Pandas数据处理_分组聚合_透视表交叉表
1.分组聚合
1.1拆分数据

groupby方法的参数及其说明:
#该方法提供的是分组聚合步骤中的拆分功能,
#能根据索引或字段对数据进行分组。其常用参数与使用格式如下:
DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True,
group_keys=True, squeeze=False, **kwargs)

groupby方法的参数及其说明——by参数的特别说明:
1、如果传入的是一个函数则对索引进行计算并分组。
2、如果传入的是一个字典或者Series则字典或者Series的值用来做分组依据。
3、如果传入一个NumPy数组则数据的元素作为分组依据。
4、如果传入的是字符串或者字符串列表则使用这些字符串所代表的字段作为分组依据。
GroupBy对象常用的描述性统计方法:
用 groupby 方法分组后的结果并不能直接查看,而是被存在内存中,输出的是内存地址。
实际上分组后的数据对 象GroupBy类似Series与DataFrame,是pandas提供的一种对象。GroupBy对象常用的描述性统计方法如下。

1.2 聚合数据
agg和aggregate函数参数及其说明:
agg,aggregate方法都支持对每个分组应用某函数,包括Python内置函数或自定义函数。同时这两个方法也能够直接对DataFrame进行函数应用操作。
在正常使用过程中,agg函数和aggregate函数对DataFrame对象操作时功能几乎完全相同,因此只需要 掌握其中一个函数即可。它们的参数说明如下表。
DataFrame.agg(func, axis=0, *args, **kwargs)
DataFrame.aggregate(func, axis=0, *args, **kwargs)

agg方法求统计量:
1、可以使用agg方法一次求出当前数据中所有菜品销量和售价的总和与均值,如:
detail[['counts','amounts']].agg([np.sum,np.mean]))
2、对于某个字段希望只做求均值操作,而对另一个字段则希望只做求和操作,可以使用字典的方式,
将两个 字段名分别作为key,然后将NumPy库的求和与求均值的函数分别作为value,如:
detail.agg({'counts':np.sum,'amounts':np.mean}))。
3、在某些时候还希望求出某个字段的多个统计量,某些字段则只需要求一个统计量,
此时只需要将字典对应 key 的 value 变为列表,列表元素为多个目标的统计量即可,如 :
detail.agg({'counts':np.sum,'amounts':[np.mean,np.sum]}))
agg方法与自定义的函数:
1、在agg方法可传入读者自定义的函数。
2、使用自定义函数需要注意的是NumPy库中的函数
np.mean,np.median,np.prod,np.sum,np.std,
np.var 能够在agg中直接使用,
但是在自定义函数中使用NumPy库中的这些函数,如果计算的时候是单 个序列则会无法得出想要的结果,
如果是多列数据同时计算则不会出现这种问题。
3、使用agg方法能够实现对每一个字段每一组使用相同的函数。
4、如果需要对不同的字段应用不同的函数,则可以和Dataframe中使用agg方法相同。
使用apply方法聚合数据:
1、apply方法类似agg方法能够将函数应用于每一列。
不同之处在于apply方法相比agg方法传入的函数只能够 作用于整个DataFrame或者Series,
而无法像agg一样能够对不同字段,应用不同函数获取不同结果。
2、使用apply方法对GroupBy对象进行聚合操作其方法和agg方法也相同,
只是使用agg方法能够实现对不同 的字段进行应用不同的函数,而apply则不行。
DataFrame.apply(func, axis=0, broadcast=False, raw=False, reduce=None, args=(), **kwds)

使用transform聚合数据:
1、transform方法能够对整个DataFrame的所有元素进行操作。
且transform方法只有一个参数“func”, 表示对DataFrame操作的函数。
2、同时transform方法还能够对DataFrame分组后的对象GroupBy进行操作,
可以实现组内离差标准化等操作。
3、若在计算离差标准化的时候结果中有NaN,这是由于根据离差标准化公式,
最大值和最小值相同的情况下 分母是0。而分母为0的数在Python中表示为NaN。
2.创建透视表与交叉表
2.1 使用pivot_table函数创建透视表
pivot_table函数常用参数及其说明:
利用pivot_table函数可以实现透视表,pivot_table()函数的常用参数及其使用格式如下。
pands.pivot_table(data, values=None, index=None, columns=None, aggfunc='mean',
fill_value=None, margins=False, dropna=True, margins_name='All')
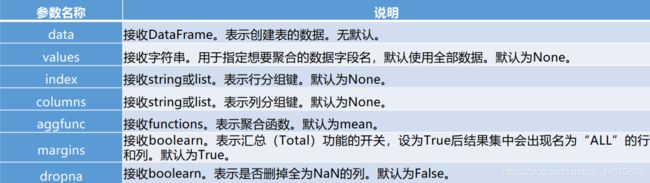
pivot_table函数主要的参数调节:
1、在不特殊指定聚合函数aggfunc时,会默认使用numpy.mean进行聚合运算,
numpy.mean会自动过滤 掉非数值类型数据。可以通过指定aggfunc参数修改聚合函数。
2、和groupby方法分组的时候相同,pivot_table函数在创建透视表的时候分组键index可以有多个。
3、通过设置columns参数可以指定列分组。
4、当全部数据列数很多时,若只想要显示某列,可以通过指定values参数来实现。
5、当某些数据不存在时,会自动填充NaN,因此可以指定fill_value参数,
表示当存在缺失值时,以指定数值进行填充。
6、可以更改margins参数,查看汇总数据。
2.2 使用crosstab函数创建交叉表
交叉表是一种特殊的透视表,主要用于计算分组频率。利用pandas提供的crosstab函数可以制作交叉表, crosstab函数的常用参数和使用格式如下:
由于交叉表是透视表的一种,其参数基本保持一致,不同之处在于crosstab函数中的index,columns, values填入的都是对应的从Dataframe中取出的某一列。
pandas.crosstab(index, columns, values=None, rownames=None, colnames=None,
aggfunc=None, margins=False, dropna=True, normalize=False)

3.章节实训





4.相关代码参考
示例1:分组聚合
import pandas as pd
import numpy as np
# 加载数据
# users = pd.read_excel("./users.xlsx")
# print("users:\n",users)
# print("users 列名称:\n",users.columns)
# 进行分组
# by 按照xxx进行分组
# 按照单一列进行分组
# res = users.groupby(by='sex')['age'].describe()
# res = users.groupby(by='arithmetic_name')['sex'].count() # 统计分组之后组内的非空数量
# 按照多列进行分组
# 按照多列进行分组
# res = users.groupby(by=['sex','poo'])['age'].max()
# 按进行照多列进行分组、统计多个列的指标---数值型
# res = users.groupby(by=['sex','poo'])['age','ORGANIZE_ID'].max()
# res = users.groupby(by=['sex','poo'])['age','ORGANIZE_NAME'].min()
# print(res)
# 加载数据
# detail = pd.read_excel("./meal_order_detail.xlsx")
# print("detail:\n",detail)
# print("detail 列名称:\n",detail.columns)
# 对多列 统计多个指标
# res = detail.loc[:,['amounts','counts']].agg([np.mean,np.max])
# 对 多列统计 不同指标
# res = detail.agg({'amounts':np.mean,'counts':np.max})
# 对不同的列 求取不同个数的不同指标
# res = detail.agg({'amounts':np.mean,'counts':[np.max,np.min]})
#
#
# print(res)
# 自定义函数
# res = detail['amounts'].apply(lambda x:x+1)
# res = detail['amounts'].transform(lambda x:x+1)
# 对 多列统计 不同指标---可以统计自己定义的内容
# def hh(x):
# return x+1
#
# res = detail.agg({'amounts':hh,'counts':np.max})
#
# print(res)
# 也可以对分组聚合进行统计自己指定 内容
# res = users.groupby(by='sex')['age'].apply(lambda x:x+1)
#
# print(res)
# 需要注意:这里自定义函数 只能进行单列的数据统计或者运算,不能跨列进行运算或者统计
示例2:透视表
import pandas as pd
# 加载数据
detail = pd.read_excel("./meal_order_detail.xlsx")
print("detail:\n",detail)
print("detail 的列名称:\n", detail.columns)
# 可以计算每个菜 支付了多少钱
# 单价 * 数量
detail.loc[:,'pay'] = detail.loc[:,'counts'] * detail.loc[:,'amounts']
# 获取日期数据
# 现将数据转化为pandas默认支持的时间序列数据
detail.loc[:,'place_order_time'] = pd.to_datetime(detail.loc[:,'place_order_time'])
# 获取时间序列的日属性
detail['day'] = [i.day for i in detail.loc[:,'place_order_time']]
# 创建透视表
# data 传入的数据,df
# index 行分组
# values 要关心的列,即统计的主体
# aggfunc 统计的指标
res = pd.pivot_table(detail[['counts','amounts','dishes_name','order_id','dishes_id','day','pay']],
index='day',
values='pay',
aggfunc='sum')
#
# res = detail.groupby(by='day')['pay'].sum()
# 既可以指定行分组 也可以指定列分组
# res = pd.pivot_table(detail[['counts', 'amounts', 'dishes_name', 'order_id', 'dishes_id']],
# index='dishes_name',
# columns='order_id',
# values='amounts',
# aggfunc='sum')
# fill_value 填充
# dropna 删除所有为空的列
# res = pd.pivot_table(detail[['counts', 'amounts', 'dishes_name', 'order_id', 'dishes_id']],
# index=['order_id','dishes_name'],
# columns='counts',
# values=['amounts','dishes_id'],
# aggfunc='sum',
# # fill_value=0,
# # dropna=True,
# margins=True)
# 保存袋excele里面
# res.to_excel("./res.xlsx")
print(res)
示例3:交叉表
import pandas as pd
import numpy as np
#加载数据
detail = pd.read_excel("./meal_order_detail.xlsx")
print("detail:\n",detail)
print("detail 的列名称:\n", detail.columns)
# 创建交叉表 ----统计行 跟列的个数关系
# res = pd.crosstab(index=detail['counts'],columns=detail['amounts'])
# 注意:values 和 aggfunc 必须同时存在
res = pd.crosstab(index=detail['counts'],columns=detail['amounts'],
values=detail['order_id'],
aggfunc=np.max)
print(res)
示例4:连锁超市案例
import pandas as pd
# 加载数据
order = pd.read_csv("./order-14.3.csv", encoding='gbk')
print("order:\n", order)
print("order列名:\n", order.columns)
# 1、哪些类别的商品比较畅销?
# 剔除 销量 <=0 的行
# 保留销量 >0 的行
bool_id = order.loc[:, '销量'] > 0
data = order.loc[bool_id, :]
# 对类别进行分组,统计销量之和,再 排序
# sort_values ---对df按照值进行排序
# sort_values 里面有个by参数,按照某列进行排序,默认升序 ascending=False变为降序
# res1 = data.groupby(by='类别ID')['销量'].sum().sort_values(ascending=False)
# print(res1)
# 2、哪些商品比较畅销?
# 一 、分组聚合
# res2 = data.groupby(by='商品ID')['销量'].sum().sort_values(ascending=False).head(10)
# 二、透视表
# res2 = pd.pivot_table(data,index='商品ID',values='销量',aggfunc=sum).sort_values(by='销量',ascending=False).head(10)
# print(res2)
# print(type(res2))
# 3、求不同门店的销售额占比
# # 先计算单个商品的销售额
# data.loc[:,'销售额'] = data.loc[:,'销量'] * data.loc[:,'单价']
# # 在进行 按照门店标号进行分组 、统计销售额之和
# res3 = data.groupby(by='门店编号')['销售额'].sum()
# # print(res3)
# # 在计算总销售额
# all_comment =res3.sum()
#
# # print(all_comment)
#
# # 占比 门店销售额之和 /总销售额
# print('占比:', (res3/all_comment).apply(lambda x:format(x,'.2%')))
# 4、哪段时间段是超市的客流高峰期?
# 先对订单ID 进行去重
data.drop_duplicates(subset='订单ID', inplace=True)
# 可以按小时进行分组,统计订单个数
data.loc[:, '成交时间'] = pd.to_datetime(data.loc[:, '成交时间'])
# 获取小时属性
data.loc[:,'hour'] = [i.hour for i in data.loc[:, '成交时间']]
#
# res4 = data.groupby(by='hour')['订单ID'].count().sort_values(ascending=False).head(3).index
# print(res4)
# 早上 9 10 8 点客流最多,预测此时都是进行买菜的用户
# 拓展 按照行索引进行排序 sort_index()
# res4 = data.groupby(by='hour')['订单ID'].count().sort_values(ascending=False).sort_index(ascending=False)
# print(res4)