使用Python爬取招聘数据、数据处理与可视化
招聘数据爬取、数据处理与可视化
- 程序说明
- 数据爬取
-
- 观察网页结构
- 通过观察页面链接,爬取所有页面
- 爬虫程序完整代码
- 爬取数据结果
- 数据预处理
- 数据分析及可视化
-
- 全国计算机软件平均月薪和各市平均薪酬
- 上海各区计算机软件工作岗位数及平均薪酬
- 使用词云展示工作地点情况
- The end
程序说明
通过爬取“51job”获取招聘信息(以计算机软件为例),根据所获取数据分析领域相关工作职位需求,并通过可视化的方式展示分析行业就业情况(例如平均月薪、工作地点等)。
数据爬取
使用requests库请求网页内容,使用BeautifulSoup4解析网页。
观察网页结构
首先在爬取网页前,使用使用浏览器“开发者工具”,观察网页结构。

例如,使用下面语句查找标签为"t3"的"div"元素,其中内容即为工作地点,通过构建循环即可得到该页所有工作地点项。
i.find('span',class_='t3').get_text()
通过观察页面链接,爬取所有页面
查看第2页链接为:
https://search.51job.com/list/000000,000000,0000,01,9,99,%2B,2,2.html
第3页链接为:
https://search.51job.com/list/000000,000000,0000,01,9,99,%2B,2,3.html
仅改变了页面数字,因此可以构造如下模式,并使用循环,爬取所有页面:
url_pattern = "https://search.51job.com/list/000000,000000,0000,01,9,99,%2B,2,{}.html"
for i in range(1,2001):
url = url_pattern.format(i)
爬虫程序完整代码
import time
import requests
from bs4 import BeautifulSoup
import os
import csv
#构建请求头
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
url_pattern = "https://search.51job.com/list/000000,000000,0000,01,9,99,%2B,2,{}.html"
if not os.path.exists("intro_job.csv"):
#创建存储csv文件存储数据
file = open('intro_job.csv', "w", encoding="utf-8-sig",newline='')
csv_head = csv.writer(file)
#表头
header = ['job','company','place','salary','date','detail_url']
csv_head.writerow(header)
file.close()
for i in range(1,2001):
#增加时延防止反爬虫
time.sleep(5)
url = url_pattern.format(i)
response = requests.get(url=url, headers=headers)
#声明网页编码方式,需要根据具体网页响应情况
response.encoding = 'gbk'
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# 解析
for i in soup.find_all(lambda tag: tag.name=='div' and tag.get('class')==['el'])[4:]:
job = i.find('p',class_='t1').a['title']
company = i.find('span',class_='t2').a['title']
place = i.find('span',class_='t3').get_text()
salary = i.find('span',class_='t4').get_text()
date = i.find('span',class_='t5').get_text()
detail_url = i.find('p',class_='t1').a['href']
with open('intro_job.csv', 'a+', encoding='utf-8-sig') as f:
f.write(job + ',' + company + ',' + place + ',' + salary + ',' + date +',' + detail_url + '\n')
爬取数据结果
展示部分爬取结果:

数据预处理
数据预处理阶段主要为了去除不完整的数据,例如有些职务的薪资未明确标出,可以采用丢弃此条数据的方式,或者使用全局平均值之类的处理方法,这里采用直接丢弃的方法。
import pandas as pd
from matplotlib import pyplot as plt
import matplotlib.ticker as ticker
import numpy as np
import math
import re
#读取数据
df = pd.read_csv('intro_job.csv', encoding='utf-8-sig',usecols=["job", "company", "place", "salary", "date"])
#将相应字段数据保存至列表中
job_array = df['job'].values
company_array = df['company'].values
place_array = df['place'].values
salary_array = df['salary'].values
date_array = df['date'].values
#去除无效含有无效字段的数据,同时也需要去除其他列表中对应位置的数据
bool_array = np.ones_like(salary_array,dtype=np.bool)
for i in range(len(salary_array)):
if isinstance(salary_array[i],float):
bool_array[i] = False
print(len(job_array))
print(sum(bool_array))
job_array = job_array[bool_array]
print(len(job_array))
company_array = company_array[bool_array]
place_array = place_array[bool_array]
salary_array = salary_array[bool_array]
date_array = date_array[bool_array]
数据分析及可视化
薪资字段,由于计量的时间单位和数量级不同,有些采用年薪而另一些采用月薪或日薪甚至时薪,同时有一些单位为万元,有些单位为千元,因此需要统一单位,这里采用“千/月”作为单位。
而且由于薪资并非一个具体的值,而是一个范围区间,这里假设,在此区间内满足平均分布,因此取最高值和最低值的平均数。
#将工作地点转换成市,如"上海-浦东" => "上海"
place_array_city = []
for place in place_array:
if re.findall('-',place):
place_array_city.append(place[:place.find('-')])
else:
place_array_city.append(place)
def calc_money(salary_tmp):
if re.findall('千',salary_tmp):
salary_tmp=salary_tmp[:salary_tmp.find('千')]
elif re.findall('万',salary_tmp):
salary_tmp=salary_tmp[:salary_tmp.find('万')]
elif re.findall('元',salary_tmp):
salary_tmp=salary_tmp[:salary_tmp.find('元')]
if re.findall('-',salary_tmp):
salary_tmp = salary_tmp.split('-')
#print(salary_tmp)
return (float(salary_tmp[0]) + float(salary_tmp[1])) / 2
else:
return float(salary_tmp)
def calc_total(salary_tmp):
money = calc_money(salary_tmp)
if salary_tmp[-1] == '千':
money *= 1000
elif salary_tmp[-1] == '万':
money *= 10000
return money
def calc_mean(salary):
if re.findall('小时',salary):
salary_tmp = salary[:-3]
else:
salary_tmp = salary[:-2]
money = calc_total(salary_tmp)
if re.findall('年',salary):
money /= 12.0
elif re.findall('天',salary):
money *= 30
elif re.findall('小时',salary):
money = money * 8 * 20
return money
#计算平均月薪
salary_array_mean = []
for salary in salary_array:
money = calc_mean(salary)
salary_array_mean.append(money)
#城市中岗位数目字典,如"上海":1300,表示上海有1300个相关岗位
city_dict = {
}
#城市中岗位薪酬字典,如"上海":10000,表示上海计算机软件工作岗位总月薪为10000,除以对应城市岗位数即为该城市平均月薪
salary_dict = {
}
for i in range(len(place_array_city)):
if city_dict.get(place_array_city[i]):
city_dict[place_array_city[i]]+=1
salary_dict[place_array_city[i]] += salary_array_mean[i]
else:
city_dict[place_array_city[i]] = 1
salary_dict[place_array_city[i]] = salary_array_mean[i]
全国计算机软件平均月薪和各市平均薪酬
为了更清晰,仅展示招聘岗位数量在前20的城市。
#全国计算机软件平均月薪
mean_salary = sum(salary_array_mean)/len(salary_array_mean)
#字典排序
d_order=sorted(city_dict.items(),key=lambda x:x[1],reverse=True)
#前岗位数量前20平均月薪列表
mean_top_20 = []
#前岗位数量前20列表
city_top_20 = []
for i in d_order[:20]:
mean_top_20.append(salary_dict[i[0]]/i[1])
city_top_20.append(i[0])
ax = plt.axes()
labels = ax.get_xticklabels()
plt.plot(city_top_20,mean_top_20,marker='o',label='各市平均月薪')
plt.plot([mean_salary]*20,'--',label='全国平均月薪')
plt.setp(labels,rotation=30.)
plt.legend()
plt.rcParams['font.sans-serif'] = ['SimSun']
plt.show()

其他绘图方式类似不再展示源代码。
同样也可以统计计算机软件岗位平均月薪最高的20座城市,这个图很奇怪啊,我看了一下,全是同一个公司在全国各地开出来年薪50万+的工作,不知道什么情况,本来准备分析月薪最高的城市的各区情况,这一看还是算了,还是看一下上海吧。

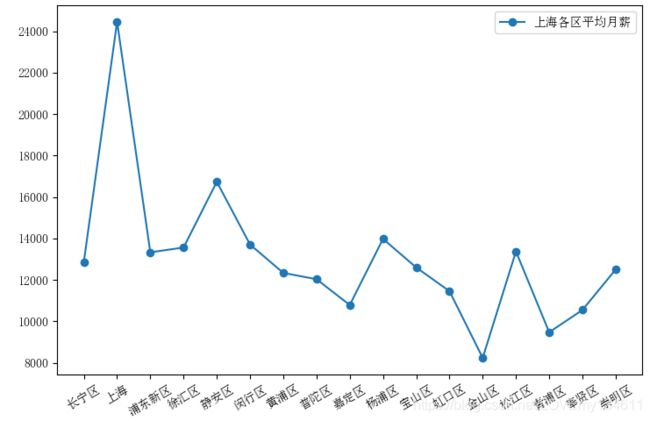
上海各区计算机软件工作岗位数及平均薪酬
上海各区计算机软件工作岗位数,其中上海是指未限定区的工作地点,而非整个上海总计算机岗位数。

上海各区计算机软件平均薪酬,这里上海仍是指未限定区的工作地点,而非整个上海总平均月薪。
使用词云展示工作地点情况
最后使用wordcloud库,绘制词云展示工作地点。
from os import path
from PIL import Image
import matplotlib.pyplot as plt
import jieba
from wordcloud import WordCloud, STOPWORDS
import pandas as pd
import matplotlib.ticker as ticker
import numpy as np
import math
import re
df = pd.read_csv('intro_job.csv', encoding='utf-8-sig',usecols=["job", "company", "place", "salary", "date"])
place_array = df['place'].values
place_list = ','.join(place_array)
with open('text.txt','a+') as f:
f.writelines(place_list)
###当前文件路径
d = path.dirname(__file__)
# Read the whole text.
file = open(path.join(d, 'text.txt')).read()
##进行分词
#停用词,去除异地招聘的
stopwords = ["异地","异地招聘","招聘"]
text_split = jieba.cut(file) # 未去掉停用词的分词结果 list类型
#去掉停用词的分词结果 list类型
text_split_no = []
for word in text_split:
if word not in stopwords:
text_split_no.append(word)
#print(text_split_no)
text =' '.join(text_split_no)
#背景图片
picture_mask = np.array(Image.open(path.join(d, "path.png")))
stopwords = set(STOPWORDS)
stopwords.add("said")
wc = WordCloud(
#设置字体,指定字体路径
font_path=r'C:\Windows\Fonts\simsun.ttc',
background_color="white",
max_words=2000,
mask=picture_mask,
stopwords=stopwords)
# 生成词云
wc.generate(text)
# 存储图片
wc.to_file(path.join(d, "result.jpg"))

The end
Enjoying coding!