【论文笔记】Recommendations for Datasets for Source Code Summarization
Recommendations for Datasets for Source Code Summarization
文章目录
- Recommendations for Datasets for Source Code Summarization
-
- 摘要
- 1 INTRODUCTION
- 2 RELATED WORK
- 3 DATASET PREPARATION
-
- 3.1 RESEARCH QUESTIONS
- 3.2 METHODOLOGY
- 3.3 DATASET CHARACTERISTICS
- 4 EXPERIMENTAL RESULT & CONCLUSION
-
- 4.1 RQ1:Splitting Strategy
- 4.2 RQ2:Removing Autogen. Code
- 5 DISCUSSION
- 6 DOWNLOADABLE DATASET
摘要
源代码总结任务受限于数据集:缺乏社区标准的数据集使得研究结果混乱而不能重复。
1 INTRODUCTION
绝大多数代码总结技术都是对最初设计用于解决NLP问题的技术的改进。
但缺乏像NLP那样庞大精良的数据集;缺乏标准数据集使结果难以解释和复制。
本文数据集组成:2.1M的java方法以及对应java方法的一句话描述。
2 RELATED WORK
- heuristic/template-based
- data-driven
- AI-based
3 DATASET PREPARATION
基于LeClair 的数据集。从51M方法中,去除方法长度>100 、注释长度 > 13 和 < 3 的内容,最后得到21M的数据集。
3.1 RESEARCH QUESTIONS
数据集量化研究:
- 数据集通过方法分割和项目分割之间的影响
- 去除自动生成的 JAVA 方法的影响
RQ1 What is the effect of splitting by method versus splitting by project?
RQ2 What is the effect of removing automatically generated Java methods?
RQ1
单纯地把Method按比例分为训练、测试、验证集,可能导致同一个项目的代码同时存在于测试集和训练集中,来自同一项目的方法中可能使用了类似的词汇表和代码模式,还有重载方法重复出现的问题。
因此,本文按照项目分割数据集:把JAVA项目分成 训练/验证/测试组。
RQ2
自动生成的JAVA方法存在大多数JAVA项目中,造成不同项目之间这部分方法的极大相似性。(Shimonaka et al., 2016) 提出通过搜索不区分大小写的“generated by”过滤自动生成方法。(A neural model for generating natural language summaries of program subroutines. )表示可以去除绝大多数的自动生成代码。
但这只是理论方法,具体有待验证。
3.2 METHODOLOGY
RQ1
使用标准NMT
算法对这两种分割进行验证(项目vs方法)。两种划分方法都随机生成了4个数据集。
BP:split by project
BF:split by function

NMT算法采用attendgru (论文:A neural model for generating natural language summaries of program subroutines. )
用attendgru在每个数据集上训练,选择性能最好的模型。attendgru配置与LeClair中一样,但输出的词汇表缩减到了10k以降低模型尺寸。
RQ2
类似RQ1,随机创建4个按project划分的数据集,并且去除其中的自动生成代码。把这一结果与RQ1中随机BP数据集的结果进行比较。
3.3 DATASET CHARACTERISTICS
数据集可能会影响研究人员设计代码总结算法。针对此有3个观察。
第一个观察:
首先,相比起在书本(自然语言)中,单词在代码中重复出现的概率更高,有更多的单词重复使用,只有较少的(22%)单词仅出现一次,通常使用3次以上:

同时,每个文档出现的单词的模式是相似的,即使代码中的单词是重复的,它们也尝尝是在相同的方法中重复,而不是在不同的方法中重复。这与算法中的dictionary息息相关。应用于代码摘要的算法需要容忍相同单词的多次出现。

为了比较源代码、注释、自然语言数据集,本文token化所有数据:移除所有特殊字符,全部小写,把源代码按照驼峰命名规则分割成token。
第二个观察:
JAVA method 往往比注释更长,如下图c 、d 。
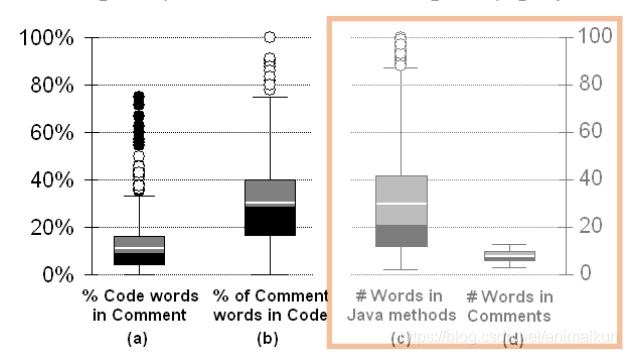
许多代码摘要工具都从NMT算法衍生而来,为类似的编码器/解码器序列长度设计的。像RNN这样的算法对序列长度敏感,可能不是现成的最佳选择。
第三个观察:
方法和注释的单词往往有重合,但大多数(70%)代码总结注释的单词没有出现在代码方法中,如上图a、b。
这种情况使得代码总结问题变得相当困难,因为注释中的单词代表高级概念,而源代码中的单词代表低级实现细节——这种情况被称为“概念分配问题”。
这使得代码总结算法不能像典型的NMT设置中那样学习单词词典,也不能像自然语言总结工具那样从方法中选择总结单词。
代码总结算法必须学会从代码细节中识别概念,并为这些概念指定高级术语。
4 EXPERIMENTAL RESULT & CONCLUSION
4.1 RQ1:Splitting Strategy
我们观察到,当按方法分割而不是按项目分割时,BLEU得分会有一个很大的“假”提升

如上图所示,这一提升为假的原因:测试集和训练集有同样的function,造成测试数据泄露到训练、验证数据。这是一个应该尽量避免的问题。
下图为在每个随机分割的数据集上的实验结果:

| average | |
|---|---|
| BF | 23.02 |
| BP | 17.41 |
4.2 RQ2:Removing Autogen. Code
我们同样发现,当自动生成的代码没有被移除时,同样有BLEU提升的现象,但比起RQ1中的提升小得多。
当不删除自动生成的代码时,基线性能增加到18 BLEU,并且它的变化取决于分割方式(一些项目比其他项目有更多的自动生成的代码)。
建议还是删除自动生成的代码,因为确实对实验结果造成了影响。
5 DISCUSSION
本文贡献:1. 讨论了2种分割方式对模型效果的影响。 2. 提供了一个具有2.1M 个对的JAVA方法+一句话描述数据集,以一种cleaned和tokenized的格式呈现为训练集、验证集、测试集。
6 DOWNLOADABLE DATASET
数据集情况:
| Dataset | Methods | Comments |
|---|---|---|
| Raw Dataset | 51,841,717 | 7,063,331 |
| Filtered Dataset | 2,149,121 | 2,149,121 |
| Tokenized Dataset | 2,149,121 | 2,149,121 |
Raw Dataset:McMillan 使用工具收集的数据集,包括每个方法的文件名、方法注释、开始/结束行
Filtered Dataset : 删除了自动生成的源代码文件,以及所有没有关联注释的方法,源代码和注释字符串没有进行预处理
Tokenized Dataset : 基于Filtered Dataset 进行预处理,源代码的预处理(特殊字符删除,驼峰分离,小写)。注释预处理(javadoc的第一行小写,去掉了特殊字符)
前两行来自raw/processed datasets后两行为对前两个分别进行tokenized的结果。

数据集下载链接:http://leclair.tech/data/funcom/