使用webmagic爬取网站数据
爬取网站的技术很多,我是使用java来写,经过对比还是选择了webmagic来实现。原因就是方便,简单。
文档:webmagic中文文档
源码地址:https://github.com/code4craft/webmagic
文档和代码中的例子都比较简单易懂,几分钟就可以进行网站的爬取和分析了。
这里简单介绍下穷游网的数据抓取(只介绍思路和主要代码,具体代码就不粘贴了,如有需要可留言)
一、需求
抓取穷游网所有poi的详情页面。
举例:https://place.qyer.com/poi/V2EJalFnBzRTbQ/
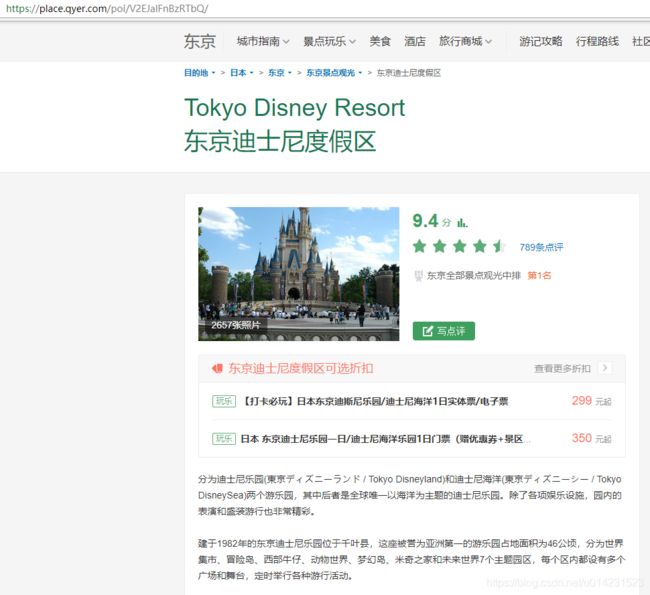
二、思路分析
如果需要所有的poi页面,我们就要知道这个页面的路径,从上面的导航栏可以看出:目的地> 日本 >东京>东京景点观光>东京迪士尼度假区。
-
路径是:国家>城市>旅行地>景点>地点
那么我们的抓取的顺序就需要按照这个路径去抓取。 -
知道路径后,我们就要去分析,页面上的数据是通过get请求能够得到还是需要通过post请求能够得到。如果是get请求,我们就需要知道请求的url。如果是post请求,就需要分析请求的入参有哪些,入参的含义以及如何拿到这些入参。
分析后发现:- 国家页面是get请求。所有国家都在首页:https://place.qyer.com/
- 热门城市也是get请求。链接如:https://place.qyer.com/japan/citylist-0-0-1/
这里url中包含国家的编码值,可在上一步获取到 - 旅行地的景点列表则是post请求。可以在https://place.qyer.com/tokyo/sight/中 的请求页面上点击下一页查看
通过post请求获取返回列表中的值 - 通过上一步返回列表中的值知道每个地点的详情页面url
-
我们拿到这些详情页面的url后,然后进行get请求就可以得到html页面了,可以下载下来也可以直接解析出需要的元素。
-
上面几步涉及到一个问题,就是如何保存这些url和入参呢,我们可以使用数据库进行持久化,通过数据库不仅可以进行数据的保存,还可以区分哪些url已经爬取过了,哪些页面没有爬取过。
如下:

三、操作步骤
- 抓取所有国家
- 根据国家抓取所有热门城市
- 生成城市旅行地的url
旅行包括:- sight 景点、32
- food美食、78
- shopping购物、147
- activity活动、148
- 抓取每个旅行地类别的总页数( 旅行地请求是post分页请求)
- 通过post分页请求获取旅行地(景点/美食/购物/活动)的返回结果(返回列表中包含poi的详情链接)
- 根据旅行地的详情url抓取页面html,下载html到本地(下载到本地可以反复解析)
- 解析旅行地的各个页面
获取景点列表的请求链接举例:https://place.qyer.com/poi.php?action=list_json&page=2&type=city&pid=63&sort=32&subsort=all&isnominate=-1&haslastm=false&rank=6
参数分析:
- action=list_json 不变
- type=city 不变
- page:页码,从1开始
- pid:城市id
- sort:分类id—全部:0,景点:32,美食:78,购物:147,活动:148
- subsort:子类id
五、主要代码
- 获取国家url,以及持久化到数据库。(城市类似,就省略了)
@Component
public class CountryPageProcessor implements PageProcessor{
private Site site = Site.me()
.setDomain("place.qyer.com")
.setSleepTime(1000)
.setUserAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36");
@Override
public void process(Page page) {
List list = page.getHtml().xpath("//div[@class='place-home-card4']//a").nodes();
List countryList = Lists.newArrayList();
for(Selectable selectable :list) {
Selectable urlsele = selectable.xpath("//a/@href");
Selectable namesele = selectable.xpath("//a//span/text()");
Selectable nameEnsele = selectable.xpath("//a//em/text()");
if(null != urlsele && null != namesele && null != nameEnsele) {
String url = urlsele.toString();
String name = namesele.toString().trim();
String nameEn = nameEnsele.toString().trim();
String code = url.split("/")[3];
QyCity country = new QyCity();
country.setCode(code);
country.setNameEn(nameEn);;
country.setName(name);
country.setUrl(url);
countryList.add(country);
}
}
page.putField("countryList", countryList);
}
@Override
public Site getSite() {
return site;
}
/*public static void main(String[] args) {
String url = "https://place.qyer.com";
Spider.create(new CountryPageProcessor())
.addUrl(url)
.addPipeline(new ConsolePipeline())
.addPipeline(new CountryPipeline())
.run();
}*/
}
@Component
public class CountryPipeline implements Pipeline{
@Override
public void process(ResultItems resultItems, Task task) {
List list = resultItems.get("countryList");
if(CollectionUtils.isNotEmpty(list)) {
//保存到数据库
}
}
}
- 旅行地景点
@Component
public class CityTravelPageProcessor implements PageProcessor{
private Site site = Site.me()
.setDomain("place.qyer.com")
.setSleepTime(1000)
.setRetryTimes(3)
.setTimeOut(30000)
.setUserAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36");
@Override
public void process(Page page) {
List list = new JsonPathSelector("$.data.list").selectList(page.getRawText());
List poList = Lists.newArrayList();
for(String json : list) {
Map map = JsonHelper.json2Bean(json, Map.class);
CrawlerTravelDetailPO po = new CrawlerTravelDetailPO();
po.setCnname(null != map.get("cnname") ? map.get("cnname").toString() : "");
po.setRefId(null != map.get("id") ? Long.parseLong(map.get("id").toString()) : 0);
po.setEnname(null != map.get("enname") ? map.get("enname").toString() : "");
po.setGrade(null != map.get("grade") ? map.get("grade").toString() : "");
po.setRank(null != map.get("rank") ? Integer.parseInt(map.get("rank").toString()) : null);
po.setCommentCount(null != map.get("commentCount") ? Integer.parseInt(map.get("commentCount").toString()) : null);
po.setUrl(null != map.get("url") ? map.get("url").toString() : "");
po.setStatus(0);
poList.add(po);
}
page.putField("list", poList);
}
@Override
public Site getSite() {
return site;
}
public static void main(String[] args) {
String url = "https://place.qyer.com/poi.php";
Map paraMap = Maps.newHashMap();
paraMap.put("action", "list_json");
paraMap.put("type", "city");
paraMap.put("page", 1);
paraMap.put("pid", 50);
paraMap.put("sort", 32);
Request request = new Request();
request.setUrl(url);
request.setRequestBody(HttpRequestBody.form(paraMap, "UTF-8"));
request.setMethod(HttpConstant.Method.POST);
Spider.create(new CityTravelPageProcessor())
.addRequest(request)
.addPipeline(new ConsolePipeline())
.run();
}
}
@Component
public class CityTravelPipeline implements Pipeline{
@Resource
private CrawlerTravelDetailMapper crawlerTravelDetailMapper;
@Override
public void process(ResultItems resultItems, Task task) {
List list = resultItems.get("list");
if(CollectionUtils.isNotEmpty(list)) {
//保存到数据库
}
}
}
3.下载html
@Component
public class CityGuideDownPageProcessor implements PageProcessor{
private Site site = Site.me()
.setDomain("place.qyer.com")
.setSleepTime(3000)
.setCycleRetryTimes(3)
.setRetryTimes(3)
.setUserAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36");
@Override
public void process(Page page) {
Html html = page.getHtml();
if(null != html) {
page.putField(QyerConstant.HTML, page.getHtml());
}
}
@Override
public Site getSite() {
return site;
}
public static void main(String[] args) {
String url = "https://place.qyer.com/poi/V2wJYFFnBzVTZA/";
Spider.create(new CityGuideDownPageProcessor())
.addUrl(url)
.addPipeline(new ConsolePipeline())
.addPipeline(new FilePipeline("E:\\travel\\"))
.run();
}
}
- 解析
解析html,可以使用jsoup或者使用Xsoup,很方便就能够解析出html文件的内容。
File in = new File("E:\\travel\\" + fileName);
if(null != in && in.exists()) {
Document doc;
try {
doc = Jsoup.parse(in, "UTF-8", "");
//解析排名,图片和简介
String rankDesc = doc.select("div.poi-placeinfo>div.infos>div>ul>li.rank").text();
String photoSrc = doc.select("div.poi-placeinfo>a>p.coverphoto>img").attr("src");
String summary = doc.select("div.compo-detail-info>div.poi-detail>div>p").text();
} catch (IOException e) {
logger.error("解析报错:id= {}, {}", po.getId(), e);
}
}
以上是穷游爬取的简要逻辑,这里使用数据库进行持久化。主要避免以下几个问题:
- url的管理(防止重复下载以及多线程进行爬取),如果数据量小可以使用webmagic提供的几个Scheduler
- url下载过程中可能连接超时或者拒绝连接,通过数据库的执行状态可以自动再次爬取,不用人为排查介入
- url爬取过程如果中断,可以通过状态很方便判断哪些没有爬取哪些已经爬取