VOS论文阅读 :Kernelized Memory Network for Video Object Segmentation(2020 ECCV)
[论文阅读 2020 ECCV]Kernelized Memory Network for Video Object Segmentation
- Semi-Supervised. KMN
- STM在VOS任务中的问题
- KMN Contribution
-
- Hide-and-Seek
- Memory Read
-
- STM Memory Read
- Kernelized Memory Read
- Kernelized Memory Net
- Two Stage Training
- Result
-
- Performance
- Ablation study
- Qualitative Results
没有按照全文翻译的方式对整个论文进行翻译,仅仅记录了自己在阅读论文时一些受到启发、比较重要的内容,将论文的 motivation和 contribution都很详尽地记录下来,中间有很多自己的想法,希望大家批评指正。
Semi-Supervised. KMN
在 Video object segmentation任务中根据在测试时是否使用视频序列中第一帧的精确标注的mask,将任务区分为Semi-Supervised和unsupervised。
在ICCV 2019中的论文STM(Video object segmentation using space- time memory networks),获得了极高的性能表现,这篇KMN实际上是基于STM的改进,提出了一种预训练方法(在image inpainting和其他任务中被使用,首次使用在VOS任务上以提高对抗遮挡和边界模糊的能力)以及在测试时使用的Keinelized Memory Read。
arXiv:2007.08270
链接: arxiv论文地址.
STM在VOS任务中的问题
The solution (STM) is non-local, but the problem (VOS) is predominantly local .
STM方法是非局部的,但是在VOS任务中target的匹配通常是局部的,因为在全局中存在很多相似物体。
The memory read operation of STM has two inherent problems. First, every grid in the query frame searches the memory frames for a target object. There is only Query-to-Memory matching in the STM. Thus, when multiple objects in the query frame look like a target object, all of them can be matched with the same target object in the memory frames. Second, the non-local matching in the STM can be ineffective in VOS, because it overlooks the fact that the target object in the query should appear where it previously was in the memory frames.
STM 的存储器读取操作有两个固有的问题。 首先,查询帧中的每个网格都在存储帧中搜索目标对象。 STM中只有“Query-to-Memory”匹配。 因此,当查询帧中的多个对象看起来像目标对象时,所有这些对象都可以与存储框架中的相同目标对象进行匹配。 其次,STM中的non-local matching在VOS中可能无效,因为它忽略了以下事实:Query中的目标对象应出现在存储帧中以前的位置。(因为受限于速度和存储空间,STM最终选择了间隔五帧将内容保存进Memory中,但是希望当前帧中target object的每个pixel都在memory中出现过,以更好的执行匹配)
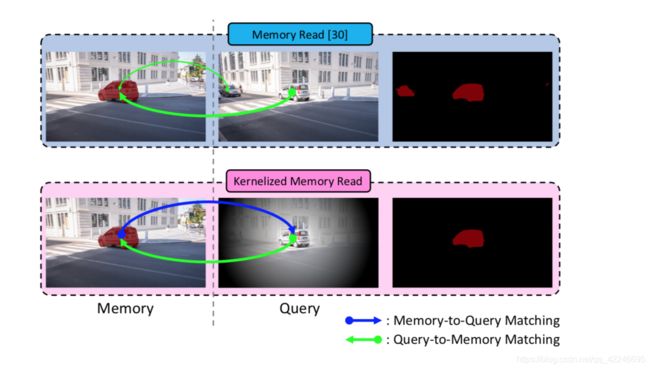
如图所示,在之前VOS任务在处理DAVIS等VOS视频数据集时候提出了假设当前帧和前一帧的运动变化有限,所以VOS任务(高度移动等除外)是类似于local的,即相邻帧的target object大概在同一个区域里,在使用Mermory与Query匹配的过程中,在Memory中target object是确定的,但是Query中存在多个物体(两辆车),所以Query的全局与Mermory进行匹配,这是no-local的,并且产生了无效匹配。
KMN Contribution
Contributions of this paper can be summarized as follows. First, KMN is developed to reduce the non-locality of the STM and make the memory network more effective for VOS. Second, Hide-and-Seek is used to pre-train the KMN on static images. In the kernelized memory read of KMN. however, both Query-to-Memory matching and Memory-to-Query matching are conducted.
KMN的两个贡献:使用kernelized减少了STM的非局部性,并且使记忆网络对于VOS任务更加高效,并且使用了Hide-and-Seek策略在静态数据集上进行预训练。在KMN中同时包含了Query-to-Memory matching和Memory-to-Query matching。
Hide-and-Seek
Before being trained on real videos, our KMN is pre-trained on static images :use the Hide-and-Seek strategy in pre-training to obtain the best possible results in handling occlusions and segment boundary extraction.
在使用真实视频训练之前,KMN在静态数据集上进行与训练,使用Hide-and-Seek策略来进行预训练从而在处理遮挡和提高分割边界的准确率。
The Hide-and-Seek strategy was initially developed for weakly supervised object localization, but we used it to pre-train the KMN. This provides two key benefits. First, Hide-and-Seek achieves segmentation results that are considerably robust to occlusion. Second, Hide-and-Seek is used to refine the boundary of the object segment. Hide-and-seek appears to provide instructive supervision for clear and precise cuts for objects .
HAS策略首先被应用在弱监督来寻找物体位置。在训练时使用随机的黑块对物体进行遮挡,并能带来两个好处:实现了分割结果对遮挡的鲁棒性,并且细化对象分割边界。可以为精确清晰分割提供一定的指导。
Training object localization in a weakly supervised manner using intact images leads to poor localization by finding only the most salient parts of the objects. As a result, we achieved comparable performance to the other offline-learning approaches, even when we trained only on the static images. Hide-and-Seek addresses the problem by generating clean boundaries:Difficulties in segmentation near object boundaries .
使用完整图像以弱监督的方式训练对象定位会导致仅找到对象的最显着部分而导致较差的定位。 而使用该策略仅在静态图像上进行训练,我们也可以达到与其他离线学习方法相当的性能。
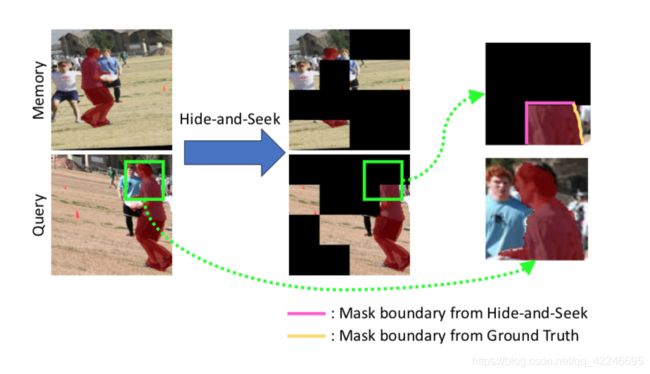
使用静态数据集预训练VOS网络的方法是从单个静态图像综合生成带有前景对象蒙版的视频,将随机仿射变换应用于静态图像和相应的对象蒙版可以生成合成视频。 然而,从静态图像合成生成视频的问题在于,在生成的视频中不会发生目标对象的遮挡。 模拟视频不能通过预训练来解决VOS中常见的遮挡问题。 “Hide-and-Seek”策略用于合成生成具有遮挡的视频。 一些区域使用黑色被随机遮掩,并且在训练样本中对target生成了随机遮挡(文章中仅考虑方形遮挡物,但可以采用任何形状)。
大多数分割数据集在对象边界附近都包含不准确的gt(在19年的一篇论文中也解决了这个问题), 用正确的mask预训练KMN可以有效地提高性能,而不正确的掩码会导致性能下降。在“预训练” KMN中使用“Hide-and-Seek”策略可以获得更清晰、准确的对象分割边界 。在上图中,Mask在跑步者的头部边界不准确。 但是,“Hide-and-Seek”会创建清晰的对象边界(这里的清晰边界是指通过黑色遮挡,形成的清晰边界,如图中粉色边界)。
Memory Read
首先介绍一下STM Memory Read,再介绍一下论文中提到的改进后的Kernelized Memory Read using 2D Gaussian kernels。
STM Memory Read
q为Query key中的一点,Q:H x W x 8/C
p为Memory key中的一点,M: T x H x W x 8/C
求p和q之间的相似度矩阵,即HW x 8/C · 8/C x HWT,可以求出Query key中每个点与Memory key中的所有帧的每个点的相似度矩阵:
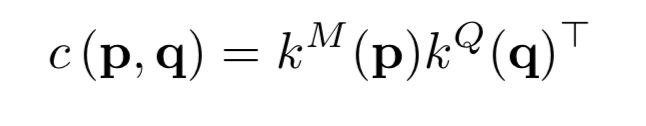
利用softmax将相似度矩阵归一化,并将对应pq的相似度与Memory value中p点对应的值相乘得到结果,再与query value concat在一起,得到最终结果:
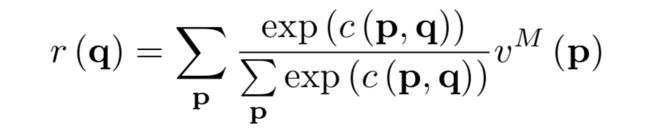
流程图:
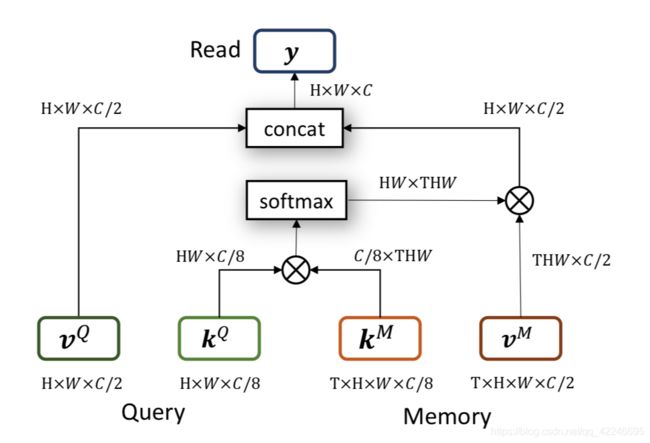
Kernelized Memory Read
与STM一样计算相似度矩阵:
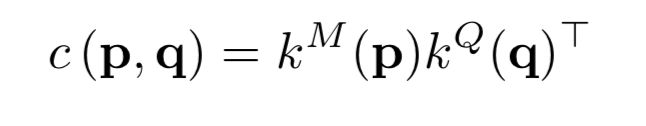
for each grid p in the memory frames, the best-matched query position ,对每一个memory中的p点,找到最匹配的query key中q点的位置
a Memory-to-Query matching
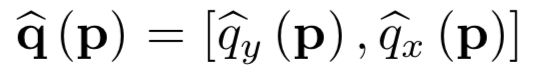
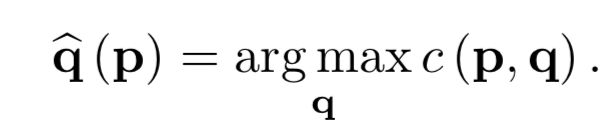
以确定的最匹配q点为中心,生成对应的2d高斯核;因为共有THW个p点,对应每个p点以最匹配的q点为中心,产生一个2d的高斯核分布H x W
得到g:T x H x W x H x W
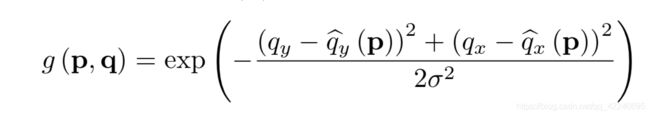
使用高斯核:
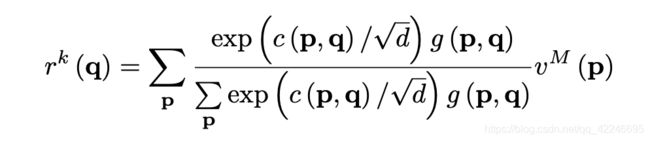
d is the channel size of the key ,比例因子,防止softmax中的参数变大,或者等效地,防止softmax变得饱和。
流程图:
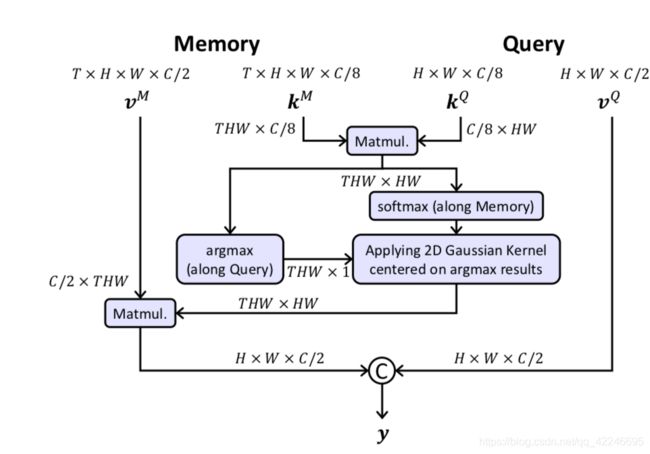
Kernelized Memory Net
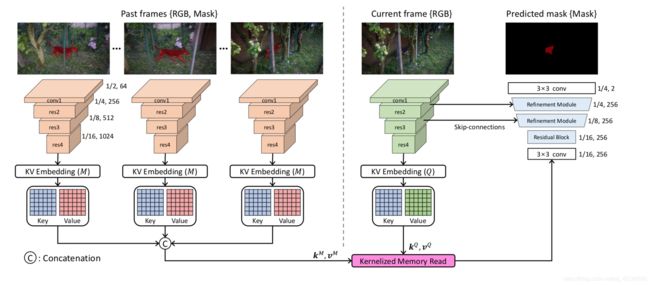
the current frame is used as the query, while the past frames with the predicted masks are used as the memory. Two ResNet50 are employed to extract the key and value from the memory and query frames, and use two same embedded layer, the weights are not shared. In memory, the predicted (or given) mask input is concatenated with the RGB channels. Then, the key and value features of the memory and the query are embedded via a convolutional layer from the res4 feature , which has a 1/16 resolution resolution with respect to the input image.
当前帧被使用作为Q,而过去的帧和预测出的mask作为M。任务的backbone使用两个不共享参数的ResNet50提取Query和Memory特征,并且使用res4的特征送入embedding layer(same,但不共享参数)提取embedding feature(key,value),feature map尺寸为输入图片分辨率的1/16.
The correlation map between the query and memory is generated by applying the inner product to all possible combinations of key features in the query and memory. From the correlation map, highly matched pixels are retrieved through a kernelized memory read operation, and the corresponding values of the matched pixels in the memory are concatenated with the value of the query. Subsequently, the concatenated value tensor is fed to a decoder consisting of a residual block and two stacks of refinement modules. The refinement module is the same as that used in STM. We recommend that the readers refer to [30] for more details about the decoder.
correlation map由query key和memory key对所有可能的结合求内积,并通过kernelized memory read operation得到置信度高的匹配点,并且和相对应的value结合,并和query value concat到一起,送入一个residual block和两个堆叠的refinement modules。
Two Stage Training
divide the training stage into two phases: one for pre-training on the static images and another for the main training on VOS datasets composed of video sequences.
1、generated three frames using a single static image by randomly applying rotation, flip, color jittering, and cropping, similar to STM. We then used the Hide-and-Seek framework. We first divided the image into a 24 × 24 grid, which has the same spatial size as the key feature. Each cell in the grid had a uniform probability to be hidden. We gradually increased the probability from 0 to 0.5.
2、main training, followed the STM training strategy. We sampled the three frames from a single video. They were sampled in time-order with intervals randomly selected in the range of the maximum interval. In the training process, the maximum interval is gradually increased from 0 to 25.
整个训练过程分为两个阶段:
1、先在静态数据集上使用‘Hide-and-Seek’策略:通过随机应用旋转、翻转、色彩抖动和裁剪将单个动态图像生成3帧模拟视频,并将图像切分为24*24个grid,和key feature的空间尺寸相同。每个grid以相同的概率被随机遮挡,训练过程中概率从0提升到0.5.
2、在VOS数据集上训练,根据STM的训练策略,从单视频采样3帧,按时间顺序在最大间隔范围内随机选择间隔进行采样。在训练过程中,最大间隔从0逐渐增加到25。
For both training phases, we used the dynamic memory strategy. To deal with multi-object segmentation, a soft aggregation operation was used. Note that the Gaussian kernel was not applied during training. Because the argmax function, which determines the center point of the Gaussian kernel, is a discrete function, the error of the argmax cannot be propagated backward during training. Thus, if the Gaussian kernel is used during training, it attempts to optimize networks based on the incorrectly selected key feature by argmax, which leads to performance degradation.
Other training details are as follows: randomly resize and crop the images to the size of 384 × 384, use the mini-batch size of 4, minimize the cross-entropy loss for every pixel-level prediction, and opt for Adam optimizer [19] with a fixed learning rate of 1e-5.
小细节:
1、在训练过程中,使用了STM中的dynamic memory strategy
2、为了处理multi-object segmentation任务,使用了STM中的soft aggregation operation
3、图像尺寸通高随机resize和crop至384*384,minibatch = 4,Adam optimizer with lr 1e-5
4、高斯核不用在训练过程中,因为使用argmax函数来确定高斯核的中心点,但是argmax函数是离散函数,所以训练过程中argmax的损失无法通过反向传播
Result
Performance
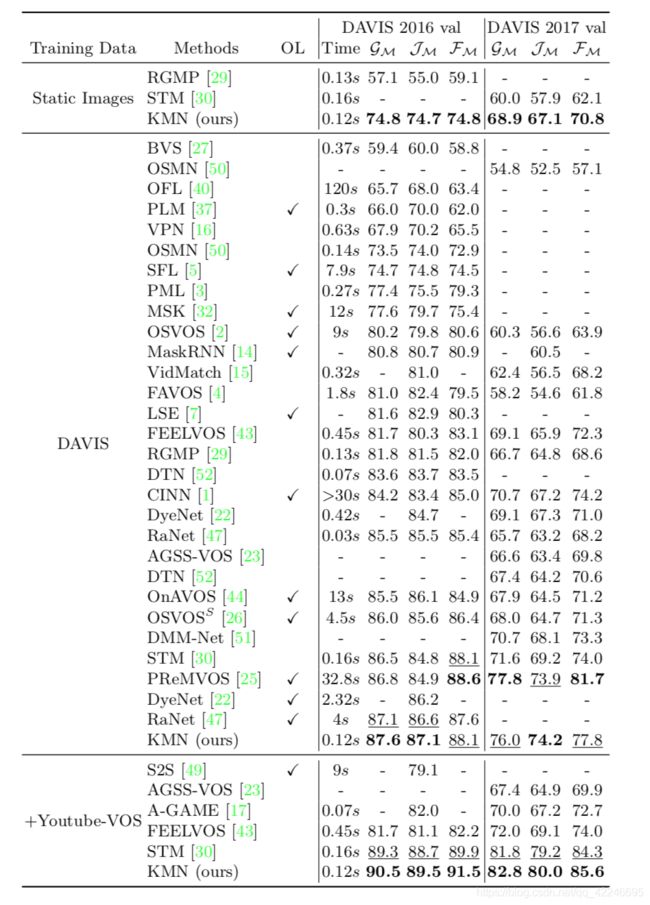
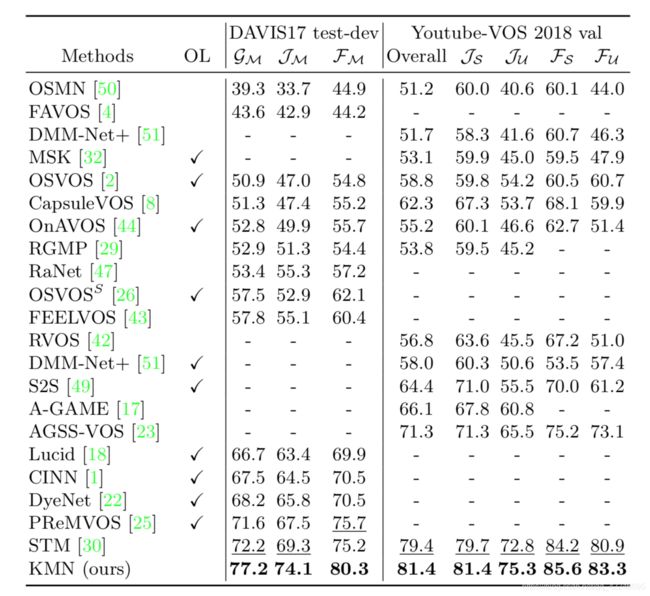
因为上述数据集的测试集可见,作者在两个测试集不可见的数据集Davis2017 test-ev和Youtube-VOS 2018 val上测试。(Youtube-VOS 2018 is the largest video object segmentation dataset. It contains 4,453 video sequences with multiple targets per video. )
Ablation study
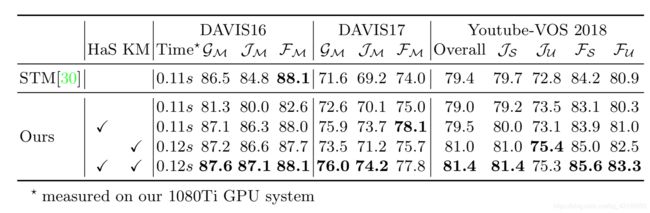
‘HaS’ and ‘KM’ indicate the use of Hide-and-Seek pre-training and kernelized memory read operation. Note that we did not use additional VOS training data for the ablation study. Only either DAVIS or Youtube-VOS is used, depending on the target evaluation benchmark.
Qualitative Results
所有的网络均在DAVIS上训练,可以观察到KMN方法可以很好地处理快速运动(变形)、严重遮挡、相似物体等情况。

和STM在图像质量上的比较:
在文章的最后,展示了使用Has预训练的方法所带来的边界质量上的改善。