TensorFlow之目标检测API接口调试(超详细)
注意:本文下载的tensoflow/model版本比较旧,是18年的版本,现在github上有更新,对代码和文件结构进行了一定的优化,因此下文的流程使用起来可能会与最新版本有所差异,大家要根据官方介绍灵活设置
1 源代码测试
1.1 环境配置
环境:tensorflow-gpu:1.9(注意要选择1.9的版本,测试过1.7版本的在最后一步模型转化时会有问题),python3.6
下载github上的code
git clone https://github.com/tensorflow/models.git如果觉得下载速度太慢,可以参考《用了这个方法,我下载GitHub项目速度达5MB/s!》介绍的方法来提高下载速度
因为models里边的项目很多都用protobuf来配置,所以需要在research目录下进行protobuf编译。先更新一下电脑上的protoc版本,一定要下载3.4.0的版本,其它版本试过都报错。首先运行 protoc --version检测自己的版本,如果不是3.4.0,就到官网下载3.4.0 python版本
![]()
下载完后解压,进入目录,然后执行:
sudo ./configure
sudo make check
sudo make install安装完后,运行 protoc --version检查版本是否正确,如果运行时报错报错:protoc: error while loading shared libraries: libprotoc.so.9: cannot open shared object file: No such file or directory
则先把/usr/local/lib追加到LD_LIBRARY_PATH环境变量中
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/lib然后进入tf的reserch目录,依次执行如下指令
protoc object_detection/protos/*.proto --python_out=.
export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim上述指令的意思分别是在protos文件夹中根据proto文件生成python源码文件,以及把research及research目录下的slim位置追加到python路径的环境变量中(pwd表示当前目录),正常运行是没有任何输出的,为了重启后也可以正常使用,可以把路径写在.bashrc文件中,并source一下
如果是用apt安装的protoc,默认装的是2.6.1的版本,运行protoc指令时会报错如下,因此需要用上边的方法下载源码安装
object_detection/protos/ssd.proto:104:3: Expected "required", "optional", or "repeated".
object_detection/protos/ssd.proto:104:12: Expected field name.
object_detection/protos/model.proto: Import "object_detection/protos/ssd.proto" was not found or had errors.
object_detection/protos/model.proto:12:5: "Ssd" is not defined.
配置完毕后,可以运行python object_detection/builders/model_builder_test.py,当输出OK时表明配置成功,可以进行后续操作。
1.2 测试模型
从models/object_detection目录中运行jupyter notebook打开Jupyter 笔记本(安装方法)。从这里选择object_detection_tutorial.ipynb。 从这里,你应该能在主菜单中运行单元格,并选择全部运行。你应该得到以下结果:
如果要检测自己的图片,一种方法是在test_image文件夹下放自己的图片,并重新命名为image*.jpg的格式;另一种方法是修改TEST_IMAGE_PATH为自己的图片路径就可以了
1.3 使用其它模型做检测
一共公布了5个模型,上面我们只是用最简单的ssd + mobilenet模型做了检测,如何使用其他模型呢?找到Tensorflow detection model zoo,根据里面模型的下载地址,我们只要分别把MODEL_NAME修改为以下的值,就可以下载并执行对应的模型了(训练时要下载修改对应的配置文件)
预训练的模型包括四个数据集的模型:COCO 数据集(微软开源的数据集)、 Kitti数据集(自动驾驶场景)、Open Images数据集(谷歌开源的数据集)、AVA v2.1数据集(人类动作识别数据集)
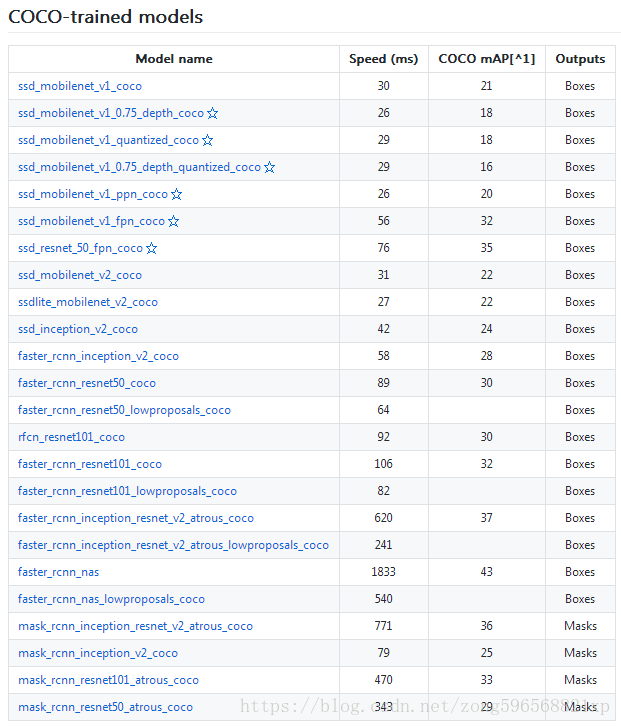
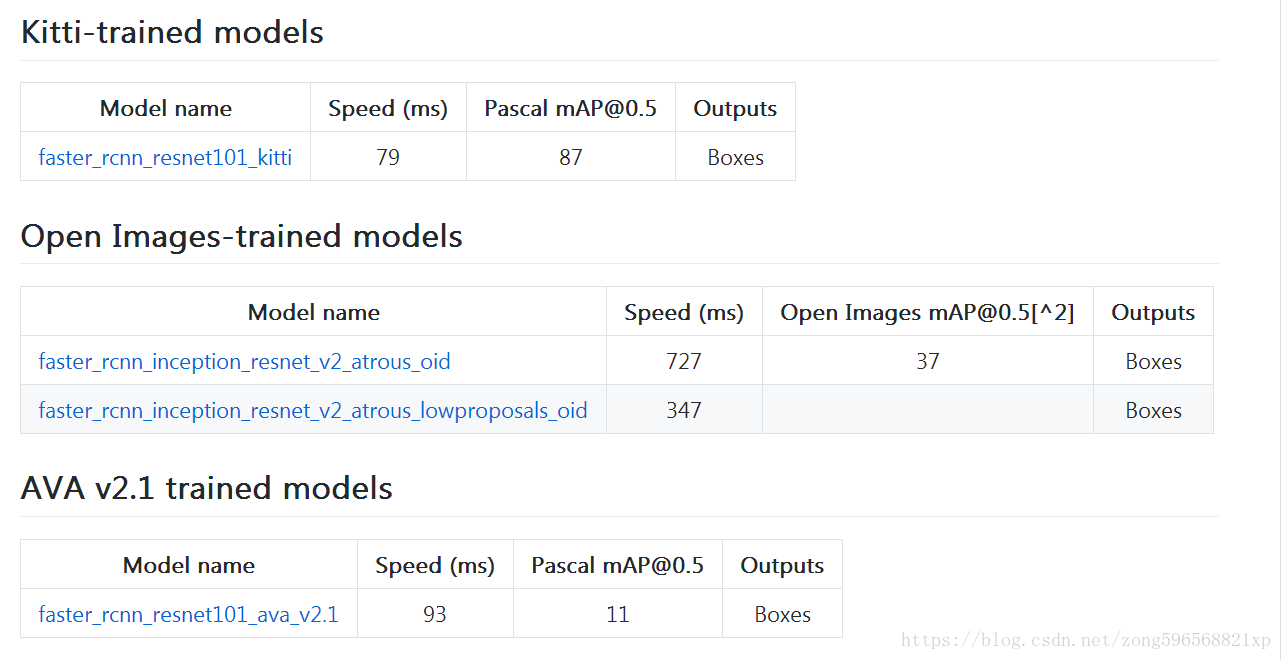
(可通过speed和mAP指标来选择适合自己场景的模型,如果追求精度又不失速度的情况下,带有 Inception Resnet v2 的 Faster RCNN 对小目标的检测效果非常不错)
2 准备自己的训练数据
2.1 整体流程
首先介绍一下步骤顺序:
- 收集几百个包含你的对象的图像 - 最低限度是大约 100,理想情况下是 500+
- 注释/标注你的图像,可以使用 LabelImg。 这个过程基本上是,在你图像的对象周围画框。 标注程序会自动创建一个描述图片中的对象的 XML 文件。
- 将这些数据分解成训练/测试样本
- 从这些分割生成tfrecord
- 为所选模型设置
.config文件(你可以从头自己开始训练,但是我们将使用迁移学习) - 训练
- 从新的训练模型导出图形
- 实时检测自定义对象!
- ...
- 完成!
2.2 标注数据
对于本教程,你可以跟踪任何你想要的东西,只需要 100 多张图片。 一旦你有图像,你需要标注它们。 可以使用 LabelImg,具体安装及使用方法参考之前的文章,标注完之后每张图片都对应一个XML的标注文件,与PASCAL VOC以及ImageNet用的XML是一样的。一旦你标记了超过 100 张图片,就需要将把他们分成训练和测试组。 为此,只需将你的图像和注解 XML 文件的约 10% 复制到一个称为test的新目录,然后将其余的复制到一个叫做train的新目录。
在object_detection文件夹下,新建一个文件夹叫images,然后把之前创建的test文件夹和train文件夹放进去。同时,需要把test文件夹和train文件夹里的图片及标注文件全部复制到images文件夹下。如果有不清楚的,请参考这个数据集。
下一步就要将这些XML文件转换为所需的 TFRecord 文件。
2.3 转换格式
首先下载转换所需的代码,我们只用到了其中的两个文件,一个是xml_to_csv.py,另一个是generate_tfrecord.py,将这两个文件都放入object_detection文件夹下。
在object_detection文件夹下,新建一个data文件夹,用来存放生成的csv文件和record文件
首先运行 python xml_to_csv.py,结果输出两个Successfully converted xml to csv.则正常,可进入data文件夹查看是否生成train_labels.csv和test_labels.csv
注意:下边的修改不是必须,如果没有对原数据做扩充等操作就没必要修改
在xml_to_csv.py文件中,默认读取文件名字是从xml中的filename进行读取,这样存在的一个问题是,如果手动进行数据扩充,没有更改xml中的filename时,会导致图片对应错误,因此,建议修改为从xml文件的名字上进行获取filename,修改方法很简单,有两处修改:
- 首先是在for xml_file in glob.glob()函数下边加一句 xml_name = xml_file.split(path + '/', 1)[1]
- 然后将value = (root.find('filename').text,……)改为value = (xml_name.split('.xml',1)[0] + '.jpg',……)即可
然后打开generate_tfrecord.py文件,找到class_text_to_int函数,将类别写进row_label中,如果有很多个类别,就继续构建这个if语句。比如
# TO-DO replace this with label map
def class_text_to_int(row_label):
if row_label == 'car':
return 1
elif row_label == 'person':
return 2
else:
return 0
注意要将最后的else语句中的None改为 return 0 ,否则运行下边两条指令时会报如下的错
TypeError: None has type NoneType, but expected one of: int, long
依次运行以下两条指令
python3 generate_tfrecord.py --csv_input=data/train_labels.csv --output_path=data/train.record
python3 generate_tfrecord.py --csv_input=data/test_labels.csv --output_path=data/test.record结果输出Successfully created the TFRecords: ……则正常,至此,数据构建完成
运行如果报错如下
OSError: cannot identify image file <_io.BytesIO object at 0x7f26116c1ba0>则是因为图片有损坏,一张一张查,删除掉坏了的图片即可,然后重新生成csv和tfrecords文件
3 修改配置文件
3.1 预训练模型
在训练的时候,我们有两个选择。我们可以使用预训练的模型,然后使用迁移学习来习得一个新的对象,或者我们可以从头开始习得新的对象。迁移学习的好处是训练可能更快,你需要的数据可能少得多。出于这个原因,我们将在这里执行迁移学习。
TensorFlow 有相当多的预训练模型,带有检查点文件和配置文件。如果你喜欢,可以自己完成所有这些工作,查看他们的配置作业文档。配置文件位于object_detection/samples/configs文件夹下。我打算使用 mobilenet,在object_detection文件夹下,下载预训练模型并解压:
wget http://download.tensorflow.org/models/object_detection/ssd_mobilenet_v1_coco_11_06_2017.tar.gz
tar -xzvf ssd_mobilenet_v1_coco_11_06_2017.tar.gz3.2 标签文件
cd进data文件夹,新建object-detection.pbtxt 打开一个空文件,在文件里写入识别的种类,格式如下
item {
id: 1
name: 'macncheese'
}
item {
id: 2
name: 'milk'
}3.3 配置文件
注意我们这里的预训练模型是在coco数据集上训练的,配置文件要与预训练模型对应,拷贝samples/config文件夹下的ssd_mobilenet_v1_coco.config文件并进行修改,主要有三个地方:1.训练类别数更改;2.验证阶段图片数量(视具体情况);3.训练,验证,标签路径更改;(其它配置文件的修改方法类似,也基本上是改这几处位置)
- num_classes:12 #看到有地方说要设置实际种类数+1,这块还需要再确认一下
- fine_tune_checkpoint:"ssd_mobilenet_v1_coco_11_06_2017/model.ckpt"
- num_steps:30000 #训练步数设置,根据自己数据量来设置,默认为200000
- train_input_reader/input_path:"data/train.record"
- train_input_reader/label_map_path:"data/object-detection.pbtxt"
- num_examples:78(测试集图片数)
- num_visualizations:78(测试时显示的图片数,默认为10张)
- #max_evals:10(注释掉)
- eval_input_reader/inputpath:"data/test.record"
- eval_input_reader/label_map_path: "data/object-detection.pbtxt"
修改完后保存退出
4 开始训练
首先在legacy文件夹中复制一份train.py到object_detection文件夹下,然后运行以下指令
python train.py --logtostderr --train_dir=training/ --pipeline_config_path=ssd_mobilenet_v1_pets.config注意训练开始之前,首先检查training文件夹中除了配置文件是否有之间存留的模型,如果有种类的调整,或者想从头开始训练,需要删除掉多余文件,只保留object-detection.pbtxt即可,否则会报下边的错误:
InvalidArgumentError (see above for traceback): Assign requires shapes of both tensors to match. lhs shape= [39] rhs shape= [6]还有在配置参数中不要出现空格,否则会报下边的错误:
tensorflow.python.framework.errors_impl.NotFoundError: ; No such file or directory
如果更换模型以及更换配置文件后,出现ValueError: No variables to save的错误,则在配置文件中添加from_detection_checkpoint: true,比如说,我选择ssd_resnet50_v1_fpn_shared_box_predictor_640x640_coco14_sync_2018_07_03的模型,并在samples/configs中找到ssd_resnet50_v1_fpn_shared_box_predictor_640x640_coco14_sync.config配置文件,打开后并没有找到from_detection_checkpoint选项,需要在train_config中手动添加:
train_config: {
fine_tune_checkpoint: "ssd_resnet50_v1_fpn_shared_box_predictor_640x640_coco14_sync_2018_07_03/model.ckpt"
from_detection_checkpoint:true
batch_size: 64
……
}然后再开始训练,如果都正确的话,就会开始训练,会有如下的输出:
……
INFO:tensorflow:global step 16360: loss = 1.6747 (0.165 sec/step)
INFO:tensorflow:global step 16361: loss = 2.3805 (0.193 sec/step)
INFO:tensorflow:global step 16362: loss = 0.8742 (0.152 sec/step)
INFO:tensorflow:global step 16363: loss = 0.7009 (0.151 sec/step)
INFO:tensorflow:global step 16364: loss = 0.5231 (0.197 sec/step)
……训练的过程中,会在training文件夹中输出新文件,
其中model.ckpt是每隔一定时间,会保存模型,且只保存最近的5个模型权重。checkpoint文件中记录了最新的5个权重信息,events开头文件可在tensorboard中查看训练记录,pipeline.config和第5步中的配置文件一样。graph.pbtxt图表信息
可以通过tensorboard来查看,在object_detection文件夹中输入:tensorboard --logdir='training',默认占用6006端口,然后在浏览器中输入ip和端口号即可打开tensorboard,如果是本机的话,在浏览器中输入 127.0.0.1:6006即可(训练过程中可实时查看数据的变化情况)。
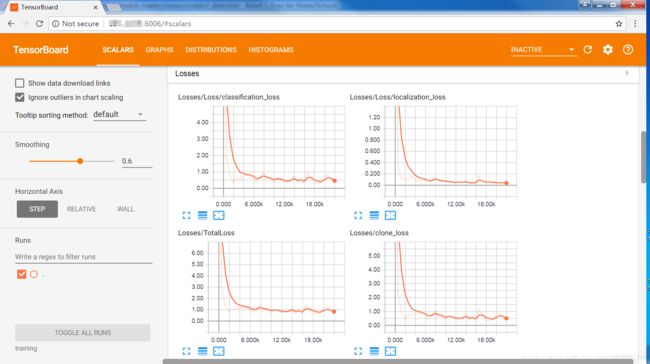
可以看到loss逐渐下降,达到一个较好的训练状态
训练的时候,可以同时运行eval.py来监视测试的情况,具体方法参考《Tensorflow之eval.py使用方法》
5 测试模型
5.1 模型转化
训练过程中,会在training文件夹中生成一些检查点文件,我们需要把这些文件转化为pb文件,这样才可以拿该模型进行实时测试识别
在object_detection文件夹下,有一个export_inference_graph.py文件可以帮助我们实现该功能。运行它时,只需要传入检查点文件和配置文件,以及输出文件的位置,例如:
python export_inference_graph.py --input_type image_tensor --pipeline_config_path ssd_mobilenet_v1_pets.config --trained_checkpoint_prefix training/model.ckpt-279099 --output_directory mac_n_cheese_inference_graph/其中,在--trained_checkpoint_prefix参数中输入的是检查点文件,可以选择要转化哪一个,输出目录是mac_n_cheese_inference_graph,当然也可以定义为其它目录,只需要和后边路径保持一致即可。
运行完后,会在mac_n_cheese_inference_graph文件夹下生成目标文件forzen_inference_graph.pb文件,我们之后用该模型进行识别
5.2 测试验证
首先在测试集(object_detection/images/test)中选几张图片复制到object_detection/test_images文件夹中,并重命名为image3.jpg、image4.jpg……然后在object_detection文件夹中运行jupyter notebook,打开object_dection_tutorial.ipynb,接下来做几处修改
首先修改模型名称以及对应的路径
# What model to download.
MODEL_NAME = 'mac_n_cheese_inference_graph'
# Path to frozen detection graph. This is the actual model that is used for the object detection.
PATH_TO_CKPT = MODEL_NAME + '/frozen_inference_graph.pb'
# List of the strings that is used to add correct label for each box.
PATH_TO_LABELS = os.path.join('training', 'object-detection.pbtxt')
NUM_CLASSES = 1然后,可以把整个下载模型的cell删除掉,因为不需要再下载模型了
最后,在检测部分,将TEST_IMAGE_PATHS变量更改为:
TEST_IMAGE_PATHS = [ os.path.join(PATH_TO_TEST_IMAGES_DIR, 'image{}.jpg'.format(i)) for i in range(3, 8) ]后边的range(3,8)看自己实际有几张测试图片,比如有两张,改为(3,5)即可
改完之后,点击cell、run all,即可得到结果,如图所示
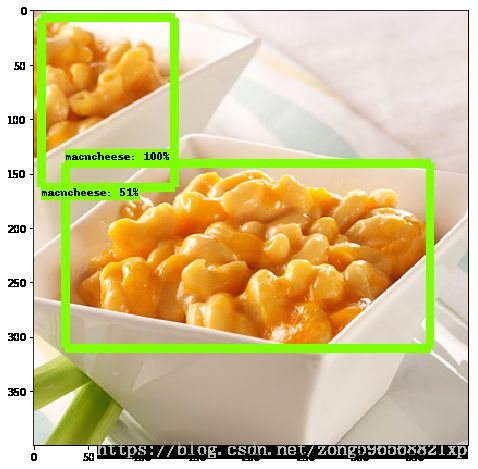

由图可知,经过一些训练,模型可正确识别到待检测的目标,表明模型的有效性。至此,完成了tensorflow目标检测API的全部调用,如有问题,欢迎大家留言讨论!