个性化广告推荐系统实战系列(二):根据用户行为数据创建ALS模型并召回商品
1. 写在前面
这几天打算整理一个模拟真实情景进行广告推荐的一个小Demon, 这个项目使用的阿里巴巴提供的一个淘宝广告点击率预估的数据集, 采用lambda架构,实现一个离线和在线相结合的实时推荐系统,对非搜索类型的广告进行点击率预测和推荐(没有搜索词,没有广告的内容特征信息)。这个感觉挺接近于工业上的那种推荐系统了,通过这个推荐系统,希望能从工程的角度了解推荐系统的流程,也顺便学习一下大数据的相关技术,这次会涉及到大数据平台上的数据处理, 离线处理业务和在线处理业务, 涉及到的技术包括大数据的各种技术,包括Hadoop,Spark(Spark SQL, Spqrk ML, Spark-Streaming), Redis,Hive,HBase,Kafka和Flume等, 机器学习的相关技术(数据预处理,模型的离线训练和在线更新等。所以这几天的时间借机会走一遍这个流程,这里也详细记录一下,方便以后回看和回练, 这次的课程是跟着B站上的一个课程走的, 讲的挺详细的,就是没有课件和资料,得需要自己搞,并且在实战这次的推荐系统之前,最好是有一整套的大数据环境(我已经搭建好了), 然后就可以来玩这个系统了哈哈, 现在开始
今天是第二篇基于用户的行为数据进行商品的召回模块,上一篇文章中 梳理完了任务和简单的流程, 我们这里开始第一步,根据用户行为数据实现商品的召回,并且要把召回的结果缓存到数据库中供后面的排序使用。 内容如下:
- 数据集的采样
- 数据集的预处理
- 训练ALS模型并进行召回商品
- 总结
Ok, let’s go!
2. 数据集采样
这个步骤是因为设备限制才不得不采取的一种方式,由于下载下来的数据集太大了, 22个G的行为数据,我电脑没法跑,所以我先对数据进行了采样,采样的过程是这样, 首先基于骨架的那个数据从100万个用户的点击中选择了1万用户的20多万次点击数据。 然后再读取behavior_log.csv文件, 从里面选择出采样的这1万个用户的行为数据组成新的DataFrame保存作为用户行为日志记录。 这里学到了pandas的大数据的分批读取操作,即如果数据非常大(22G), 我内存才16G,没法一下子读取进来处理,这时候就可以用pandas分块读取数据,边处理边写到文件的方式。代码如下:
import pandas as pd
# chunksize参数指定之后, 每次读入一百条数据,构成也给迭代器
reader = pd.read_csv('behavior_log.csv',chunksize=100,iterator=True)
count = 0;
# 这里每次读100条, 然后去处理,处理完了写入文件即可
for chunk in reader:
count += 1
if count ==1:
chunk.to_csv('test4.csv',index = False)
elif count>1 and count<1000:
chunk.to_csv('test4.csv',index = False, mode = 'a',header = False)
else:
break
pd.read_csv('test4.csv')
这是一个类似框架的东西,由于我这里需要进行采样,然后重新整合数据,所以把上面代码改了一下:
# 从raw_sample数据集里面选择出5万用户来
user_sample_id = np.random.choice(raw_sample['user'].unique(), size=10000, replace=False)
sample_raw = raw_sample[raw_sample['user'].isin(user_sample_id)]
# 采样behavior_log, 这个22个G,需要分开读入数据
users = set(user_sample_id)
reader = pd.read_csv(path + 'behavior_log.csv', chunksize=1000, iterator=True)
behavior_log = []
count = 0
for chunk in reader:
behavior_log.append(chunk[chunk['user'].isin(users)].values)
count += 1
if count % 1000 == 0:
print(count, end=",")
if count > 20000:
break
# 把数据拼起来, 然后转成DataFrame并保存到文件
behavior_logs = np.concatenate(behavior_log)
behavior_logs = pd.DataFrame(behavior_logs, columns=['user', 'timestamp', 'btag', 'cate_id', 'brand_id'])
behavior_logs.to_csv('./dataset/behavior_logs.csv', index=False)
sample_raw.to_csv('./dataset/raw_sample.csv', index=False)
这样,最后得到了个100M左右的dataset文件夹,里面有四个数据文件,两个是采样的数据,另外两个是用户和广告特征,不用变。然后上传到搭建好的服务器中(master)。
4. 数据集预处理
数据传到了master,算是存在了本地上, 下面我们打开三台虚拟机, 然后开启Hadoop和Spark,
start-all.sh # 开启Hadoop
cd /opt/bigdata/spark/spark2.2/sbin/
start-all.sh # 开启spark
# 查看进程
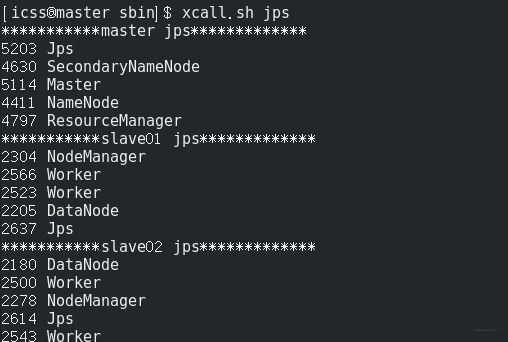
xcall.sh jps
正常开启:
下面进行数据的预处理相关操作。首先,先把本地的数据放到HDFS上, 方便后续的分布式的数据读取。命令如下:
hadoop fs -put dataset /user/icss/RecommendSystem
这样就把数据传到了HDFS上:

然后开启远程jupyter notebook
conda activate bigdata_env
jupyter notebook --allow-root
这样在回到Windows上输入http:192.168.56.101:8890,即可进入远程jupyter。
新建一个jupyter notebook处理数据用, 由于要使用SparkSQL,所以需要pyspark的相关配置如下:
import os
# 配置spark driver和pyspark运行时,所使用的python解释器路径
import sys # sys.path是python的搜索模块的路径集,是一个list
os.environ['JAVA_HOME'] = '/opt/bigdata/java/jdk1.8'
os.environ['SPARK_HOME'] = '/opt/bigdata/spark/spark2.2'
os.environ['PYSPARK_PYTHON'] = '/opt/bigdata/anaconda3/envs/bigdata_env/bin/python3.7'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/opt/bigdata/anaconda3/envs/bigdata_env/bin/python3.7'
sys.path.append('/opt/bigdata/spark/spark2.2/python')
sys.path.append('/opt/bigdata/spark/spark2.2/python/lib/py4j-0.10.4-src.zip')
sys.path.append('/opt/bigdata/anaconda3/envs/bigdata_env/bin/python3.7')
# spark 配置信息
from pyspark import SparkConf
from pyspark.sql import SparkSession
SPARK_APP_NAME = "ALSRecommend"
SPARK_URL = "spark://192.168.56.101:7077" # 这个不要写错
conf = SparkConf() # 创建spark config对象
config = (
("spark.app.name", SPARK_APP_NAME), # 设置启动的spark的app名称,没有提供,将随机产生一个名称
("spark.executor.memory", "6g"), # 设置该app启动时占用的内存用量,默认1g
("spark.master", SPARK_URL), # spark master的地址
("spark.executor.cores", "4"), # 设置spark executor使用的CPU核心数
# 以下三项配置,可以控制执行器数量
# ("spark.dynamicAllocation.enabled", True),
# ("spark.dynamicAllocation.initialExecutors", 1), # 1个执行器
# ("spark.shuffle.service.enabled", True)
# ('spark.sql.pivotMaxValues', '99999'), # 当需要pivot DF,且值很多时,需要修改,默认是10000
)
# 查看更详细配置及说明:https://spark.apache.org/docs/latest/configuration.html
conf.setAll(config)
# 利用config对象,创建spark session
spark = SparkSession.builder.config(conf=conf).getOrCreate()
这里面的SPAR_URL不要写错,一开始把前面的spark写成了master,结果报了:"Java gateway process exited before sending the driver its port number", 这个又在让我花时间查了一会,结果他们的提供JAVA_HOME啥的在我这里都没有用, 偶然间看到了我当时大环境的这里,才恍然大悟了一下,哈哈太巧了这次, 当然又为解决这个问题提供了一种新思路:
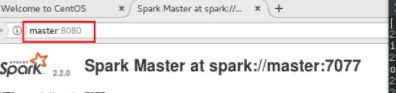
这里就是Spark Master的地址, 我把前面的master改成了spark,结果搞定了这个错误。一场虚惊,下面继续往下走:
# 从hdfs加载csv文件为DataFrame
behaviors_log_df = spark.read.csv("hdfs://master:9000/user/icss/RecommendSystem/dataset/behavior_logs.csv", header=True)
发现执行这个代码之后一直在执行状态,一个原因是数据太大,读入的速度太慢,然后我重新采样了一下数据,再次缩小数据的规模,发现还是超级慢, 然后我查了下日志,提示:
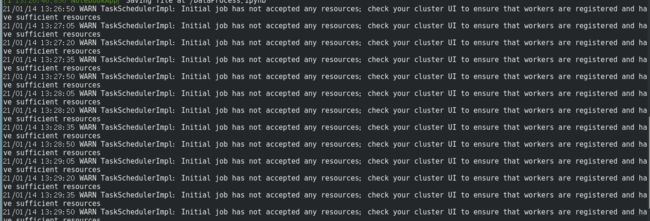
反复出现这个东西, 百度了一下,说是资源不足,建议关掉spark的其他程序,而我通过spark UI看了一下,我的只有这个东西在跑
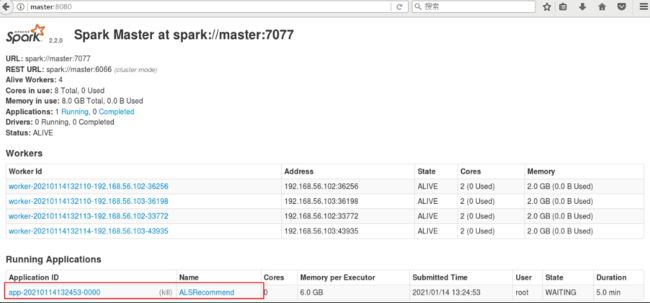
所以我猜测是内存不足的问题, 于是我改了重启了一下jupyter,改了一下上面代码里面的spark 配置,把APP启动时占用的内存改成2g,spark executor核心数改成了2, 很快就读出来了。 这次又长见识了, 要是放在以前,估计又傻傻的等下去了。 而现在慢慢的学乖了,一出现异常就去看日志,真的可以解决很多隐性问题。下面就可以看一下数据:
# 查看一下数据, 默认显示前20条
behaviors_log_df.show()
behaviors_log_df.count() # 437288
# 大致看一下数据类型 打印当前的DataFrame结构
behaviors_log_df.printSchema()
## 结果:
root
|-- user: string (nullable = true)
|-- timestamp: string (nullable = true)
|-- btag: string (nullable = true)
|-- cate_id: string (nullable = true)
|-- brand_id: string (nullable = true)
这里会发现默认读取的DataFrame会有问题, 字段的数据类型都是string类型, 所以我们一般不用这种默认的方式, 而是在读取的时候, 设置一下数据类型和结构, 代码如下:
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, LongType
# 构建结构对象
schema = StructType([
StructField("userId", IntegerType()),
StructField("timestamp", LongType()),
StructField("btag", StringType()),
StructField("cateId", IntegerType()),
StructField("brandId", IntegerType())
])
behaviors_log_df = spark.read.csv("hdfs://master:9000/user/icss/RecommendSystem/dataset/behavior_logs.csv", header=True, schema=schema)
这样再来查看就符合要求了。

4.1 数据分析
这里我们查看一下数据集的字段类型和格式
print("查看userId的数据情况:", behavior_log_df.groupBy("userId").count().count())
# 约113w用户
#注意:behavior_log_df.groupBy("userId").count() 返回的是一个dataframe,这里的count计算的是每一个分组的个数,但当前还没有进行计算, transformation操作,还没有action
# 当调用df.count()时才开始进行计算,这里的count计算的是dataframe的条目数,也就是共有多少个分组
# 结果: 9143
# 采样完了之后还有这些用户了, 当时虽然采了10000个用户的, 但是采样的是raw_sample表,且当时采的时候并没有完全把log表采完,所以这个数也是合理的
下面查看btag的数据情况, 这个类似于pandas的value_counts()的功能
# 查看btag的数据情况
print("查看btag的数据情况:", behaviors_log_df.groupBy("btag").count().collect())
# collect会把计算结果全部加载到内存,谨慎使用
# 只有四种类型数据:pv、fav、cart、buy
# 这里由于类型只有四个,所以直接使用collect,把数据全部加载出来
# 结果
查看btag的数据情况: [Row(btag='buy', count=5577), Row(btag='fav', count=5726), Row(btag='cart', count=9648), Row(btag='pv', count=416337)]
下面看商品类别,商品品牌,是否有空值情况:

由于之前已经清洗好,所以没有空值了。基本情况已经看完了。
4.2 透视转换
接下来需要把表转换一下, 因为我们后面需要进行召回的操作, 所以我们需要统计出用户对于广告的各种行为次数,比如用户A,对于广告b,有几次收藏,几次浏览,几次购买等。 而目前我们的数据是下面这样:
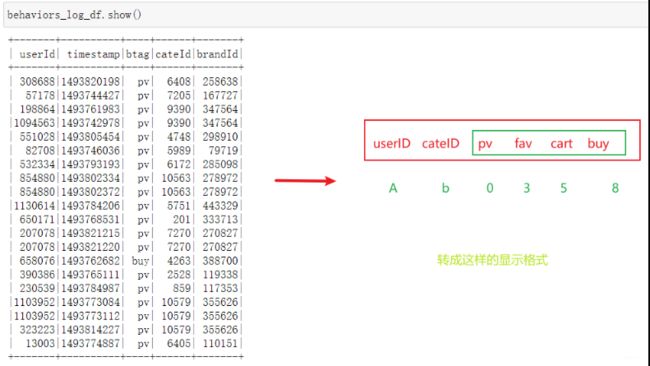
把某列里的字段值转换成行并进行聚合统计运算, 这正是pivot透视的操作, 所以我们用pyspark.sql.GroupedData.pivot函数对日志表进行透视显示, 如果透视的字段中的不同属性值超过10000个,则需要设置spark.sql.pivotMaxValues,否则计算过程中会出现错误。文档介绍。
# 统计每个用户对各类商品的PV,fav, cart, buy的数量
cate_count_df = behaviors_log_df.groupBy(behaviors_log_df.userId, behaviors_log_df.cateId).pivot("btag", ["pv", "fav", "cart", "buy"]).count()
# 统计各个用户各个品牌的pv,fav,cart,buy的数量
brand_count_df = behaviors_log_df.groupBy(behaviors_log_df.userId, behaviors_log_df.brandId).pivot("btag",["pv","fav","cart","buy"]).count()
# 由于运算时间比较长,所以这里先将结果存储起来,供后续其他操作使用
# 写入数据时才开始计算
cate_count_df.write.csv("hdfs://master:9000/user/icss/RecommendSystem/preprocessing_dataset/cate_count.csv", header=True)
brand_count_df.write.csv("hdfs://master:9000/user/icss/RecommendSystem/preprocessing_dataset/brand_count.csv", header=True)
这里内存差点爆掉, 上面代码写入的时候还要注意一点就是给preprocessing_dataset目录授权可写,因为jupyter我是root用户弄的,而建立preprocessing_dataset目录的时候是icss用户,这里一开始报了一个权限不够。

这样就完成了透视操作, 接下来就基于这两个透视表操作了, 此时为了节省内存,重启jupyter,然后读入上面保存的两个表,进行ALS模型的训练,这个ALS模型就是矩阵分解的原理,只不过训练的时候不是用的梯度下降方式求参数,而是交替最小二乘的方法求用户和类别或者品牌的隐变量。 关于原理,这里不过多介绍,这个ALS模型是spark的ml库里自带的,我们可以直接调用。
5. 根据用户的打分情况训练ALS模型并进行召回
5.1 对类别的打分召回
这里我们基于用户对类别的行为(打分)情况对广告的类别进行召回操作, 先读入上面保存的cate_count.csv
# spark ml的模型训练是基于内存的,如果数据过大,内存空间小,迭代次数过多的化,可能会造成内存溢出,报错
# 设置Checkpoint的话,会把所有数据落盘,这样如果异常退出,下次重启后,可以接着上次的训练节点继续运行
# 但该方法其实指标不治本,因为无法防止内存溢出,所以还是会报错
# 如果数据量大,应考虑的是增加内存、或限制迭代次数和训练数据量级等
spark.sparkContext.setCheckpointDir("hdfs://master:9000/user/icss/RecommendSystem/checkPoint/")
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, LongType, FloatType
# 构建结构对象
schema = StructType([
StructField("userId", IntegerType()),
StructField("cateId", IntegerType()),
StructField("pv", IntegerType()),
StructField("fav", IntegerType()),
StructField("cart", IntegerType()),
StructField("buy", IntegerType())
])
# 从hdfs加载CSV文件
cate_count_df = spark.read.csv("hdfs://master:9000/user/icss/RecommendSystem/preprocessing_dataset/cate_count.csv", header=True, schema=schema)
简单的看下这个表:
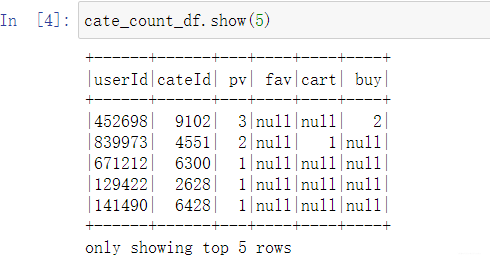
这个表只是记录了用户对于类别的各种行为次数, 我们得指定打分规则,把这些次数转换成最终的一个评分情况,这样我们才能训练后面的ALS模型,也就是用户的评分矩阵,这个的形式就是user, cate_id, rate的格式。我们要把数据处理成这样, 所以这里我们设计一个评分规则,对每一行处理, 这样正好对应map的操作, 处理的逻辑如下, 比较简单:
# 下面处理每一行数据: r表示row对象
def process_row(r):
"""
这里我们设置一个打分规则, 假设m: 用户对应的行为次数,偏好权重比例, 次数上限仅供参考, 具体数值根据产品的业务场景权衡
pv: if m<=20: score=0.2*m; else score=4
fav: if m<=20: score=0.4*m; else score=8
fav: if m<=20: score=0.4*m; else score=8
buy: if m<=20: score=1*m; else score=20
这里是针对每一行进行的数据, 进行处理
"""
# 注意这里要全部设为浮点数,spark运算时对类型比较敏感,要保持数据类型都一致
pv_count = r.pv if r.pv else 0.0
fav_count = r.fav if r.fav else 0.0
cart_count = r.cart if r.cart else 0.0
buy_count = r.buy if r.buy else 0.0
# 打分规则
pv_score = 0.2*pv_count if pv_count<=20 else 4.0
fav_score = 0.4*fav_count if fav_count<=20 else 8.0
cart_score = 0.6*cart_count if cart_count<=20 else 12.0
buy_score = 1.0*buy_count if buy_count<=20 else 20.0
# 最终得分返回
rating = pv_score + fav_score + cart_score + buy_score
return r.userId, r.cateId, rating
这样,我们对于每一样的结果传进去,就会算出一个评分, 并且按照我们期望的形式返回来
# 用户对商品类别的打分数据
# map返回的结果是rdd类型,需要调用toDF方法转换为Dataframe
cate_rating_df = cate_count_df.rdd.map(process_row).toDF(["userId", "cateId", "rating"])
# 注意:toDF不是每个rdd都有的方法,仅局限于此处的rdd,这里的cate_rating_df是从DF过来的, 需要有schema结构的数据才能转成DF
# 可通过该方法获得 user-cate-matrix
# 但由于cateId字段过多,这里运算量比很大,机器内存要求很高才能执行,否则无法完成任务
# 请谨慎使用
# 但好在我们训练ALS模型时,不需要转换为user-cate-matrix,所以这里可以不用运行
# cate_rating_df.groupBy("userId").povit("cateId").min("rating")
# 用户对类别的偏好打分数据
我这里竟然报了个错误 Py4JJavaErrorAn error occurred while calling z:org.apache.spark.api.python.PythonRDD.runJob.org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 1.0 failed 4 times, most recent failure: Lost task 0.3 in stage 1.0 (TID 4, 192.168.56.102, executor 3): java.io.IOException: Cannot run program "/opt/bigdata/spark/spark2.2/python": error=13, 权限不够
这个报错显然又涉及到了权限问题, 但是尝试修改权限为777,发现也报这个错误。 这里耗费了整整几个小时的时间, 最后终于探索到了, 这里是python解释器有问题, 所以需要在一开始的时候加入:
os.environ['PYSPARK_PYTHON'] = '/opt/bigdata/anaconda3/envs/bigdata_env/bin/python3.7'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/opt/bigdata/anaconda3/envs/bigdata_env/bin/python3.7'
这里一定要注意: 这里虽然加入了, 但是之前配置anaconda3的时候只在master中安装的, 所以再执行上面的代码之后,会提示slave01和slave02找不到python解释器的位置。 这里一开始没有看清是slave01, 所以一直找master上面,明明有却报错,然后一顿瞎找。 最后才意识到了这个问题所在。 于是乎就在相同的路径下, 把bigdata_env复制到了slave01和slave02的同样位置(和master一样的位置), 本来想直接复制anaconda3的,但是这个太大了,报硬盘不足。
总算, 解决了这个问题, 结果如下;
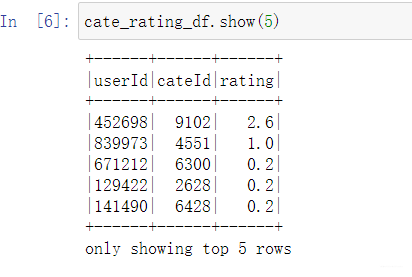
这样就到了我们想要的格式了, 下面就可以建立ALS模型了。
基于Spark的ALS隐因子模型进行CF评分预测
-
ALS的意思是交替最小二乘法(Alternating Least Squares),是Spark2.*中加入的进行基于模型的协同过滤(model-based CF)的推荐系统算法。
同SVD,它也是一种矩阵分解技术,对数据进行降维处理。
-
详细使用方法:pyspark.ml.recommendation.ALS
-
注意:由于数据量巨大,因此这里也不考虑基于内存的CF算法
参考:为什么Spark中只有ALS
建立模型的代码如下:
from pyspark.ml.recommendation import ALS # ml: dataframe, mllib: rdd
# 利用打分数据, 训练ALS模型 checkpointInterval 是每训练几步缓存一次
als = ALS(userCol='userId', itemCol='cateId', ratingCol='rating', checkpointInterval=5)
# 此处训练时间较长
model = als.fit(cate_rating_df)
这个过程需要安装numpy, 我上面目前没有numpy, 所以用pip安装了一下,发现一晚上还没装上, 总是中途连接失败,用conda同样也是如此,原来是源出现了问题,所以找到了一种快速安装包的方式,就是在后面加上源, 也记录一下子:
pip install numpy -i https://pypi.tuna.tsinghua.edu.cn/simple
加上清华源之后, 安装numpy可谓秒安装了。然后就是模型的训练了。这里使用的spark ml, 这个基于的DataFrame, 也就是spark SQL那一块, 而spark mllib是基于的rdd, 运算速度上会有些差别,前者在一些地方进行了优化,所以现在spark ml用的多一些了。下面简单的看一下两者的不同:
spark MLlib
- 最早开发的
- 基于RDD的API
- 目前已经停止维护了(从2.3)
- 还可以使用
spark ML
- 目前在更新的是这个库
- 基于DataFrame
Spark ML的库中封装了协同过滤的ALS模型, 训练的时候传入的是一个DataFrame, 包含用户id, 物品id, 用户-物品评分这三列, 利用这三列就可以使用Spark ALS模块训练ALS模型。模型训练好后,调用方法进行使用,具体API查看
# model.recommendForAllUsers(N) 给所有用户推荐TOP-N个物品
ret = model.recommendForAllUsers(3)
# 由于是给所有用户进行推荐,此处运算时间也较长
ret.show(truncate=False) # 后面的truncate是都显示出来
# 推荐结果存放在recommendations列中,
ret.select("recommendations").show()
下面看下效果吧:
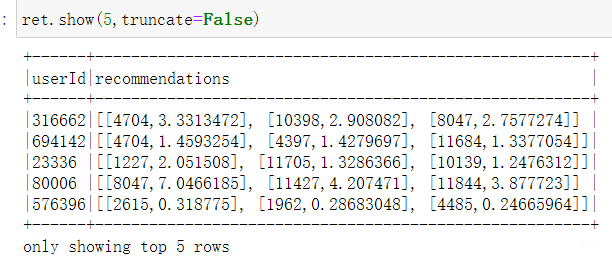
注意,后面的id是商品类别的id,还不是直接广告的id。 与之类似的一个函数是recommendForAllItems(N),对于某个类别的商品找到相关的N个用户。上面两个都是针对于所有用户或者所有物品的, 那么我要是给某个指定用户推荐呢?
下面的函数是给部分用户推荐商品, 这时候需要把用户放到一个DataFrame中进行传入。
model.recommendForUserSubset 给部分用户推荐TOP-N个物品
# 注意:recommendForUserSubset API,2.2.2版本中无法使用
dataset = spark.createDataFrame([[1],[2],[3]])
dataset = dataset.withColumnRenamed("_1", "userId")
ret = model.recommendForUserSubset(dataset, 3)
# 只给部分用推荐,运算时间短
ret.show()
ret.collect() # 注意: collect会将所有数据加载到内存,慎用
这个在spark2.3.x后面才有, 由于我的spark版本正好是2.2的,所以告诉我没有这个函数。 所以对于我这中情况,只能是先基于所有用户推荐出商品来,再采用过滤的方式选择出我想要的用户即可。
下面介绍一个模型保存的操作方式,transform中提供userId和cateId可以对打分进行预测,利用打分结果排序后
# transform中提供userId和cateId可以对打分进行预测,利用打分结果排序后,同样可以实现TOP-N的推荐
model.transform
# 将模型进行存储
model.save("hdfs://localhost:8020/models/userCateRatingALSModel.obj")
# 测试存储的模型
from pyspark.ml.recommendation import ALSModel
# 从hdfs加载之前存储的模型
als_model = ALSModel.load("hdfs://localhost:8020/models/userCateRatingALSModel.obj")
# model.recommendForAllUsers(N) 给用户推荐TOP-N个物品
result = als_model.recommendForAllUsers(3)
result.show()
这个就不演示了, 这里是对模型进行了一波保存, 但是model.save之前用了一下model.transform的操作。下面就是把召回的结果可以保存到Redis中,在后面的使用提供使用了。
5.2 保存召回结果到Redis
这里用到了Redis, 这个我之前安装好了, 安装过程看这里, 先开启Redis服务器端。
cd /opt/bigdata/redis/redis3.0/
src/redis-server redis.conf
# 看一下 我这边已经开起来了
ps -ef | grep redis
由于我们目前还是召回的商品类别,而我们排序模型中是广告的点击率预测,两者之间还需要那么一点映射, 这里先测试一下Redis是否好用, 之前搭建完了环境之后,并不知道怎么使用这个东西, 借着这个机会玩一下。
把结果召回到Redis进行保存, 首先需要在bigdata_env中安装redis包,否则找不到这个模块ModuleNotFoundError: No module named 'redis', 这里我直接pip install redis。然后直接导入,指定好主机和端口号
import redis
host = "192.168.56.101" # 这是我的master主机位置
port = 6379
这个Redis的主机和port是我当时配置的时候设置的, 具体的要跟着自己的来,然后就可以进行下面的代码了, 这里要有一个客户端。
# 召回到redis 存储的和核心代码就是这个函数
def recall_cate_by_cf(partition):
# 建立redis 连接池
pool = redis.ConnectionPool(host=host, port=port, db='0') # 主机, 端口,数据库编号
# 建立redis客户端
client = redis.Redis(connection_pool=pool)
# 键值对的形式保存起来了 键: 用户id, 值: 推荐的商品类别
for row in partition:
client.hset("recall_cate", row.userId, [i.cateId for i in row.recommendations])
# 对每个分片的数据进行处理 #mapPartition Transformation map
# foreachPartition Action操作 foreachRDD
result.foreachPartition(recall_cate_by_cf)
# 注意:这里这是召回的是用户最感兴趣的n个类别
# 总的条目数,查看redis中总的条目数是否一致
result.count()
点击运行之后,又开始一系列的坑了, 这里开始记录。
第一次运行,报错说ModuleNotFoundError: No module name 'redis', 一开始感到了点奇怪,明明先导入的这个东西呀, 但是再往上排查发现是192.168.56.103节点报的错误。这里就大体明白是怎么回事了,原因是redis包没有真正的放入pyspark里面, 节点找不到啊,这时候别百度了,因为这时候百度的大部分结果依然是让你安装redis包, 而我们这里的问题不是anaconda或者jupyter找不到这个包的问题,而是spark里面的程序文件找不到这个包,这时候需要把这个包放到pyspark中,这样在spark的底层运行的时候才能够找到redis。所以有时候我们遇到问题百度的时候也需要改变一下问问题的方式,否则可能找不到我们想要的答案,一开始我也是又直接粘贴复制的这个问题报错,结果百度上的都是anaconda里面没有这个包的问题,废了很多时间,唉。
这里把上面的这个问题转成一个通用的问题,然后给出解决方式。
通用问题就是在spark上运行Python代码遇到“ImportError: No module name xxxx”,这时候有可能不是anaconda环境里面没有这个包,如果是这个原因,一般发生在import的时候, 而不是具体运行的时候。 如果具体运行的时候报这样的一个错误,且涉及到RDD的一些东西,往往就是这个问题了。这个问题的解决方式:spark中添加相应的模块。
这里拿redis举例:由于我在anaconda中安装了redis, 所以在相应环境的包下面会找到,我把redis压缩成redis.zip文件,然后把这个放到某个目录中, 然后再sparkContext.addPyFile加入这个zip文件即可。这么说可能抽象,我的具体做法,首先压缩redis:
# 我在当前目录下面建了一个redis目录名,必须是这个名字
# 然后把anaconda环境中的redis包移动到了这个目录下,然后进行了压缩操作
!mkdir redis
!mv /opt/bigdata/anaconda3/envs/bigdata_env/lib/python3.7/site-packages/redis redis
# 这里是用代码进行的压缩,也可以zip命令压缩好
import shutil
dir_name = "redis"
output_filename = "./redis"
shutil.make_archive(output_filename, 'zip', dir_name)
压缩完毕之后,当前目录多了个redis.zip文件,把这个移动到了spark2.2/pyhont/lib和pyspark放一块了。当然也可以不放一块,只要下面导入的之后指明正确路径即可。
# 这样就添加了redis到spark中去, 后面的这个路径只要写redis.zip所在路径即可
spark.sparkContext.addPyFile("/opt/bigdata/spark/spark2.2/python/lib/redis.zip")
import redis
这样,后面执行的时候就不会报找不到redis的错了,其他也是包同理,同样的解决方法。还要注意一点是我这里的spark是创建的一个session对象, 如果是直接用的sparkContext对象的话,可以直接addPyFile, sparkSession的话没有这个函数的。
到这里第一个问题解决了,再次运行,迎来了第二个报错:redis.exceptions.DataError: Invalid input of type: ‘list‘. Convert to a bytes, string, int or float, 这个一搜很容易搜到了, 原因是redis的版本太高,果然我的从conda list中看了一下,3.5, 需要降到2.多,于是乎卸掉了anaconda中的redis(这里看好,是卸载包,别把搭建的redis服务环境卸掉),进入bigdata_env环境, 执行两个:
pip uninstall redis
pip install redis==2.10.6
然后还得把这个新的redis包压缩加入spark中,和上面的一样了。 这样解决了第二个报错。
再次运行,结果又来个一个报错:Redis (error) NOAUTH Authentication required, 这个原因是因为redis之前安装的时候是带了密码的(上次搭建环境的时候玩过火了,搞了个密码,结果这里没法输入密码了), 这个解决的话非常简单了, 修改redis.conf文件, 然后把密码那一行注释掉,重启redis服务器即可。这个具体的可以参考搭建环境的那一篇文章了。
至此,就可以再次运行,就搞定了,哈哈,一上午下来,三个报错解决掉,舒服啊,下面看下成果了:
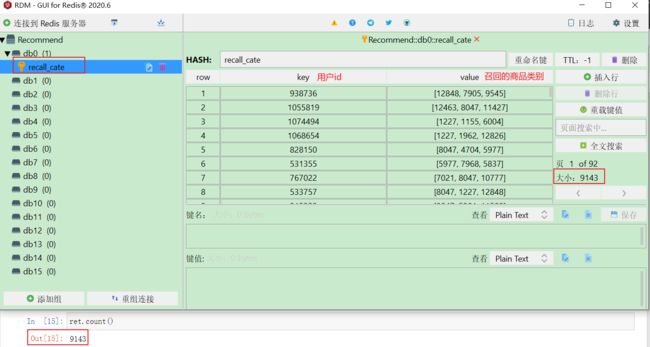
当时看视频里面讲到这里的时候,一直对召回结果如何保存到redis或者数据库感到好奇,如今终于把这层雾拨开了,redis是这样,数据库应该原理也差不多。召回结果保存起来之后, 在后面排序的时候,就能从redis中把候选商品读取出来,然后映射到候选广告上,就能使用排序模型进行广告的点击率预测任务了。
5.2 对品牌的打分召回
前面已经说过, 虽然我们排序部分的任务是广告的点击率预测,但是召回模块根据给定的数据我们没法直接召回候选广告,只能是召回和广告相关的物品的类别或者是品牌来,再用这个映射到候选广告上去, 5.1的整体流程就是如何对每一用户召回候选的商品类别(cate_id),我们也可以召回商品的品牌(brand_id), 这个就不在这里详细赘述了,因为代码逻辑一模一样,代码只需基于上面的改动
brand_rating_df = cate_count_df.rdd.map(process_row).toDF(["userId", "brandId", "rating"])
后面创建ALS模型的时候改成brandId就OK了。 文章整理只整理原理,不整理重复代码,所以这里参考上面的就好啦。
6. 总结
这篇文章到这里就结束了, 主要介绍的内容就是召回部分, 用的数据表是behavior_logs.csv, 基于用户的行为,创建了ALS模型(协同过滤), 对商品的类别和品牌进行了候选召回,并存入到了Redis数据库中去。
这篇文章学习到的内容就是数据采样(这个是硬件的上限), pandas成块读取大数据文件,SparkSql中的DataFrame, 数据透视和转换,pyspark的配置, pyspark运行python脚本,jupyter notebook运行pyspark代码,spark ml的ALS模型, 召回结果如何导入Redis等, 收获很多,感受是分布式的这套机制和单机就推荐系统的处理逻辑是一致的,不同的是分布式的这套机制各个机器之间要相互配合, 于是就出现了一些各个机器之间通信和配合的问题, 用到的数据处理工具原理是一样的,但是使用方式上,名称上就不太一样了。分布式这里是基于spark了(因为它能解决通信和配合问题), 单机的pandas类似于这里的SparkSQL 的DataFrame, 单机的sklearn或者一些推荐模型类似于这里的Spark ml库里面的模型。 所以掌握了算法原理还是一通百通,模型和算法本身的原理会了,单机 or 分布式用起来依然是掉包操作啊,涉及到掉包的东西很快就可以通过查资料学会,然后用到工程,但算法的原理往往才是王道,好的算法才是根本。 所以工程和算法要两手抓,两手都要硬,哈哈。
好了,技术文中说的又有点多了, 停住,然后探索下面的了, 召回结束之后, 就是训练排序模型,对于候选的广告进行更加准确的预测和排序了,排序部分会加入更多的信息, 还需要进行数据的进一步处理和清洗,然后再是排序模型, 下一篇里面是为排序模型做数据的准备工作, 这里结尾依然是吴军老师的一句话: 信息量代表着不确定性的大小,信息量越大,不确定性就越小,熵就越小,我们就越容易搞清楚。 排序部分就是通过增加信息量,让不确定性越来越小的,哈哈,对上了, Rush