转载:矩阵分解
@TOC
前言
本文章,适合零基础学习MF(个人认为)数据集很小,只是简单但详细的讲解了矩阵分解,并给出了一个简单的代码,如果觉得对你有用,清点一下关注,谢谢
推荐系统中最为主流与经典的技术之一是协同过滤技术(Collaborative Filtering),它是基于这样的假设:用户如果在过去对某些项目产生过兴趣,那么将来他很可能依然对其保持热忱。其中协同过滤技术又可根据是否采用了机器学习思想建模的不同划分为基于内存的协同过滤(Memory-based CF)与基于模型的协同过滤技术(Model-based CF)。其中基于模型的协同过滤技术中尤为矩阵分解(Matrix Factorization)技术最为普遍和流行,因为它的可扩展性极好并且易于实现,接下来我们将讨论矩阵分解,即其代码实现
矩阵分解
我们都熟知在一些软件中常常有评分系统,但并不是所有的用户user人都会对项目item进行评分,因此评分系统所收集到的用户评分信息必然是不完整的矩阵。那如何跟据这个不完整矩阵中已有的评分来预测未知评分呢。使用矩阵分解的思想很好地解决了这一问题。
假如我们现在有一个用户-项目的评分矩阵R(n,m)是n行m列的矩阵,n表示user个数,m行表示item的个数
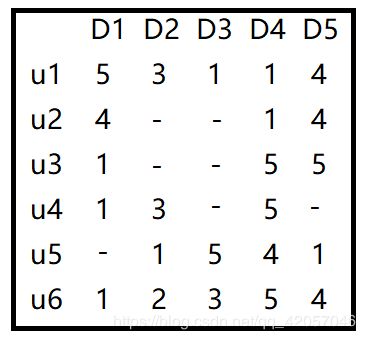
我们可以看出R矩阵是一个稀疏矩阵,在实际场景中,对于庞大的评分系统来说,每一歌用户所对用的项目是极小的。而R在实际场景中是一个极大地矩阵。
我们如何根据目前的矩阵R(5,4)对未打分的商品进行评分的预测呢(如何得到分钟为-或0的用户的分值?)
矩阵分解的思想很好的解决了这个问题,矩阵分解可以看做有监督的机器学习问题(回归问题)
矩阵R可以近似的表示为P和Q矩阵的乘积。
R可以分解为如下两个矩阵P(即nP)Q(即nQ),

预测矩阵
将矩阵P,Q进行矩阵的乘运算得到一个新的矩阵R1,R1就是基于R的预测矩阵
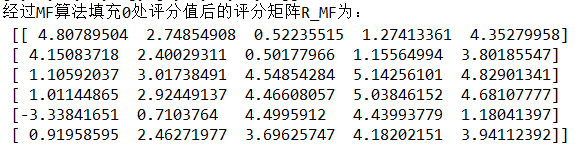
我们可以看出,矩阵R1和矩阵R是非常相似的
现在的问题是,如何求出矩阵Q和P呢
一个很简单的办法是通过迭代的方式逐步求得与R1=QP.T之间的距离变小。设置loss函数,然后使用梯度下降法。
矩阵分解算法推导
1.首先令
2. 2. 损失函数:使用原始的评分矩阵 与重新构建的评分矩阵
与重新构建的评分矩阵 之间的误差的平方作为损失函数,即:
之间的误差的平方作为损失函数,即:
如果R(i,j)已知,则R(i,j)的误差平方和为: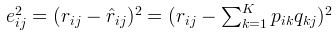
最终,需要求解所有的非“-”项的损失之和的最小值: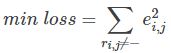
3. 使用梯度下降法获得修正的p和q分量:
- 求解损失函数的负梯度:
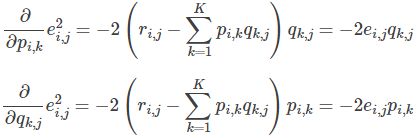
- 根据负梯度的方向更新变量:
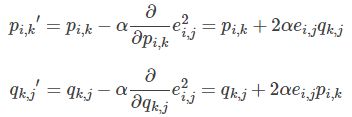
4. 不停迭代直到算法最终收敛(直到sum(e^2) <=阈值)
加入正则化项
【加入正则项的损失函数求解】
1. 首先令
2. 通常在求解的过程中,为了能够有较好的泛化能力,会在损失函数中加入正则项,以对参数进行约束,加入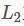 正则的损失函数为:
正则的损失函数为:
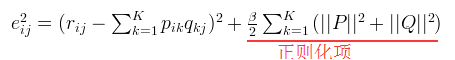
也即:
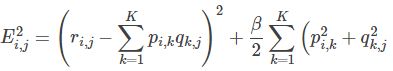
3. 使用梯度下降法获得修正的p和q分量:
- 求解损失函数的负梯度:
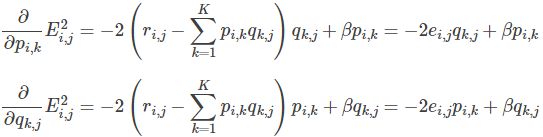
- 根据负梯度的方向更新变量:
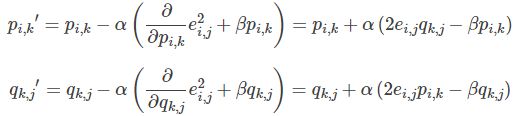
4. 不停迭代直到算法最终收敛(直到sum(e^2) <=阈值)
【预测】利用上述的过程,我们可以得到矩阵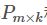 和
和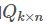 ,这样便可以为用户 i 对商品 j 进行打分:
,这样便可以为用户 i 对商品 j 进行打分:
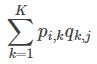
 点一下关注吧,下面是代码奥
点一下关注吧,下面是代码奥
代码实现(这里只给出加入正则化的代码)
-
import numpy
as np
-
import matplotlib.pyplot
as plt
-
-
-
def matrix(R, P, Q, K, alpha, beta):
-
result=[]
-
steps =
1
-
while
1 :
-
#使用梯度下降的一步步的更新P,Q矩阵直至得到最终收敛值
-
steps = steps +
1
-
eR = np.dot(P,Q)
-
e=
0
-
for i
in range(len(R)):
-
for j
in range(len(R[i])):
-
if R[i][j]>
0:
-
# .dot(P,Q) 表示矩阵内积,即Pik和Qkj k由1到k的和eij为真实值和预测值的之间的误差,
-
eij=R[i][j]-np.dot(P[i,:],Q[:,j])
-
#求误差函数值,我们在下面更新p和q矩阵的时候我们使用的是化简得到的最简式,较为简便,
-
#但下面我们仍久求误差函数值这里e求的是每次迭代的误差函数值,用于绘制误差函数变化图
-
e=e+pow(R[i][j] - numpy.dot(P[i,:],Q[:,j]),
2)
-
for k
in range(K):
-
#在上面的误差函数中加入正则化项防止过拟合
-
e=e+(beta/
2)*(pow(P[i][k],
2)+pow(Q[k][j],
2))
-
-
for k
in range(K):
-
#在更新p,q时我们使用化简得到了最简公式
-
P[i][k]=P[i][k]+alpha*(
2*eij*Q[k][j]-beta*P[i][k])
-
Q[k][j]=Q[k][j]+alpha*(
2*eij*P[i][k]-beta*Q[k][j])
-
print(
'迭代轮次:', steps,
' e:', e)
-
result.append(e)
#将每一轮更新的损失函数值添加到数组result末尾
-
-
#当损失函数小于一定值时,迭代结束
-
if eij<
0.00001:
-
break
-
return P,Q,result
-
-
-
-
R=[
-
[
5,
3,
1,
1,
4],
-
[
4,
0,
0,
1,
4],
-
[
1,
0,
0,
5,
5],
-
[
1,
3,
0,
5,
0],
-
[
0,
1,
5,
4,
1],
-
[
1,
2,
3,
5,
4]
-
]
-
-
R=numpy.array(R)
-
-
alpha =
0.0001
#学习率
-
beta =
0.002
#
-
-
N = len(R)
-
M = len(R[
0])
-
K =
2
-
-
p = numpy.random.rand(N, K)
#随机生成一个 N行 K列的矩阵
-
q = numpy.random.rand(K, M)
#随机生成一个 M行 K列的矩阵
-
-
P, Q, result=matrix(R, p, q, K, alpha, beta)
-
print(
"矩阵Q为:\n",Q)
-
print(
"矩阵P为:\n",P)
-
print(
"矩阵R为:\n",R)
-
MF = numpy.dot(P,Q)
-
print(
"预测矩阵:\n",MF)
-
-
-
#下面代码可以绘制损失函数的收敛曲线图
-
n=len(result)
-
x=range(n)
-
plt.plot(x, result,color=
'b',linewidth=
3)
-
plt.xlabel(
"generation")
-
plt.ylabel(
"loss")
-
plt.show()
相关链接(有兴趣可以了解)
https://www.sohu.com/a/190681269_470008
文章欢迎转载,但转载时请保留本段文字,并置于文章的顶部 作者:卢钧轶(cenalulu) 本文原文地址:http://cenalulu.github.io/python/gil-in-python/python全局解释器锁GIL
为什么会有GIL
由于物理上得限制,各CPU厂商在核心频率上的比赛已经被多核所取代。为了更有效的利用多核处理器的性能,就出现了多线程的编程方式,而随之带来的就是线程间数据一致性和状态同步的困难。即使在CPU内部的Cache也不例外,为了有效解决多份缓存之间的数据同步时各厂商花费了不少心思,也不可避免的带来了一定的性能损失。
Python当然也逃不开,为了利用多核,Python开始支持多线程。而解决多线程之间数据完整性和状态同步的最简单方法自然就是加锁。 于是有了GIL这把超级大锁,而当越来越多的代码库开发者接受了这种设定后,他们开始大量依赖这种特性(即默认python内部对象是thread-safe的,无需在实现时考虑额外的内存锁和同步操作)。
慢慢的这种实现方式被发现是蛋疼且低效的。但当大家试图去拆分和去除GIL的时候,发现大量库代码开发者已经重度依赖GIL而非常难以去除了。有多难?做个类比,像MySQL这样的“小项目”为了把Buffer Pool Mutex这把大锁拆分成各个小锁也花了从5.5到5.6再到5.7多个大版为期近5年的时间,并且仍在继续。MySQL这个背后有公司支持且有固定开发团队的产品走的如此艰难,那又更何况Python这样核心开发和代码贡献者高度社区化的团队呢?
所以简单的说GIL的存在更多的是历史原因。如果推到重来,多线程的问题依然还是要面对,但是至少会比目前GIL这种方式会更优雅。
GIL是什么
首先需要明确的一点是GIL并不是Python的特性,它是在实现Python解析器(CPython)时所引入的一个概念。就好比C++是一套语言(语法)标准,但是可以用不同的编译器来编译成可执行代码。有名的编译器例如GCC,INTEL C++,Visual C++等。Python也一样,同样一段代码可以通过CPython,PyPy,Psyco等不同的Python执行环境来执行。像其中的JPython就没有GIL。然而因为CPython是大部分环境下默认的Python执行环境。所以在很多人的概念里CPython就是Python,也就想当然的把GIL归结为Python语言的缺陷。所以这里要先明确一点:GIL并不是Python的特性,Python完全可以不依赖于GIL
那么CPython实现中的GIL又是什么呢?GIL全称Global Interpreter Lock为了避免误导,我们还是来看一下官方给出的解释:
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple native threads from executing Python bytecodes at once. This lock is necessary mainly because CPython’s memory management is not thread-safe. (However, since the GIL exists, other features have grown to depend on the guarantees that it enforces.)
好吧,是不是看上去很糟糕?一个防止多线程并发执行机器码的一个Mutex,乍一看就是个BUG般存在的全局锁嘛!别急,我们下面慢慢的分析。
**
为什么会有GIL
**
由于物理上得限制,各CPU厂商在核心频率上的比赛已经被多核所取代。为了更有效的利用多核处理器的性能,就出现了多线程的编程方式,而随之带来的就是线程间数据一致性和状态同步的困难。即使在CPU内部的Cache也不例外,为了有效解决多份缓存之间的数据同步时各厂商花费了不少心思,也不可避免的带来了一定的性能损失。
Python当然也逃不开,为了利用多核,Python开始支持多线程。而解决多线程之间数据完整性和状态同步的最简单方法自然就是加锁。 于是有了GIL这把超级大锁,而当越来越多的代码库开发者接受了这种设定后,他们开始大量依赖这种特性(即默认python内部对象是thread-safe的,无需在实现时考虑额外的内存锁和同步操作)。
慢慢的这种实现方式被发现是蛋疼且低效的。但当大家试图去拆分和去除GIL的时候,发现大量库代码开发者已经重度依赖GIL而非常难以去除了。有多难?做个类比,像MySQL这样的“小项目”为了把Buffer Pool Mutex这把大锁拆分成各个小锁也花了从5.5到5.6再到5.7多个大版为期近5年的时间,并且仍在继续。MySQL这个背后有公司支持且有固定开发团队的产品走的如此艰难,那又更何况Python这样核心开发和代码贡献者高度社区化的团队呢?
所以简单的说GIL的存在更多的是历史原因。如果推到重来,多线程的问题依然还是要面对,但是至少会比目前GIL这种方式会更优雅。
GIL的影响
从上文的介绍和官方的定义来看,GIL无疑就是一把全局排他锁。毫无疑问全局锁的存在会对多线程的效率有不小影响。甚至就几乎等于Python是个单线程的程序。 那么读者就会说了,全局锁只要释放的勤快效率也不会差啊。只要在进行耗时的IO操作的时候,能释放GIL,这样也还是可以提升运行效率的嘛。或者说再差也不会比单线程的效率差吧。理论上是这样,而实际上呢?Python比你想的更糟。
下面我们就对比下Python在多线程和单线程下得效率对比。测试方法很简单,一个循环1亿次的计数器函数。一个通过单线程执行两次,一个多线程执行。最后比较执行总时间。测试环境为双核的Mac pro。注:为了减少线程库本身性能损耗对测试结果带来的影响,这里单线程的代码同样使用了线程。只是顺序的执行两次,模拟单线程。