Neo4J Cypher neo4j-driver py2neo介绍与使用
Neo4J Cypher neo4j-driver介绍与使用
- neo4j介绍
-
- 关系型数据库和图数据库
- 图数据库的基本概念
-
- Nodes
- Labels
- Relationship
- RelationshipType
- Properties
- Schema
- Cypher
-
- Node Relationship定义与使用
-
- Node Synax
- Relationship syntax
- Pattern syntax
- Pattern Variable
- 对节点和关系的操作
-
- 创建节点
- 创建关系
- 查询
- 修改
- 删库
- neo4j driver
-
- neo4j-driver
-
- 安装
- 例子
- 语法
- py2neo
-
- 安装
- 例子
- 语法
- 安装 环境配置
- 参考链接
neo4j介绍
-
先简单介绍一下
- neo4j 是一个图数据库,专门存储图结构, 图的定义;
-
Cypher 是Neo4J的声明式图形查询语言,类似于传统数据库的
SQL; -
neo4j-driver python版本的Neo4J的驱动程序,实现python与Neo4J的交互,通过这个驱动就可以在python中使用Neo4J了,在python中使用
Cypher来操作图数据库。 -
py2neo python版本的Neo4J的驱动程序,不同的是,其可以直接用类似Python语法操作图数据库。建议使用
py2neo,更方便哈哈哈。
neo4j,Cypher,neo4j-driver之间的关系
关系型数据库和图数据库
| 关系型数据库 | 图数据库 Neo4J |
|---|---|
| 采用了关系模型来组织数据的数据库,其以行和列的形式存储数据称作表,一组表组成了数据库 | 采用图模型存储数据,即根据节点,节点之间的关系边来存储数据 |
| 需要预先定义schema,即定义表,即哪些行/属性 | schema不是必须的 |
| 访问“关系”的效率低下,需要联合表等 | 存储的边,即代表“关系”,访问效率高 |
结构化查询语言SQL |
Graph Query Language: Cypher |
Neo4j重点解决了拥有大量连接的传统RDBMS在查询时出现的性能衰退问题。
图数据库的基本概念
简单例子

接下来将用以上简单例子来说明图数据库中的基本概念。
Nodes
Nodes:节点代表实体,图中的每个矩形代表一个实体,最简单的图只有一个节点。

Labels
Labels:标签,代表 Node/节点/实体 属于哪一个集体,每一个 Node/节点/实体 可以有0个或多个标签。
标签也可以在运行时添加,所以标签也可以描述节点的状态信息。
如下图所示,Tom Hanks既属于Person,又属于Actor。

Relationship
Relationship:关系即代表图中的边,Relationship连接两个节点,使得组织成列表、树、图等更为复杂的结构。
比如上图表示 Tom Hanks在电影Forrest Gump中饰演角色Forrest,其中 饰演角色 就是Tom Hanks和Forrest Gump的关系/Relationship。
RelationshipType
RelationshipType:yige一个Relationship必须有且仅有一个RelationshipType,比如例子中ACTED_IN关系连接了Tom Hanks节点和Forrest Gump节点,并且Tom Hanks节点是起始节点(Source Node,该节点有一条出边),Forrest Gump是目标节点(Target Node,该节点有一条入边)。
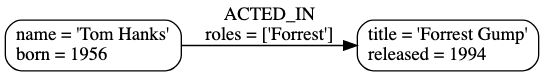
Properties
Properties:属性,即描述 Node/节点 或者 Relationship/关系 的属性。

在这个例子中, Person有 name和born属性,Movie有title和released属性,:ACTED_IN有roles属性。
Schema
Schema:模式,在Neo4J中是可选的,即可以不预先定义一个schema而直接产生数据,以上图例子中,可以不需要为Person定义一个Schema必须包含name和born两个属性。
添加Schema可以提高性能,所以如果需要更高性能可以考虑schema,参见8.schema
Cypher
Graph Query Language
一个小例子如下:
(:Person) -[:LIVES_IN]-> (:City) -[:PART_OF]-> (:Country)
Node Relationship定义与使用
Node Synax
括号()表示一个节点。如下例子中matrix为该节点的变量名/标识符,代表这个节点。花括号{}代表属性。
()
(matrix)
(:Movie)
(matrix:Movie)
(matrix:Movie {title: "The Matrix"})
(matrix:Movie {title: "The Matrix", released: 1997})
Relationship syntax
中括号[]表示一条边 / Relationship type, --表示无向图,-->表示有向图。如下例子中role为该关系的变量名。
-->
-[role]->
-[:ACTED_IN]->
-[role:ACTED_IN]->
-[role:ACTED_IN {roles: ["Neo"]}]->
Pattern syntax
将Node和Relationship组合起来的语法称作Pattern syntax。即Pattern就是将node relationship组合起来。
(keanu:Person:Actor {name: "Keanu Reeves"} )
-[role:ACTED_IN {roles: ["Neo"] } ]->
(matrix:Movie {title: "The Matrix"} )
Pattern Variable
为了避免重复,Cypher支持定义Pattern变量,用法如下:
acted_in = (:Person)-[:ACTED_IN]->(:Movie)
对节点和关系的操作
配置环境,请参考我的上一篇文章neo4j ubuntu安装环境配置 python实例
在安装路径下bin/cypher-shell进入命令行,因为我用的实验室服务器没法访问网页版,所以用的shell,不知道网页版啥样的我哭辽… 能用网页版尽量用网页版!

创建节点
创建两个节点a, b
CREATE (a:Person {name:'Liz'}) return a;
CREATE (b:Person {name:'Mike'}) return b;

创建关系
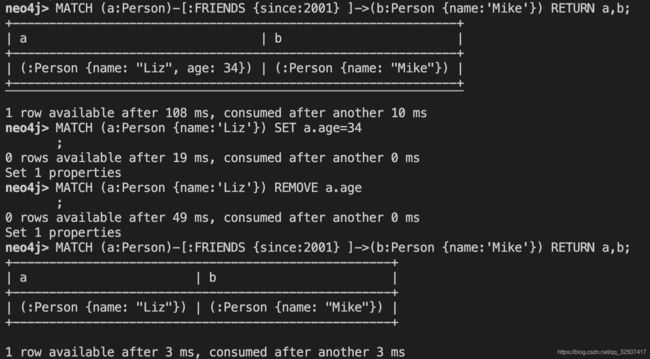
创建a与b之间的朋友关系,从2001起a是b的朋友。
MATCH (a:Person {name:'Liz'}), (b:Person {name:'Mike'})
MERGE (a)-[:FRIENDS {since:2001} ]->(b);

查询
查询Mike从2001年起交的所有的朋友
MATCH (a:Person)-[:FRIENDS {since:2001} ]->(b:Person {name:'Mike'}) RETURN a,b;

修改
将名字为Liz的节点,添加Age属性
MATCH (a:Person {name:'Liz'}) SET a.age=34;
将名字为Liz的节点,删除Age属性
MATCH (a:Person {name:'Liz'}) REMOVE a.age;
将名字为Liz的节点删除
MATCH (a:Person {name:'Liz'}) DELETE a;
删库
MATCH (n) DETACH DELETE n;

neo4j driver
| neo4j-driver | py2neo |
|---|---|
| official driver | community driver |
| neo4j可以提供技术支持 | 社区开源,更高级的封装,可以不熟悉Cypher |
neo4j-driver
-
neo4j-driver有两个概念,
- Driver Object 驱动程序对象保存Neo4J的详细信息,包括 服务器uri、凭证信息、配置信息等、管理Cypher session连接池;
- Cypher Session 事务性工作单元的逻辑上下文。人话就是,真正执行Cypher语句的地方。
Driver Objects和
Cypher sessions。
安装
pip install neo4j
例子
# step 1:导入 Neo4j 驱动包
from neo4j import GraphDatabase
# step 2:连接 Neo4j 图数据库
driver = GraphDatabase.driver("bolt://127.0.0.1:7687", auth=("neo4j", "newneo4j"))
# driver = GraphDatabase.driver("http://127.0.0.1:7474", auth=("neo4j", "neo4j"))
# 添加 关系 函数
def add_friend(tx, name, friend_name):
tx.run("MERGE (a:Person {name: $name}) "
"MERGE (a)-[:KNOWS]->(friend:Person {name: $friend_name})",
name=name, friend_name=friend_name)
# 定义 关系函数
def print_friends(tx, name):
for record in tx.run("MATCH (a:Person)-[:KNOWS]->(friend) WHERE a.name = $name "
"RETURN friend.name ORDER BY friend.name", name=name):
print(record["friend.name"])
# step 3:运行
with driver.session() as session:
session.write_transaction(add_friend, "Arthur", "Guinevere")
session.write_transaction(add_friend, "Arthur", "Lancelot")
session.write_transaction(add_friend, "Arthur", "Merlin")
session.read_transaction(print_friends, "Arthur")
语法
建议参考官方文档,边用边查。
py2neo
安装
pip install py2neo
例子
# step 1:导包
from py2neo import Graph, Node, Relationship
# step 2:构建图
g = Graph("http://localhost:7474",auth=("neo4j","newneo4j"))
# step 3:创建节点
tx = g.begin()
a = Node("Person", name="Alice")
tx.create(a)
b = Node("Person", name="Bob")
# step 4:创建边
ab = Relationship(a, "KNOWS", b)
# step 5:运行
tx.create(ab)
tx.commit()
语法
建议参考官方文档,边用边查。
安装 环境配置
参考我的上一篇文章 neo4j ubuntu安装环境配置 python实例
参考链接
- 图形数据库
- 关系型数据库
- Graph Database Concept
- Cypher
- 手把手教你快速入门知识图谱 - Neo4J教程
- Datawhale 知识图谱组队学习 之 Task 1 知识图谱介绍
- Using Neo4J from Python
- py2neo
- Cypher Sessions