在拟合数据时,越简单的模型,受到特殊的取样数据点的影响越小,所以方差越小。
一般来说,
- 简单的模型(左侧)有大的bias和小的variance
- 复杂的模型(右侧)有小的bias和大的variance【瞄得越来越准,但误差越来越大】

欠拟合(underfitting):误差来源于bias——模型不能很好地拟合训练数据。
- 解决方法:重新设计模型(欠拟合时,采集更多数据是没用的)
- 增加更多的特征作为输入
- 选择更复杂的模型
过拟合(overfitting):误差来源于variance——模型拟合了训练数据,但在测试数据上有很大误差。
- 解决方法:
- 更多数据——采集or生成
- 正则化
理想结果:平衡bias和variance,得到一个较好的模型。
训练集、验证集、测试集的划分,交叉验证(cross validation)和k折(k-fold)交叉验证。
注1:将训练数据分为测试集和验证集。做实验、发表论文时所谓的测试集,实际上是一个public testing set,而真正的测试集是一个private testing set,是一个谁也不知道的东西(我们不知道后人会输入什么数据到模型中),因此,我们不应该以public testing set作为选择模型的标准,而是应该以validation的结果来选择最好的模型。
注2:用validation选好模型后,可以把测试集和验证集一起作为训练数据,再对模型进行一次训练。但是!千万不要在看到public testing set的结果后,再想着去调整训练好的模型,这样的调整是无意义的。
以上红色标注的点,博主以前都搞错了,一直以为是直接把数据集分成training、testing、validation,而validation=testing,因此,博主以前都是直接在testing上做测试,根据测试结果调整超参数,不用validation。现在看来这一做法不妥。最近翻阅花书(《深度学习》),书上面也是李宏毅老师的这一说法。

Gradient Descent(P5、P6、P7)
这里有三个视频,不过实际上P6和P7都只有几分钟,是李宏毅老师用游戏来解释梯度下降法。
P5讲了梯度下降法的三个tips:
Tips1:自动调整学习率η
Adagrad这一自动梯度下降法的具体实现过程,并且,李宏毅老师给了示例,解答了Adagrad中“梯度越大,step不一定越大”这一问题,最好的步伐是 ∣ 一 次 微 分 ∣ 二 次 微 分 \frac{|一次微分|}{二次微分} 二次微分∣一次微分∣
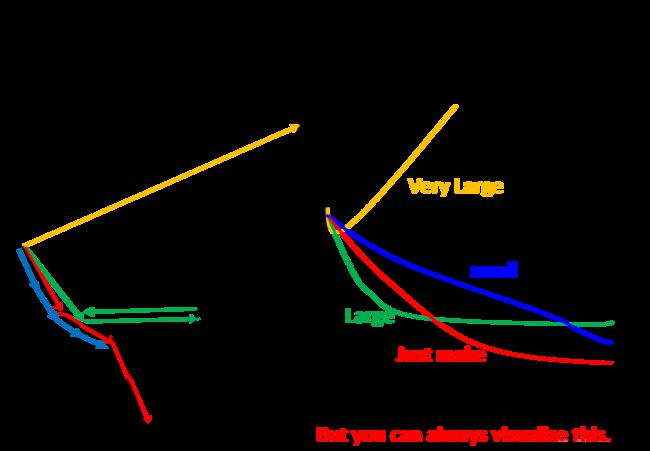
图中可视化了学习率对训练时Loss的影响。不同颜色的线代表不同的学习率,随着训练次数增加,Loss的变化趋势不同。当你在训练模型的时候,建议把这张图画出来,这样才可以判断你的学习率是否合适。
Tips2:Stochastic Gradient Descent(SGD)使训练更快
Tips3:特征放缩(Feature Scaling)归一化参数
李宏毅老师用数学公式(泰勒展开)说明了梯度下降法的工作原理,并解释了梯度下降法的局限。
我们一般认为:梯度下降法的局限是训练可能会陷入局部最优解(局部最小值,local minima),无法到达全局最小值。但是,实际情况可能更糟糕。当我们真正训练模型的时候,我们会定义一个终止值 δ \delta δ表示无穷小,在梯度接近于0( < δ <\delta <δ)的地方就会停下来,而这个地方不一定是全局最小值,它可能是局部最小值,也可能是鞍点(saddle point),甚至可能是一个损失函数很大的平缓高原(plateau)。
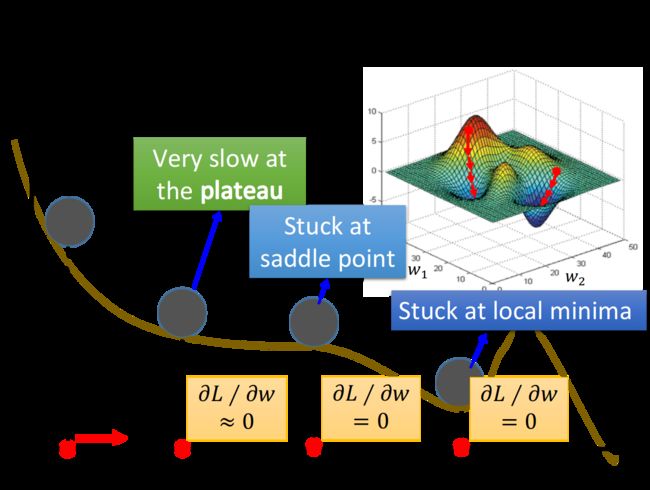
P6用世纪帝国这个游戏说明为何用梯度下降法会陷入局部最优解。
P7用Minecraft这个游戏说明为何在梯度下降法中,梯度可能会先升后降。
Optimization for Deep Learning(P8、P9)
* 2020新增内容,由助教讲授
不过……讲得不太清楚,就随缘听听吧。
Classification(P10)
机器学习的另一经典问题——分类,与回归的“预测数值”不同,分类需要“预测标签”。
首先,李宏毅老师详细解释了为何不能将分类问题直接当作回归问题(即,分类问题直接用回归的损失函数)来解。
Q:多分类问题为什么不可以直接当作回归问题?
A:类别1变成数值1,类别2变成数值2,类别3变成数值3……暗示类别1与类别2比较接近,与类别3比较远,实际上并无此关系。
当然,确实有将多分类当做回归来解的模型(感知机,SVM等),但是需要修改损失函数。
李宏毅老师用“给宝可梦分类”的例子详细推导了如何正确求解一个分类问题(涉及贝叶斯公式、高斯分布、极大似然估计等),该模型为生成模型。
Q:为什么是生成模型?
A:假设数据遵循一个均值为 μ \mu μ、协方差矩阵为 Σ \Sigma Σ的高斯分布。利用从高斯分布中生成数据的概率,即似然(likelihood),来估计 P ( x ∣ C 1 ) P(x|C_1) P(x∣C1)(从类别 C 1 C_1 C1中任取一个样本,它是x的概率)
Q:为什么要假设数据的分布是高斯分布?
A:(李宏毅:我知道,就算假设是别的分布,你也一定会问这个问题!)你可以假设任意你喜欢的分布,比如二元分类,可以假设伯努利分布。高斯分布比较简单,参数也比较少(每个类别的高斯分布都共享协方差矩阵 Σ \Sigma Σ)。
Q:为什么不同类别要共享协方差矩阵 Σ \Sigma Σ?
A:如果每个类别 i i i都有一个协方差矩阵 Σ i \Sigma_i Σi,那么一方面,variance过大,容易过拟合,另一方面,共享协方差矩阵可以减少参数个数。
总结——分类问题的三步骤:
- 定义模型集合
样本x属于类别1的概率(后验):
P ( C 1 ∣ x ) = P ( C 1 ) P ( x ∣ C 1 ) P ( C 1 ) P ( x ∣ C 1 ) + P ( C 2 ) P ( x ∣ C 2 ) P\left(C_{1} | x\right)=\frac{P\left(C_{1}\right) P\left(x | C_{1}\right)}{P\left(C_{1}\right) P\left(x | C_{1}\right)+P\left(C_{2}\right) P\left(x | C_{2}\right)} P(C1∣x)=P(C1)P(x∣C1)+P(C2)P(x∣C2)P(C1)P(x∣C1)
如果 P ( C 1 ∣ x ) > 0.5 P\left(C_{1}| x\right)>0.5 P(C1∣x)>0.5,则x属于类别1;否则,x属于类别2.- 定义损失函数(LOSS)来评价模型好坏
假设高斯分布,利用已有的数据,求得 μ \mu μ, Σ \Sigma Σ。最大化评价参数好坏的指标,即极大似然估计 L ( μ , Σ ) L(\mu,\Sigma) L(μ,Σ)。- 找到最好的模型
μ ∗ , Σ ∗ = arg max μ , Σ L ( μ , Σ ) \mu^*,\Sigma^*=\argmax\limits_{\mu,\Sigma}L(\mu,\Sigma) μ∗,Σ∗=μ,ΣargmaxL(μ,Σ)
实际上,(背公式)最佳参数就是每个类别中,所有样本点的均值和协方差。比如,类别1的最佳均值与协方差:
μ 1 ∗ = 1 n 1 ∑ i = 0 n 1 x i \mu^*_1=\frac{1}{n_1} \sum_{i=0}^{n_1} x^{i} μ1∗=n11i=0∑n1xi
Σ 1 ∗ = 1 n 1 ∑ i = 0 n 1 ( x i − μ 1 ∗ ) ( x i − μ 1 ∗ ) T \Sigma^{*}_1=\frac{1}{n_1} \sum_{i=0}^{n_1}\left(x^{i}-\mu^{*}_1\right)\left(x^{i}-\mu^{*}_1\right)^{T} Σ1∗=n11i=0∑n1(xi−μ1∗)(xi−μ1∗)T
注1:均值是每个类别单独求出的。
注2:协方差先每个类别单独求出,然后共享的协方差为所有协方差的加权平均值 Σ ∗ = n 1 N Σ 1 ∗ + n 2 N Σ 2 ∗ + . . . \Sigma^*=\frac{n_1}{N}\Sigma^{*}_1+\frac{n_2}{N}\Sigma^{*}_2+... Σ∗=Nn1Σ1∗+Nn2Σ2∗+...
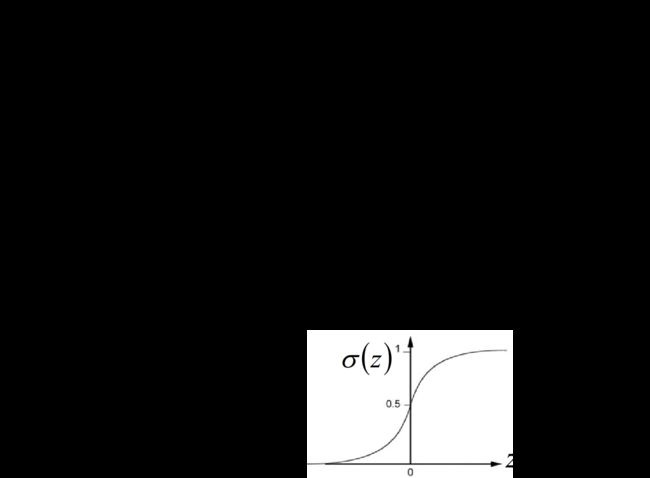
最后,李宏毅老师通过对后验概率的数学变形,推导出了sigmod函数 σ ( z ) \sigma(z) σ(z),以及实际上, z = w ⋅ x + b z=\boldsymbol w \cdot \boldsymbol x+\boldsymbol b z=w⋅x+b。在计算时,可以跳过 μ \mu μ和 Σ \Sigma Σ,直接求出 w \boldsymbol w w和 b b b,见下一章(logistic regression).

Logistic Regression(P11)
博主的一点题外话:Logistic Regression经常被翻译成逻辑回归。周志华的西瓜书《机器学习》上指出这是误译,这里的logistic和逻辑(logit)并无关系,实际上是与log相关,译成对数几率回归或者对数回归之类的会比较好一点……反正不知道怎么翻译,下文还是称呼为Logistic Regression吧。
Logistic Regression常用于解决二分类问题,由上一章,李宏毅老师引入了Logistic Regression的另一种模型表达方式,损失函数是交叉熵的形式。
总结:
- 定义模型集合
f w , b ( x ) = P w , b ( C 1 ∣ x ) = σ ( z ) = 1 1 + e − z f_{w,b}(x)=P_{w, b}\left(C_{1} | x\right)=\sigma(z)=\frac{1}{1+e^{-z}} fw,b(x)=Pw,b(C1∣x)=σ(z)=1+e−z1
z = w ⋅ x + b = ∑ i w i x i + b z=\boldsymbol w \cdot \boldsymbol x+\boldsymbol b=\sum_{i} w_{i} x_{i}+\boldsymbol b z=w⋅x+b=i∑wixi+b- 定义损失函数(LOSS)来评价模型好坏
w ∗ , b ∗ = arg max w , b L ( w , b ) = arg min w , b ( − ln L ( w , b ) ) w^{*}, b^{*}=\arg \max \limits_{w, b} L(w, b)=\arg\min \limits_{w, b}(-\ln L(w, b)) w∗,b∗=argw,bmaxL(w,b)=argw,bmin(−lnL(w,b))
通过 ln \ln ln将连乘变成连加,简化了计算机的计算,而且在计算机中,连乘后的数值容易溢出,变成连加后,数值不容易溢出。
− ln L ( w , b ) = ∑ n − [ y ^ n ln f w , b ( x n ) + ( 1 − y ^ n ) ln ( 1 − f w , b ( x n ) ) ] -\ln L(w, b)=\sum_{n}-\left[\hat{y}^{n} \ln f_{w, b}\left(x^{n}\right)+\left(1-\hat{y}^{n}\right) \ln \left(1-f_{w, b}\left(x^{n}\right)\right)\right] −lnL(w,b)=n∑−[y^nlnfw,b(xn)+(1−y^n)ln(1−fw,b(xn))]
C ( f ( x n ) , y ^ n ) = − y ^ n ln f w , b ( x n ) − ( 1 − y ^ n ) ln ( 1 − f w , b ( x n ) ) C(f(x^n),\hat{y}^{n})=-\hat{y}^{n} \ln f_{w, b}\left(x^{n}\right)-\left(1-\hat{y}^{n}\right) \ln \left(1-f_{w, b}\left(x^{n}\right)\right) C(f(xn),y^n)=−y^nlnfw,b(xn)−(1−y^n)ln(1−fw,b(xn))
是两个伯努利分布的交叉熵。
一个代表真值的分布,一个代表预测值的分布。
补充阅读:一文搞懂交叉熵在机器学习中的使用,透彻理解交叉熵背后的直觉- 找到最佳模型
梯度下降法,参数更新为: w i = w i − η ∑ n − ( y ^ n − f w , b ( x n ) ) x i n w_{i}=w_{i}-\eta \sum_{n}-\left(\hat{y}^{n}-f_{w, b}\left(x^{n}\right)\right) x_{i}^{n} wi=wi−ηn∑−(y^n−fw,b(xn))xin
公式记忆之sigmoid的微分值: ∂ σ ( z ) ∂ z = σ ( z ) ( 1 − σ ( z ) ) \frac{\partial \sigma(z)}{\partial z}=\sigma(z)(1-\sigma(z)) ∂z∂σ(z)=σ(z)(1−σ(z))
然后,李宏毅老师用表格归纳了Logistic Regression和线性回归的异同。

Q:为什么logistic regression的损失函数不能和linear regression一样,是square error?
A:可以试一下 logistic regression + square error.
在第3步的梯度下降法中, L ( f ) = 1 2 ∑ n ( f ( x n ) − y ^ n ) 2 L(f)=\frac{1}{2} \sum_{n}\left(f\left(x^{n}\right)-\hat{y}^{n}\right)^{2} L(f)=21∑n(f(xn)−y^n)2对 w w w求导后的结果为 ( f w , b ( x ) − y ^ ) f w , b ( x ) ( 1 − f w , b ( x ) ) x i \left(f_{w, b}(x)-\hat{y}\right) f_{w, b}(x)\left(1-f_{w, b}(x)\right) x_{i} (fw,b(x)−y^)fw,b(x)(1−fw,b(x))xi(博主简化了常数项,只保留了函数的主体)
在下列四种情况下:
- 真值 y ^ n = 1 \hat{y}^n=1 y^n=1,预测值 f w , b ( x n ) = 1 f_{w,b}(x^n)=1 fw,b(xn)=1,离目标很近时,梯度为0;
- 真值 y ^ n = 1 \hat{y}^n=1 y^n=1,预测值 f w , b ( x n ) = 0 f_{w,b}(x^n)=0 fw,b(xn)=0,离目标很远时,梯度为0;
- 真值 y ^ n = 0 \hat{y}^n=0 y^n=0,预测值 f w , b ( x n ) = 1 f_{w,b}(x^n)=1 fw,b(xn)=1,离目标很远时,梯度为0;
- 真值 y ^ n = 0 \hat{y}^n=0 y^n=0,预测值 f w , b ( x n ) = 0 f_{w,b}(x^n)=0 fw,b(xn)=0,离目标很近时,梯度为0;
梯度更新的效果都不好。因为不论预测值离目标远还是近,更新速度都很慢。

生成模型(上一章中利用高斯分布求后验概率的模型)和判别模型(logistic regression)的差异。
生成模型作了假设,而判别模型没有作假设。
生成模型:
P ( C 1 ∣ x ) = P ( C 1 ) P ( x ∣ C 1 ) P ( C 1 ) P ( x ∣ C 1 ) + P ( C 2 ) P ( x ∣ C 2 ) = σ ( z ) z = ( μ 1 − μ 2 ) T Σ − 1 x − 1 2 ( μ 1 ) T Σ − 1 μ 1 + 1 2 ( μ 2 ) T Σ − 1 μ 2 + ln N 1 N 2 \begin{aligned} P\left(C_{1} | x\right)&=\frac{P\left(C_{1}\right) P\left(x | C_{1}\right)}{P\left(C_{1}\right) P\left(x | C_{1}\right)+P\left(C_{2}\right) P\left(x | C_{2}\right)}=\sigma(z)\\ z&=\left(\mu^{1}-\mu^{2}\right)^{T} \Sigma^{-1}x-\frac{1}{2}\left(\mu^{1}\right)^{T} \Sigma^{-1} \mu^{1}+\frac{1}{2}\left(\mu^{2}\right)^{T} \Sigma^{-1} \mu^{2}+\ln \frac{N_{1}}{N_{2}} \end{aligned} P(C1∣x)z=P(C1)P(x∣C1)+P(C2)P(x∣C2)P(C1)P(x∣C1)=σ(z)=(μ1−μ2)TΣ−1x−21(μ1)TΣ−1μ1+21(μ2)TΣ−1μ2+lnN2N1判别模型:
f w , b ( x ) = P w , b ( C 1 ∣ x ) = σ ( z ) = σ ( ∑ i w i x i + b ) f_{w,b}(x)=P_{w, b}\left(C_{1} | x\right)=\sigma(z)=\sigma(\sum_{i} w_{i} x_{i}+\boldsymbol b) fw,b(x)=Pw,b(C1∣x)=σ(z)=σ(i∑wixi+b)同样的数据,用生成模型和判别模型得到的 w w w和 b b b是不一样的。
普遍认为,生成模型的性能不如判别模型的性能。不过,生成模型也有优点:
- 因为假设了概率分布,所以需要的训练数据较少。
- 因为假设了概率分布,所以受噪声影响较小。
- 可以从其它资源处估算先验概率和类别独立概率。
然后,李宏毅老师继续介绍了多分类问题,以三分类问题为例子,引入了softmax函数。
从二分类logistic regression到多分类logistic regression的交叉熵问题:补充资料(多类别逻辑回归 与 交叉熵损失函数)
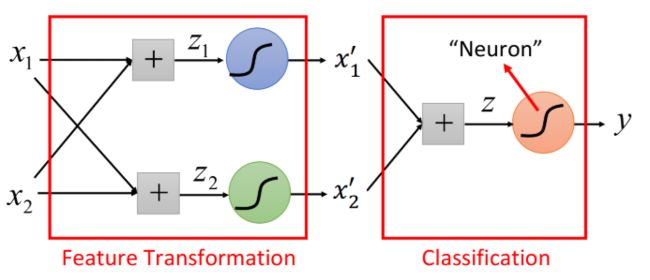
最后,李宏毅老师提到了 logistic regression 的局限,由此引出了特征转换(feature regression),将多个logistic regression模型联结起来组成了神经网络,而其中的一个 logistic regression 模型就是一个神经元(neuron)。
博主的题外话:这个从logistic regression到神经网络的引入确实厉害,值得大家认真听一下。
3. Deep Learning
Brief Introduction of Deep Learning(P12)
首先,李宏毅老师介绍了深度学习的发展历程,以及在Google上搜索Deep Learning的结果。
实际上,早在上个世纪,深度学习就已经以multi-layer perceptron(多层感知机)的名字出现了,然而,它的效果不太好。目前,得益于GPU可以并行地完成矩阵运算,Deep Learning的训练速度有了大幅度提升。
然后,李宏毅老师介绍了深度学习中的“机器学习三步骤”。
其中,用实际数字讲解了模型的运作过程,以手写数字图像识别举例说明。
在深度学习中,模型集合也可指网络结构,这里以全连接前向传播网络(Fully Connect Feedforward Network)为例:
- 定义模型集合
深度学习的函数集合可以理解成Logistic Regression的套娃
a 1 = σ ( W 1 x + b 1 ) a 2 = σ ( W 2 b 1 + b 2 ) = σ ( W 2 σ ( W 1 x + b 1 ) + b 2 ) . . . y = f ( x ) = σ ( W L . . . σ ( W 2 σ ( W 1 x + b 1 ) + b 2 ) + b L ) \begin{aligned} a^1&=\sigma(W^1x+b^1)\\ a^2&=\sigma(W^2b^1+b^2)=\sigma(W^2\sigma(W^1x+b^1)+b^2)\\ ...\\ y&=f(x)=\sigma(W^L...\sigma(W^2\sigma(W^1x+b^1)+b^2)+b^L) \end{aligned} a1a2...y=σ(W1x+b1)=σ(W2b1+b2)=σ(W2σ(W1x+b1)+b2)=f(x)=σ(WL...σ(W2σ(W1x+b1)+b2)+bL)
注1:图中每一个圆圈,就是一个neuron(神经元),即上一章的一个Logistic Regression,但其中不一定是sigmoid函数,还可能是其它的激活函数(Activation Function)
注2:x所在层(最左侧)是Input Layer,但并不是严格意义上的layer,只是一个输入;y所在层是Output Layer;中间的即为Hidden layer(隐藏层)- 定义损失函数(LOSS)来评价模型好坏
与Logistic Regression相同,用交叉熵损失。
假设一个多分类的训练数据 ( x , y ^ ) (x,\hat{y}) (x,y^),预测值是 y y y,其中, y ^ = [ 0 , 0 , 0 , . . . , 1 , . . . 0 , 0 ] \hat{y}=[0,0,0,...,1,...0,0] y^=[0,0,0,...,1,...0,0]是one-hot编码。如果总共有M个类别, y ^ \hat{y} y^就是M维。这个训练数据的损失就是 C ( y , y ^ ) = − ∑ i = 1 M y i ^ ln y i C(y,\hat{y})=-\sum\limits_{i=1}^M\hat{y_i}\ln y_i C(y,y^)=−i=1∑Myi^lnyi。
假设有N个训练数据,总的LOSS就是所有训练数据的交叉熵之和:
L = ∑ n = 1 N C n L=\sum\limits_{n=1}^NC^n L=n=1∑NCn
“从模型集合中找到一个最好的模型,减小总的损失 L L L”就变成了“找到一个最好的网络参数 θ ∗ \theta^* θ∗,减小总的损失 L L L”- 找到最佳模型
梯度下降法。神经网络特有的反向传播(backpropagation)算法,计算 ∂ L ∂ w \frac{\partial{L}}{\partial{w}} ∂w∂L,下一章详细说。

对于反向传播(backpropagation)算法,有一些现成的框架可以使用:Tensorflow,pytorch,Caffe,Theano等。
期间,李宏毅老师还解答了多数人对于神经网络模型的几个问题。
Q:我应该如何确定神经网络有多少层?每层有多少个神经元?
A:凭经验+直觉。在神经网络模型被广泛使用前,人们做机器学习的重点在于如何设计与提取好的特征;有了神经网络提取特征之后,机器学习研究的侧重点就变成了如何设计好的模型,让机器自己去找好的特征。
Q:神经网络是不是越深越好?
A:理论上应该如此,神经网络越深,参数越多,模型越复杂,包含的模型集合越大,bias越小。再通过更多的数据,就可以让variance也更小。但是实际情况并没有这么简单(见下一章)。
最后,李宏毅老师提到了Universality Theorem,并提出了一个问题“为什么是deep神经网络(瘦长,有多个隐藏层),而不是fat神经网络(扁平,只有一个隐藏层,但有许许多多神经元)?”,将在P15解答。
Backpropagation(P13)
首先,李宏毅老师复习了一遍神经网络中的梯度下降法。
因为反向传播(backpropagation)算法的基石是Chain Rule(链式法则),所以李宏毅老师简单介绍了链式法则。
链式法则
- 例1: y = g ( x ) y=g(x) y=g(x), z = h ( y ) z=h(y) z=h(y):
Δ x → Δ y → Δ z \Delta x\rightarrow\Delta y\rightarrow\Delta z Δx→Δy→Δz
d z d x = d z d y d y d x \frac{d z}{d x}=\frac{d z}{d y} \frac{d y}{d x} dxdz=dydzdxdy- 例2: x = g ( s ) x=g(s) x=g(s), y = h ( s ) y=h(s) y=h(s), z = h ( x , y ) z=h(x,y) z=h(x,y):
Δ s → Δ x → Δ z \Delta s\rightarrow\Delta x\rightarrow\Delta z Δs→Δx→Δz
Δ s → Δ y → Δ z \Delta s\rightarrow\Delta y\rightarrow\Delta z Δs→Δy→Δz
d z d s = ∂ z ∂ x d x d s + ∂ z ∂ y d y d s \frac{d z}{d s}=\frac{\partial z}{\partial x} \frac{d x}{d s}+\frac{\partial z}{\partial y} \frac{d y}{d s} dsdz=∂x∂zdsdx+∂y∂zdsdy
然后,李宏毅老师正式开始讲解如何在神经网络中进行梯度下降法(即反向传播)。
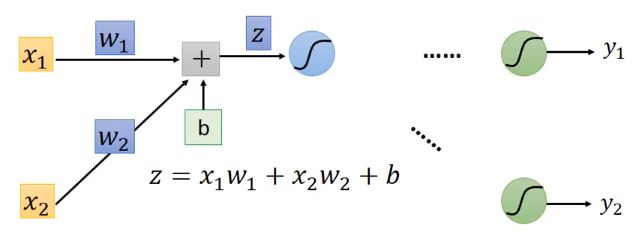
以每层都是两个神经元的全连接神经网络模型为例:
损失函数为: L ( θ ) = ∑ n = 1 N C n ( θ ) L(\theta)=\sum_{n=1}^{N} C^{n}(\theta) L(θ)=n=1∑NCn(θ)
对 θ \theta θ中的某一个参数 w w w求导后:
∂ L ( θ ) ∂ w = ∑ n = 1 N ∂ C n ( θ ) ∂ w \frac{\partial L(\theta)}{\partial w}=\sum_{n=1}^{N} \frac{\partial C^{n}(\theta)}{\partial w} ∂w∂L(θ)=n=1∑N∂w∂Cn(θ)
是N个训练数据的交叉熵求和的结果。提取出其中一个训练数据的交叉熵求导,简写成 ∂ C ∂ w \frac{\partial C}{\partial w} ∂w∂C.
第一次应用链式法则(记作式1):
∂ C ∂ w = ∂ z ∂ w ∂ C ∂ z \frac{\partial C}{\partial w}=\frac{\partial z}{\partial w} \frac{\partial C}{\partial z} ∂w∂C=∂w∂z∂z∂C
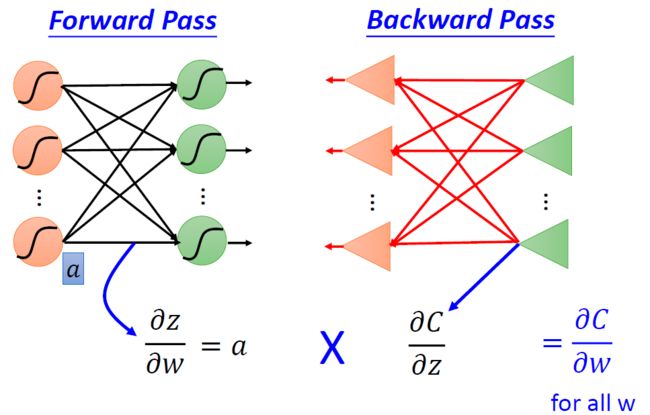
- 前向传播(Forward Pass):对所有参数计算 ∂ z ∂ w \frac{\partial z}{\partial w} ∂w∂z
观察到 ∂ z ∂ w 1 = x 1 \frac{\partial z}{\partial w_1}=x_1 ∂w1∂z=x1, ∂ z ∂ w 2 = x 2 \frac{\partial z}{\partial w_2}=x_2 ∂w2∂z=x2
总结: ∂ z ∂ w \frac{\partial z}{\partial w} ∂w∂z的值就是与 z z z以权重 w w w连接的输入(第一层是 x x x,从第二层开始,是前一层的输出)的值。- 后向传播(Backward Pass):对所有激活函数的输入 z z z,计算 ∂ C ∂ z \frac{\partial C}{\partial z} ∂z∂C
第二次应用链式法则(记作式2):
∂ C ∂ z = ∂ a ∂ z ∂ C ∂ a = σ ′ ( a ) ∂ C ∂ a \frac{\partial C}{\partial z}=\frac{\partial a}{\partial z}\frac{\partial C}{\partial a}=\sigma'(a)\frac{\partial C}{\partial a} ∂z∂C=∂z∂a∂a∂C=σ′(a)∂a∂C
第三次应用链式法则(记作式3):
∂ C ∂ a = ∂ z ′ ∂ a ∂ C ∂ z ′ + ∂ z ′ ′ ∂ a ∂ C ∂ z ′ ′ = w 3 ∂ C ∂ z ′ + w 4 ∂ C ∂ z ′ ′ \frac{\partial C}{\partial a}=\frac{\partial z'}{\partial a}\frac{\partial C}{\partial z'}+\frac{\partial z''}{\partial a}\frac{\partial C}{\partial z''}=w_3\frac{\partial C}{\partial z'}+w_4\frac{\partial C}{\partial z''} ∂a∂C=∂a∂z′∂z′∂C+∂a∂z′′∂z′′∂C=w3∂z′∂C+w4∂z′′∂C
把式3代回式2(记作式4): ∂ C ∂ z = σ ′ ( a ) ( w 3 ∂ C ∂ z ′ + w 4 ∂ C ∂ z ′ ′ ) \frac{\partial C}{\partial z}=\sigma'(a)\left(w_3\frac{\partial C}{\partial z'}+w_4\frac{\partial C}{\partial z''}\right) ∂z∂C=σ′(a)(w3∂z′∂C+w4∂z′′∂C)
对式4的求解,又分两种情况讨论:
- z ′ z' z′和 z ′ ′ z'' z′′之后是输出层:
∂ C ∂ z ′ = ∂ y 1 ∂ z ′ ∂ C ∂ y 1 \frac{\partial C}{\partial z'}=\frac{\partial y_1}{\partial z'}\frac{\partial C}{\partial y_1} ∂z′∂C=∂z′∂y1∂y1∂C
∂ C ∂ z ′ ′ = ∂ y 2 ∂ z ′ ∂ C ∂ y 2 \frac{\partial C}{\partial z''}=\frac{\partial y_2}{\partial z'}\frac{\partial C}{\partial y_2} ∂z′′∂C=∂z′∂y2∂y2∂C
等号右侧的每个值都是可以一步计算出来的。
- z ′ z' z′和 z ′ ′ z'' z′′之后不是输出层:
不断递归计算 ∂ C ∂ z ′ \frac{\partial C}{\partial z'} ∂z′∂C以及 ∂ C ∂ z ′ ′ \frac{\partial C}{\partial z''} ∂z′′∂C,直到输出层。
上面提到的递归计算,实际上可以变成从输出层 y y y向输入层 x x x(反向地)传递值。
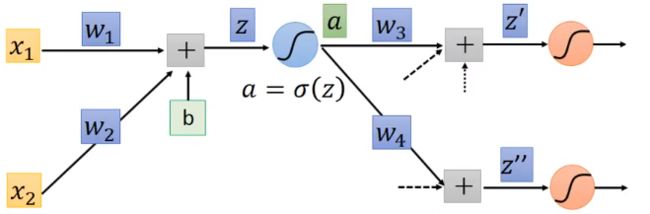
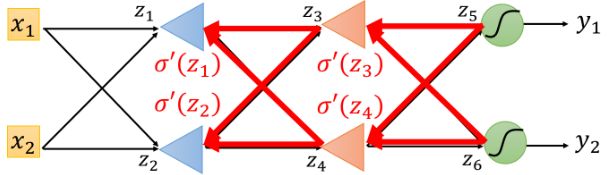
最后,李宏毅老师简单总结了反向传播算法(Backpropogation)中前向传播(Forward Pass)和后向传播(Backward Pass)的过程。
总结:
Tips for Training DNN(P14)
这章关于深度神经网络(Deep Neural Network)训练过程中的一些方法和技巧。
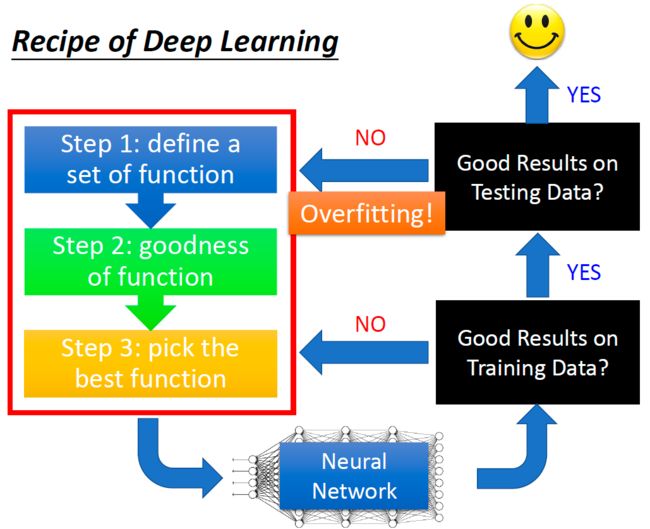
首先,李宏毅老师回顾了机器学习的三步骤,与神经网络的训练、测试过程。
如果模型在训练数据上的结果不好,并不叫作过拟合,而是你没有训练好模型,你应该重新调整模型(修改模型、损失函数等)
如果模型在训练数据上的结果好,接下来就在测试数据(这里指验证集或者是private测试数据)上进行测试。此时,如果结果不好,才叫做过拟合。
如果模型在测试数据上的结果好,那么你就完成了神经网络的训练。
然后,李宏毅老师介绍了:当训练结果不好或测试结果不好时,一些可行的解决方法。
当训练结果不好时,可以考虑:
- 新的激活函数(New activation function)
- 自动调整学习率(Adaptive Learning Rate)
当测试结果不好时,可以考虑:
- 提前终止(Early Stopping)
- 正则化(Regularization)
- Dropout
之后,对这些方法逐一详细介绍。
首先,训练结果不好时,第一个原因可能是sigmoid函数存在梯度消失(gradient vanishing)的问题,李宏毅老师分析了其中的原因,提出了线性激活函数ReLU(及其变体)、Maxout,对它们进行了详细介绍。
Q:为什么会出现梯度消失?
A:因为sigmoid函数: R → ( 0 , 1 ) R\rightarrow(0,1) R→(0,1),所以,当输入 x x x的变化量 Δ x \Delta x Δx很大时,输出 y y y的变化量 Δ y \Delta y Δy很小。神经网络的模型结构决定了:接近输出层 y y y的隐藏层,梯度大、学习快,当它们很快收敛的时候,接近输入层 x x x的隐藏层,梯度小、学习慢,参数几乎还是随机的。因此,模型训练后在训练集上的结果不好。
新的激活函数:
ReLU(Rectified Linear Unit)
ReLU的变体:Leaky ReLU、Parametric ReLU
以上三个函数,在 z = 0 z=0 z=0是不可微的,但是由于 z = 0 z=0 z=0的情况很少出现,因此可以忽略不计。当 z = 0 z=0 z=0时,给它的导数随意赋一个值即可,比如:赋值0.Maxout
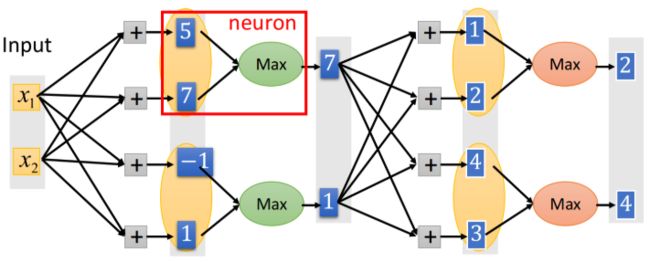
将同一层的几个神经元(个数需要自己设定)绑定为一组,下一层的输入取每组里的输出的最大值。类似于卷积神经网络的Max Pooling(在CNN这一章会讲到)
可以认为ReLU其实也是Maxout的一个特例:
Maxout可以做到比ReLU更多:
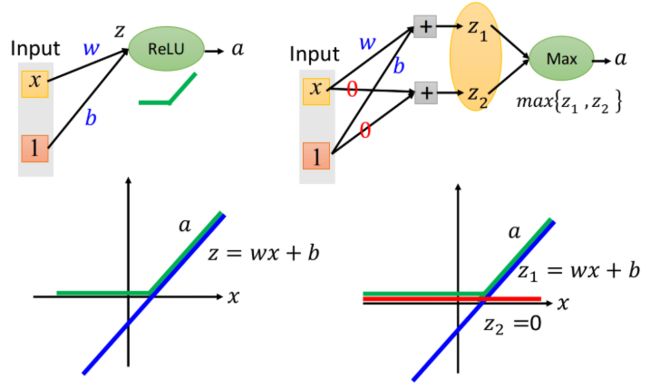
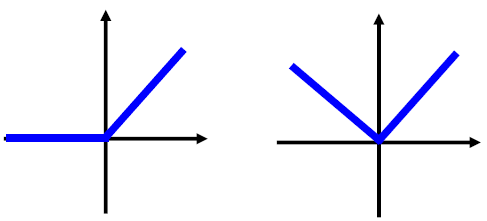
当一组只有两个神经元时,可能拟合的函数形状:
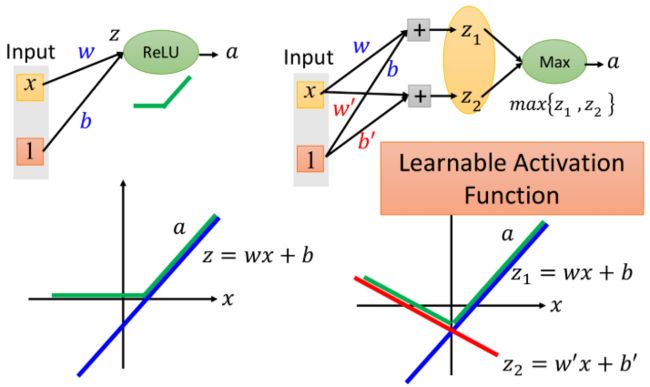
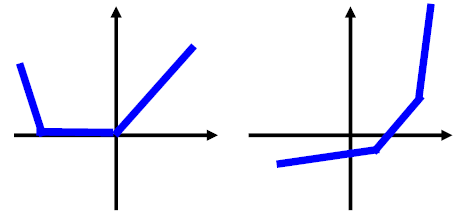
当一组有三个神经元时,可能拟合的函数形状:
而用maxout训练的时候,一个数据 x x x输入时,Maxout之后,最大值已经确定,其本质还是线性的,可以按照线性模型的情形求导。
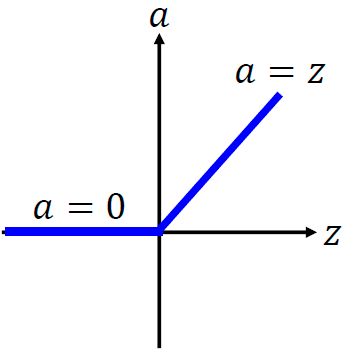

然后是自动调整学习率,先复习了一下Adagrad的做法,又介绍了RMSProp、动量Momentum、Adam几种其它自动调整学习率的方法。
自动调整学习率
- Adagrad
参数更新公式为
w t + 1 ← w t − η ∑ i = 0 t ( g i ) 2 g t w^{t+1} \leftarrow w^{t}-\frac{\eta}{\sqrt{\sum_{i=0}^{t}\left(g^{i}\right)^{2}}} g^{t} wt+1←wt−∑i=0t(gi)2ηgt- RMSProp
参数更新公式为:
w t + 1 = w t − η σ t g t σ t = α ( σ t − 1 ) 2 + ( 1 − α ) ( g t ) 2 \begin{aligned} & w^{t+1}=w^{t}-\frac{\eta}{\sigma^{t}} g^{t} \\ \sigma^{t}=& \sqrt{\alpha\left(\sigma^{t-1}\right)^{2}+(1-\alpha)\left(g^{t}\right)^{2}} \end{aligned} σt=wt+1=wt−σtηgtα(σt−1)2+(1−α)(gt)2
可以改变 α \alpha α的值: α \alpha α小,倾向于相信新的梯度; α \alpha α大,倾向于相信旧的梯度。- Momentum
用到了物理学中动量/惯性的知识:比如当一个物体从高处滑下坡,遇到V形坡的爬坡部分时,不会立刻倒退,而是会继续向前移动一段距离。
参数更新公式为:
假设起点 θ 0 \theta^0 θ0,开始的运动方向 v 0 = 0 v^0=0 v0=0
v 1 = λ v 0 − η ∇ L ( θ 0 ) = 0 − η ∇ L ( θ 0 ) = − η ∇ L ( θ 0 ) v^{1}=\lambda v^{0}-\eta \nabla L\left(\theta^{0}\right)=0-\eta \nabla L\left(\theta^{0}\right)=-\eta \nabla L\left(\theta^{0}\right) v1=λv0−η∇L(θ0)=0−η∇L(θ0)=−η∇L(θ0),移动到 θ 1 \theta^1 θ1
v 2 = λ v 1 − η ∇ L ( θ 1 ) = − λ η ∇ L ( θ 0 ) − η ∇ L ( θ 1 ) v^{2}=\lambda v^{1}-\eta \nabla L\left(\theta^{1}\right)=-\lambda\eta \nabla L\left(\theta^{0}\right)-\eta \nabla L\left(\theta^{1}\right) v2=λv1−η∇L(θ1)=−λη∇L(θ0)−η∇L(θ1),移动到 θ 2 \theta^2 θ2
……
v t v^t vt实际上是到 θ t \theta^t θt之前所有梯度的加权求和。这里的 v t v^t vt就是新的 g t g^t gt。- Adam
其实,Adam就是RMSPRop加上Momentum
参数更新公式为:
m t = β 1 m t − 1 + ( 1 − β 1 ) g t v t = β 2 v t − 1 + ( 1 − β 2 ) g t 2 m ^ t = m t 1 − β 1 t v ^ t = v t 1 − β 2 t θ t + 1 = θ t − η v ^ t + ϵ m ^ t \begin{aligned} m_{t} &=\beta_{1} m_{t-1}+\left(1-\beta_{1}\right) g_{t} \\ v_{t} &=\beta_{2} v_{t-1}+\left(1-\beta_{2}\right) g_{t}^{2} \\ \hat{m}_{t} &=\frac{m_{t}}{1-\beta_{1}^{t}} \\ \hat{v}_{t} &=\frac{v_{t}}{1-\beta_{2}^{t}} \\ \theta_{t+1} &=\theta_{t}-\frac{\eta}{\sqrt{\hat{v}_{t}}+\epsilon} \hat{m}_{t} \end{aligned} mtvtm^tv^tθt+1=β1mt−1+(1−β1)gt=β2vt−1+(1−β2)gt2=1−β1tmt=1−β2tvt=θt−v^t+ϵηm^t
η v ^ t + ϵ \frac{\eta}{\sqrt{\hat{v}_{t}}+\epsilon} v^t+ϵη的分子就是RMSPRop的部分,而 m ^ t \hat{m}_{t} m^t就是Momentum的部分。
ϵ \epsilon ϵ是防止除零, m ^ t = m t 1 − β 1 t \hat{m}_{t} =\frac{m_{t}}{1-\beta_{1}^{t}} m^t=1−β1tmt 与 v ^ t = v t 1 − β 2 t \hat{v}_{t}=\frac{v_{t}}{1-\beta_{2}^{t}} v^t=1−β2tvt是对 m t m_{t} mt与 v t v_t vt做偏差校正(bias correction)。

接下来,是在测试数据(test dataset)上结果不好时的应对方法:提前终止、正则化、dropout.
提前终止(Early Stopping):
在训练时,模型对训练数据的过程是:欠拟合→刚好拟合→过拟合,因此需要在那个刚好拟合的点上提前终止训练。以validation set作为验证时,应该是在loss不降反增的那个转折点终止训练。

正则化(Regularization):在原来的损失函数 L ( θ ) L(\theta) L(θ)上定义新的损失函数 L ′ ( θ ) L'(\theta) L′(θ),将模型的优化目标变为减小 L ′ ( θ ) L'(\theta) L′(θ)。常用的是L1正则化和L2正则化。
假设参数 θ = { w 1 , w 2 , . . . } \theta=\{w_1,w_2,...\} θ={ w1,w2,...},
- L2 正则化: ∣ ∣ θ ∣ ∣ 2 = ( w 1 ) 2 + ( w 2 ) 2 + . . . ||\theta||_2=(w_1)^2+(w_2)^2+... ∣∣θ∣∣2=(w1)2+(w2)2+...
L ′ ( θ ) = L ( θ ) + λ 1 2 ∣ ∣ θ ∣ ∣ 2 L'(\theta)=L(\theta)+\lambda\frac{1}{2}||\theta||_2 L′(θ)=L(θ)+λ21∣∣θ∣∣2
一般不会考虑偏差项 b b b,因为它与函数平滑程度无关。
梯度: ∂ L ′ ∂ w = ∂ L ∂ w + λ w \frac{\partial L'}{\partial w}=\frac{\partial L}{\partial w}+\lambda w ∂w∂L′=∂w∂L+λw
参数更新: w t + 1 = w t − η ∂ L ′ ∂ w = w t − η ( ∂ L ∂ w + λ w ) = ( 1 − η λ ) w t − η ∂ L ∂ w w^{t+1}=w^t - \eta \frac{\partial L'}{\partial w}=w^t -\eta\left(\frac{\partial L}{\partial w}+\lambda w\right)=(1-\eta \lambda)w^t-\eta \frac{\partial L}{\partial w} wt+1=wt−η∂w∂L′=wt−η(∂w∂L+λw)=(1−ηλ)wt−η∂w∂L
此处, λ \lambda λ取0.001之类的值,使得 w t w^t wt 前面的系数 ( 1 − η λ ) (1-\eta \lambda) (1−ηλ) 随着 t t t 的迭代,越来越趋近于0.
- L1 正则化: ∣ ∣ θ ∣ ∣ 1 = ∣ w 1 ∣ + ∣ w 2 ∣ + . . . ||\theta||_1=|w_1|+|w_2|+... ∣∣θ∣∣1=∣w1∣+∣w2∣+...
L ′ ( θ ) = L ( θ ) + λ 1 2 ∣ ∣ θ ∣ ∣ 1 L'(\theta)=L(\theta)+\lambda\frac{1}{2}||\theta||_1 L′(θ)=L(θ)+λ21∣∣θ∣∣1
梯度: ∂ L ′ ∂ w = ∂ L ∂ w + λ sgn ( w ) \frac{\partial L'}{\partial w}=\frac{\partial L}{\partial w}+\lambda \operatorname{sgn}(w) ∂w∂L′=∂w∂L+λsgn(w),此处的 sgn ( w ) \operatorname{sgn}(w) sgn(w) 是信号函数,当 w ≥ 0 w\ge0 w≥0时, sgn ( w ) = 1 \operatorname{sgn}(w)=1 sgn(w)=1;当 w < 0 w<0 w<0时, sgn ( w ) = − 1 \operatorname{sgn}(w)=-1 sgn(w)=−1.
参数更新: w t + 1 = w t − η ∂ L ′ ∂ w = w t − η ( ∂ L ∂ w + λ sgn ( w t ) ) = w t − η ∂ L ∂ w − η λ sgn ( w t ) w^{t+1}=w^t - \eta \frac{\partial L'}{\partial w}=w^t - \eta\left(\frac{\partial L}{\partial w}+\lambda \operatorname{sgn}(w^t)\right)=w^t -\eta\frac{\partial L}{\partial w}-\eta\lambda\operatorname{sgn}(w^t) wt+1=wt−η∂w∂L′=wt−η(∂w∂L+λsgn(wt))=wt−η∂w∂L−ηλsgn(wt)
L1 训练结果:权重会比较稀疏,有的参数很小,接近于0;有的参数很大。
L2 训练结果:平均都比较小。
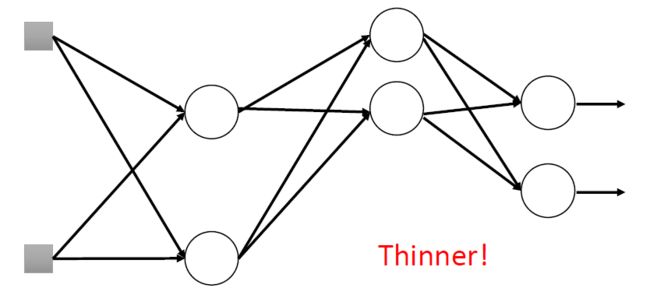
Dropout:在每次参数更新前,每个神经元有 p % p\% p% 的概率被丢弃,相连的权重也会被丢弃。随着丢弃部分神经元,神经网络的结构发生改变(变瘦长了!),用这个新的神经网络做训练。
每个 mini-batch ,都会重新选择被丢弃的神经元。
在训练的时候结果会变差,但是对于验证集和测试集,利用 dropout 后,结果会变好。
测试的时候,不需要 dropout,如果训练时,丢弃神经元的概率是 p % p\% p% ,测试时,所有权重都要乘 ( 1 − p % ) (1-p\%) (1−p%) .
Dropout 是一种集成学习方法:
- 训练时:假设有 M M M 个神经元,就有 2 M 2^M 2M 个可能的神经网络。
- 每次用一个mini-batch训练一个网络。
- 所有神经元共享同样的参数。
- 测试时:多个神经网络集成后取平均值 = 一个神经网络的权重乘以 ( 1 − p % ) (1-p\%) (1−p%)
当激活函数是线性的(ReLU,Maxout)的情况下,dropout 效果比较好;
当激活函数是非线性的(sigmoid)的情况下,dropout效果一般。
Why Deep-(P15)
这一讲主要解答了P12最后的问题“为什么是deep神经网络(瘦长,有多个隐藏层),而不是fat神经网络(扁平,只有一个隐藏层,但有许许多多神经元)?”
首先,把深度神经网络与扁平神经网络对比的前提是,确保它们的参数个数一样多。如果在比较两者时,它们的参数不一样多,那么参数越多,模型效果越好,这是一件很正常的事情。
表中,左侧两列是深度神经网络的层数x大小、错误率(越低越好);右侧两列是扁平神经网络的层数x大小、错误率(越低越好)。同一行的两个神经网络的参数数量相同。
从图中可以看到,在深度神经网络与扁平神经网络的参数数量差不多相同的情况下,深度神经网络的效果比扁平神经网络的效果要好。

然后,李宏毅老师仔细介绍了其中可能的原因。
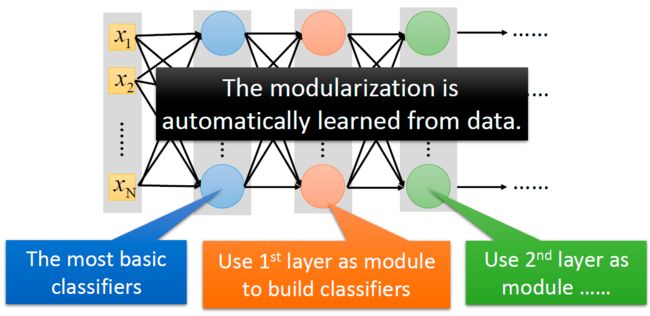
深度神经网络效果的好的原因是它可以做到模块化,需要的训练数据比较少(“神经网络需要较少的训练数据”这一点和传统的认知恰恰相反)。
比如,第一层是最基本的分类器,第二层的分类器基于第一层的输出分类,第三层的分类器基于第二层的分类输出……以此类推。
当然,如何模块化是由模型自己从数据中学习到的。
由于这一集视频是两次课程拼接的,因此中间有一部分复习了上一节课的内容。接下来,李宏毅老师用语音识别的例子进一步解释了深度神经网络的模块化。
注:因为语音识别涉及一些语言学的知识。比如:phoneme(音素)的概念,IPA(国际音标)表。所以,既听不懂又不做语音识别的,可以跳过。
在语音识别中,把三个音素+状态作为音学特征(acoustic feature)
所有的状态共用一个DNN,DNN的输入是一个音学特征,输出是每个状态的概率(输出层大小等于状态个数)
这里,DNN的模块化作用类似于IPA表中的方法来进行识别,比如先判断发音时,舌头上下的位置,再判断舌头的前后位置。
然后,李宏毅老师开始介绍 Universality Theorem.
Universality Theorem:如果神经网络的隐藏层的神经元足够多,那么任意连续的函数 f : R N → R M f:R^N\rightarrow R^M f:RN→RM 都可以用一个单层的隐藏层的神经网络实现。(但是,深度神经网络的效果更好)
李宏毅老师进行了一系列类比来帮助理解。比如:用逻辑电路来进行类比,说明 Universality Theorem;用剪窗花的例子来解释深度神经网络的优越性。
早期的计算机视觉中一些模块是由专家根据经验提出的,形成了一个处理图像的流水线;而深度神经网络用端到端的学习,自动学习到了流水线中每个函数的分工。
专家根据经验提出一系列函数和方法(DFT、DCT、MFCC等):
深度神经网络自己学习到的函数和方法( f 1 f_1 f1、 f 2 f_2 f2、 f 3 f_3 f3等):


PyTorch Tutorial(P16)
* 2020新增内容,由助教讲授
这一讲比较重要,讲了PyTorch的一些函数和方法,建议完整学习。