Pytorch模型(2)——N-gram CNN
概述
N-gram CNN在NLP中的应用主要是可以通过N-gram来捕捉局部语义信息,相比于加入了自注意力机制的模型而言,缺陷在于无法捕捉长距离的句子依赖,而且Transformer也可以并行去训练,我们可以将N-gram CNN+max pooling视为一种基于显著性注意力的语义Encoder
Model
class CNNEncoder(nn.Module):
"""
卷积提取Encoder
"""
def __init__(self, in_channels, out_channels, output_dim):
"""
CNN Encoder:
- in_channels: 词向量的维度
- out_channels: 经过CNN编码后的维度
- output_dim: 经过线性层后Phrase Encoder的最终维度
input: (batch_size, max_seq_len, embedding_dim)
output: (batch_size, output_dim)
"""
super().__init__()
self.in_channels = in_channels
self.out_channels=out_channels
self.output_dim=output_dim
self.kernel_sizes = [1, 2, 3]
self.kernel_num = 512
self.convs=nn.ModuleList([nn.Conv1d(in_channels=self.in_channels, out_channels=self.kernel_num, kernel_size=k) for k in self.kernel_sizes])
self.dropout=nn.Dropout(0.1)
self.linear=nn.Linear(in_features=self.kernel_num*len(self.kernel_sizes), out_features=self.output_dim)
def forward(self, input):
data, seq_len = input
# (batch_size, embedding_dim, max_seq_len)
x = data.permute(0, 2, 1)
# (batch_size, kernel_num, max_seq_len-kernel_size+1) * len(kernels)
x = [F.relu(conv(x)) for conv in self.convs]
# (batch_size, kernel_num) * len(kernels)
x = [F.max_pool1d(c, c.size(2)).squeeze(2) for c in x]
# (batch_size, kernel_num * len(kernels))
x = torch.cat(x, 1)
x = self.dropout(x)
# (batch_size, output_dim)
x = self.linear(x)
out = F.normalize(x,p=2,dim=1)
return out
一些理解
- kernel_size为1的卷积核的作用
根据卷积操作的定义,在图像中相当于改变了图片的通道数为filter个数,在文本中相当于将Embedding维度变为filter个数,即最终相当于apply了一个线性层
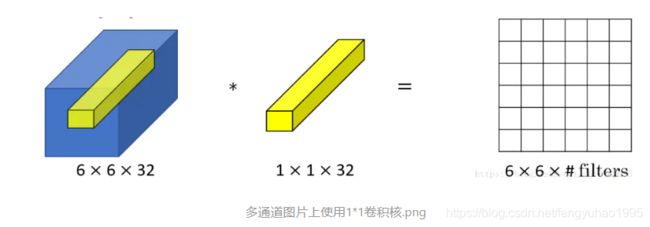
nn.Conv1d的使用
conv1 = nn.Conv1d(in_channels=256,out_channels=100,kernel_size=2)
# (batch_size, text_len, embedding_size)
input = torch.randn(32,35,256)
# (batch_size, embedding_size, text_len)
input = input.permute(0,2,1)
# (batch_size, out_channel, text_len-kernel_size+1)
out = conv1(input)
Out:
# out
torch.Size([32, 100, 34])
- Batch Normalization / Layer Normalization / Instance Normalization
data shape: [N, C, H, W]
Batch Normalization就是在通道Channel这个维度上进行移动,对所有样本的所有值求均值和方差,所以有几个通道,得到的就是几个均值和方差
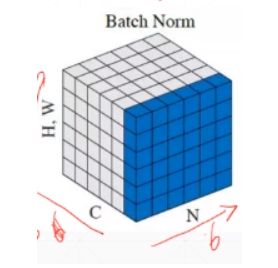
如下图输入数据是6张3通道784个像素点的数据,将其分到三个通道上,在每个通道上也就是[6, 784]的数据,然后分别得到和通道数一样多的统计数据均值μ 和方差σ ,将每个像素值减去μ 除以σ 也就变换到了接近N(0,1) 的分布,后面又使用参数β 和γ 将其变换到接近N(β,γ) 的分布。

Layer Normalization是在实例即样本N的维度上滑动,对每个样本的所有通道的所有值求均值和方差,所以一个Batch有几个样本实例,得到的就是几个均值和方差。
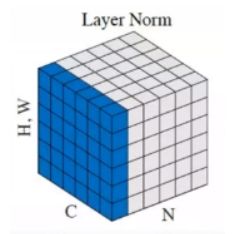
- BN层和L2 Norm层的区别
BN层是使不同的feature之间具有可比性,其使得每个feature的方差为1,均值为0;
L2 Norm层是使不同的样本之间具有可比性,其将不同样本的feature拉到同一量级,但并没有改变feature之间的相对大小;
对于不同layer输出后进行concat操作,使用L2 Norm层比较合适
- CNN层加入注意力机制CBAM

在NLP实验中,效果不是很好
参考
卷积神经网络理解及1*1卷积核的作用
Keras之文本分类实现
pytorch之nn.Conv1d详解
自用Pytorch笔记(十六:Batch Normalization)(1.1版本)
BN和L2 NORM的区别
pytorch中加入注意力机制(CBAM)以ResNet为例
具有注意力能力的卷积神经网络“CBAM”