Python进阶之路(3):提取公众号后台数据并数据可视化
公众号后台有丰富的数据统计,但是可能依然没有我想要的统计指标。比如,我公众号粉丝量虽然不高,但是阅读率却普遍很高,那我能不能根据我公众号每篇文章的阅读率的变化情况,画一张散点图,来展现我的公众号运营成果呢?
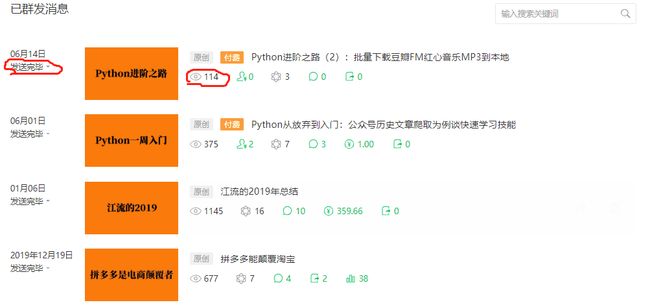
登陆后台发现,公众号每篇文章发送情况的左侧,点击发送完毕按钮,可以看到送达人数,这是公众号发某篇文章前的粉丝数,而标题下方有阅读数。通过爬虫,依次提取每篇文章的送达人数和阅读数,根据公式:阅读率=阅读数/送达人数,就可以计算出每篇文章的阅读率了。
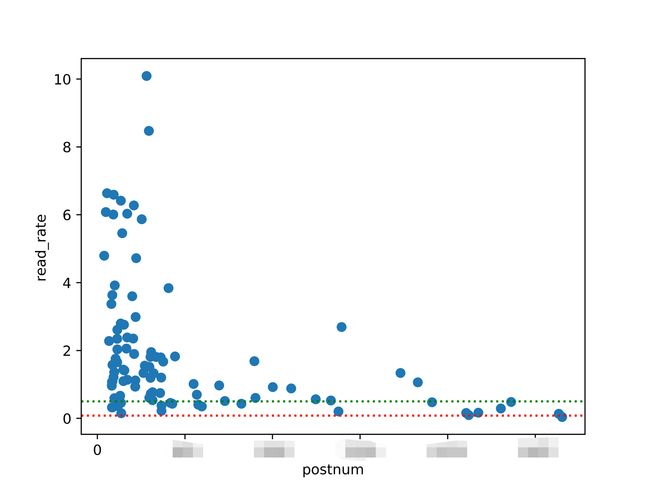
思路一:在进行数据可视化的时候,用该篇文章的当前粉丝数作为横轴,用该篇文章的阅读率作为纵轴,就可以画出每篇文章的阅读率分布。然后加上一条普通公众号的平均阅读率辅助线,就可以展现出本公众号的阅读率和一般公众号相比是什么水平。
思路二:还有一种思路,对文章阅读率从小到大依次进行排序,横轴为文章编号,纵轴为阅读率,这样可以画一张帕累托累进图,加上一条普通公众号平均阅读率的辅助线,就可以直观看出有多大比例的文章高于平均阅读率,并且可以让读者忽略粉丝数这条信息。
在散点图的基础上,还可以再加上文章阅读量大小,用散点的大小来表示,但是考虑到我有一百篇文章代表一百个点,有些文章的阅读率非常高,用散点大小表示的话,不便阅读,于是放弃这个思路。
预计的编程逻辑:
(1)登陆到公众号后台主页。
这一步我在第一个爬取公众号文章url链接生成pdf文档的项目中已经实现过,直接套用过来就可以。
(2)定义一个抓取送达人数和阅读数的动作。
这是个难点。
(3)进行循环,依次抓取每一页的7条文章数据,写入一个字典数据里。
公众号翻页的for循环在第一个爬取公众号文章的项目中也已经实现过了,本次稍作改编套用即可。
(4)将数据存入csv文件。
这个动作之前也实现过。
(5)通过pandas导入csv文件里的数据,并进行数据清洗,如计算阅读率。
(6)通过matplotlib等库,根据清洗好的数据,绘图。
实际实现起来,遇到了诸多问题,我们一个个解决,一步步推进。
具体步骤
导入模块
我后来导入了以下这些模块,并不是每个都用上了,并不是开始就想到要导入这些,而是在实现程序的过程中,慢慢发现需要导入某个模块。
from selenium import webdriver
import re
import time
import pickle
import csv
from selenium.common.exceptions import TimeoutException
登陆公众号后台
Python从放弃到入门那一篇,已经讲过了。构造了一个登陆的函数,之后需要调用登陆函数,传入参数为公众号的用户名和密码。
def login(username, password):
#打开微信公众号登录页面
driver.get('https://mp.weixin.qq.com/')
driver.maximize_window()
time.sleep(3)
driver.find_element_by_xpath("//*[@id=\"header\"]/div[2]/div/div/div[2]/a").click()
# 自动填充帐号密码
driver.find_element_by_xpath("//*[@id=\"header\"]/div[2]/div/div/div[1]/form/div[1]/div[1]/div/span/input").clear()
driver.find_element_by_xpath("//*[@id=\"header\"]/div[2]/div/div/div[1]/form/div[1]/div[1]/div/span/input").send_keys(username)
driver.find_element_by_xpath("//*[@id=\"header\"]/div[2]/div/div/div[1]/form/div[1]/div[2]/div/span/input").clear()
driver.find_element_by_xpath("//*[@id=\"header\"]/div[2]/div/div/div[1]/form/div[1]/div[2]/div/span/input").send_keys(password)
time.sleep(1)
#自动点击登录按钮进行登录
driver.find_element_by_xpath("//*[@id=\"header\"]/div[2]/div/div/div[1]/form/div[4]/a").click()
# 手动拿手机扫二维码!
time.sleep(15)
定义抓取送达人数和阅读数的函数
使用Chrome浏览器登陆公众号后台,按F12查看网页代码,按ctrl+shift+C组合键来查看网页上某个具体的元素。包含“送达人数”文本的那个元素的xpath为
“//*[@id=“list”]/li[1]/div[1]/div[1]/span/div/div/div[2]/p[1]/span”。查看xpath的方式为源代码中点击这个元素所在行,右键选择-copy-copy xpath。
阅读数这个元素的xpath为“//*[@id=“list”]/li[1]/div[2]/span/div/div[2]/div/div[1]/div/span”。由于xpath是精确定位,在一个网页里某个元素只有唯一的xpath,但是我要在这个网页里提取7个同样的元素,如果我选择xpath定位,我就要查看这7个元素的构造规律。或者我可以用class等元素定位,这样我往往能找到同样的class元素出现7次,然后用for循环遍历。
几种元素定位方式我都尝试过了,在本项目中我最终决定用xpath定位的方式。读者不信邪的话可以尝试下其他定位元素的方式。
查找七个元素xpath的规律,发它们只是在li[i]中的i依次增加而已,可以用format函数进行格式化。
搜到菜鸟教程里对format函数的讲解。
格式化字符串的函数 str.format(),它增强了字符串格式化的功能。
基本语法是通过 {} 和 : 来代替以前的 % 。
format 函数可以接受不限个参数,位置可以不按顺序。
>>>"{} {}".format("hello", "world") # 不设置指定位置,按默认顺序
'hello world'
>>> "{0} {1}".format("hello", "world") # 设置指定位置
'hello world'
>>> "{1} {0} {1}".format("hello", "world") # 设置指定位置
'world hello world'
于是我用format函数来构造xpath路径。
'readnum': driver.find_element_by_xpath('//*[@id=\"list\"]/li[{0}]/div[2]/span/div/div[2]/div/div[1]/div/span'.format(i)).text,
for循环构造好后,运行程序,发现提取到的数据没有送达人数,有阅读数。猜想是送达人数的数据被隐藏了,需要点击送达人数按钮,才能调用数据。
于是在每次循环的开始,都设置点击送达人数处。结果是第一行数据的送达人数有数据了,但是之后的六行都没有数据。
于是发现点击送达人数按钮后,生成的新数据框正好挡住了第二行数据,导致提取不到之后的数据。
于是设置在每一次提取完数据后,鼠标点击页面的某个位置,并且这个位置点击后可以无反应。
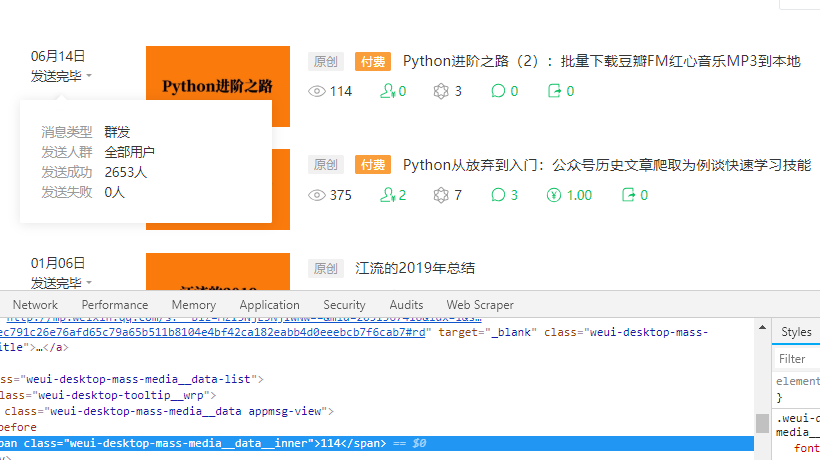
运行程序后,发现可以爬取数据了,但有些数据爬取不到,查看数据发现,每当有删文章的时候,删文后的下一篇文章的数据就提取不到。于是设置当程序执行失败时,也让鼠标点击页面某个无反应的位置,然后continue继续程序的循环。
运行后,发现100条数据里,有两条数据没有提取到,再次运行程序,发现又是有两条数据没有提取到,并且和上一次的两条数据不完全一样。猜想是因为程序执行过快,服务器没来得及返回数据。于是设置了每次循环睡眠1秒钟。
最终获取每一页的送达人数和阅读数的代码如下:
def get_postnum_readnum(html):
lst = []
for i in range(1, 8):
try:
driver.find_element_by_xpath("//*[@id=\"list\"]/li[{0}]/div[1]/div[1]".format(i)).click()
time.sleep(1)
temp_dict = {
'postnum': driver.find_element_by_xpath("//*[@id=\"list\"]/li[{0}]/div[1]/div[1]/span/div/div/div[2]/p[1]/span".format(i)).text,
'readnum': driver.find_element_by_xpath('//*[@id=\"list\"]/li[{0}]/div[2]/span/div/div[2]/div/div[1]/div/span'.format(i)).text,
'title': driver.find_element_by_xpath(
'//*[@id="list"]/li[{0}]/div[2]/span/div/div[2]/a/span'.format(i)).get_attribute(
'textContent'),
'date': driver.find_element_by_xpath("//*[@id=\"list\"]/li[{0}]/div[1]/em".format(i)).text,
}
driver.find_element_by_xpath("//*[@id=\"list_container\"]/div[1]/div[2]/div/span/input").click()
lst.append(temp_dict)
except:
driver.find_element_by_xpath("//*[@id=\"list_container\"]/div[1]/div[2]/div/span/input").click()
continue
return lst
进行循环,依次抓取每页的7条数据
代码和Python从放弃到入门那一篇差不多。
#用webdriver启动谷歌浏览器
chrome_driver = r"C:\Users\jiansi\PycharmProjects\jiansidata\venv\Lib\site-packages\selenium\webdriver\chrome\chromedriver.exe"
driver = webdriver.Chrome(executable_path=chrome_driver)
"""需要手动输入个人微信公众号的账号,密码,要导出的公众号名称"""
username = '' # 账号
password = '' # 密码
login(username, password)
page_num = int(driver.find_elements_by_class_name('weui-desktop-pagination__num__wrp')[-1].text.split('/')[-1])
# 点击下一页
num_lst = get_postnum_readnum(driver.page_source)
#print(num_lst)
for _ in range(1, page_num):
try:
pagination = driver.find_elements_by_class_name('weui-desktop-pagination__nav')[-1]
pagination.find_elements_by_tag_name('a')[-1].click()
time.sleep(5)
num_lst += get_postnum_readnum(driver.page_source)
except:
continue
将数据存入csv文件
代码和Python从放弃到入门那一篇差不多。
with open('2.csv', 'w', encoding="utf-8", newline='') as f:
writer = csv.DictWriter(f, fieldnames=['postnum', 'readnum', 'title', 'date'])
writer.writeheader()
writer.writerows(num_lst)
通过pandas导入csv数据,并进行数据清洗
从这一步开始,我新建了一个文件写入。
导入模块,不一定全用上了。
import sys
import pandas as pd
import csv
import matplotlib.pyplot as plt
from matplotlib.pyplot import savefig
import matplotlib as mpl
import numpy as np
import seaborn as sns
from datetime import datetime
from pandas import to_datetime
我先读取csv表格里的数据,看看读取效果。
"""用pandas读取csv文件里的数据,生成二维表,并合并两张表"""
df1 = pd.read_csv('1.csv', delimiter=',', sep='\t', encoding='utf-8')
df2 = pd.read_csv('2.csv', delimiter=',', sep='\t', encoding='utf-8')
print(df1)
print(df2)
df1.info()
df2.info()
可能会报错,原因和encoding的编码格式有关,可是尝试改变编码格式,从gbk换为gbk18030,或者再换位utf-8,unicode等。
df.info()是查看数据的基本情况,方便观察数据有没有空值等错误。这次数据没有空值,所以处理空值等错误的操作这里就没有采用。
因为我提取了两个公众号的数据,要将两个公众号的数据合并,并且我只需要csv数据里的某几列。
cols1 = df1[['postnum', 'readnum', 'title', 'date']]
cols2 = df2[['postnum', 'readnum', 'title', 'date']]
df3 = cols1.append(cols2, ignore_index=True)
print(df3)
df3就是我合并两张表之后的数据。
由于我的送达人数这列的数据不是纯数字,而是**人的字符串,我需要去掉这个人字,并且变为整数型数据。
我找了一些pandas教程或者公式集锦,发现都没有较如何对某一列的数据进行处理。
后来才知道用pandas里的apply()函数可以实现。并且,apply函数还可以实现对某些列进行运算生成新的列,所以计算阅读率的任务也可以通过apply()函数完成了。实际上Excel里面使用函数的各种操作,在pandas里面基本就可以用apply()函数完成了。
链接这篇文章对apply(),map(),applymap()函数的讲解就很不错。https://zhuanlan.zhihu.com/p/100064394?utm_source=wechat_session
我实现去掉数据里“人”字的代码
"""实现更改postnum列的149人这类数据为149,更改刷新到dataframe中。"""
def postnum_int(series):
postnum = series['postnum']
postnum_int = int(postnum[0:-1])
return postnum_int
df3['postnum'] = df3.apply(postnum_int, axis=1)
print(df3)
在这串代码中,我通过定义一个变换方法,然后用apply函数引用这种变换方法,按列刷新,把生成的数据改到原来那一列。
类似地,我生成了阅读率数据。
"""增加阅读率数据"""
def read_rate(series):
postnum = series['postnum']
readnum = series['readnum']
read_rate = readnum / postnum
return read_rate
df3['read_rate'] = df3.apply(read_rate, axis=1)
print(df3)
排序方式可以用sort_index()函数按序号排序,也可以用sort_values()函数按值排序。
我用两种排序方式生成了两个数据。
"""对dataframe按照postnum从小到大进行排序"""
df4 = df3.sort_values(axis=0, ascending=True, by='postnum')
print(df4)
"""对dataframe按照read_rate从小到大进行排序"""
df5 = df3.sort_values(axis=0, ascending=True, by='read_rate')
print(df5)
将数据传入matplotlib的绘图函数后发现,有的阅读率太高了,影响图的效果,于是决定删掉几个阅读率太高的数据,剔除掉三个阅读率高于1500%的数据。
用drop()函数进行删除某一行数据的操作。
"""删除某一行数据"""
df6 = df4.drop(df4[df4.read_rate > 15].index, inplace=False)
print(df6)
df7 = df5.drop(df5[df5.read_rate > 15].index, inplace=False)
print(df7)
matplotlib绘图
保存了一张png图片到文件夹。我在图中加了两条辅助线,一条红线代表阅读率8%,一条绿线代表阅读率50%。
"""使用matplotlib生成气泡图,按照postnum排序"""
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(df6['postnum'], df6['read_rate'], )
ax.set_xlabel('postnum')
ax.set_ylabel('read_rate')
plt.axhline(y=0.08, ls=":", c="red")
plt.axhline(y=0.5, ls=":", c="green")
plt.savefig('readrate1.png', dpi=750, bboxinches='tight')
plt.show()
从图中可见,阅读率普遍高于8%,也普遍高于50%。
按照思路二,将文章按阅读率从小到大排序,横轴为文章序号,纵轴为阅读率,更直观展现高于某一阅读率的文章比例。
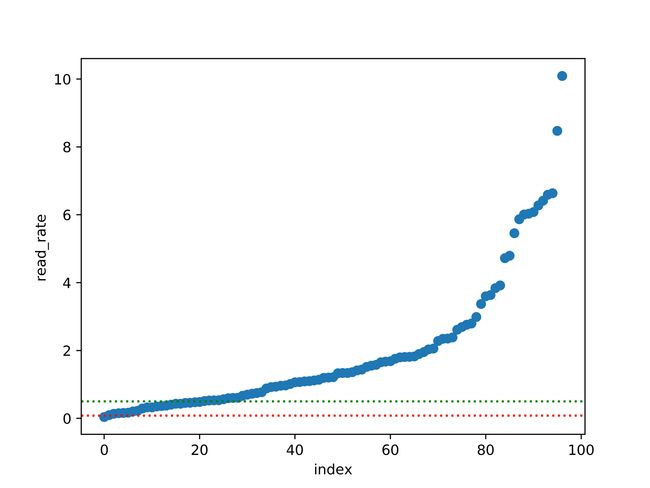
从图中可见,我有约80%的文章阅读率超过50%,有超过95%的文章阅读率超过8%,有约20%的文章阅读率超过400%。以下为这张图的代码实现。
df7['index'] = np.arange(len(df7))
df7为按阅读率排序后的数组,上面这一句的目的是生成一列index,按照每一条数据的行号输出编号。
"""用matplotlib生成散点图,横轴为文章序号"""
df7['index'] = np.arange(len(df7))
print(df7)
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(df7['index'], df7['read_rate'], )
ax.set_xlabel('index')
ax.set_ylabel('read_rate')
plt.axhline(y=0.08, ls=":", c="red")
plt.axhline(y=0.5, ls=":", c="green")
plt.savefig('readrate1.png', dpi=750, bboxinches='tight')
plt.show()
以上这个项目就完成了。
画图的几个包有matplotlib、seaborn、plotnine,还有pyecharts,有兴趣的可以体验下其他几个绘图包。