深入理解 Node.js 中的 Worker 线程
多年以来,Node.js 都不是实现高 CPU 密集型应用的最佳选择,这主要就是因为 JavaScript 的单线程。作为对此问题的解决方案,Node.js v10.5.0 通过 worker_threads 模块引入了实验性的 “worker 线程” 概念,并从 Node.js v12 LTS 起成为一个稳定功能。本文将解释其如何工作,以及如何使用 Worker 线程获得最佳性能。
Node.js 中 CPU 密集型应用的历史
在 worker 线程之前,Node.js 中有多种方式执行 CPU 密集型应用。其中的一些为:
-
使用 child_process 模块并在一个子进程中运行 CPU 密集型代码
-
使用 cluster 模块,在多个进程中运行多个 CPU 密集型操作
-
使用诸如 Microsoft 的 Napa.js 这样的第三方模块
但是受限于性能、额外引入的复杂性、占有率低、薄弱的文档化等,这些解决方案无一被广泛采用。
为 CPU 密集型操作使用 worker 线程
尽管对于 JavaScript 的并发性问题来说, worker_threads 是一个优雅的解决方案,但其并未给 JavaScript 本身带来多线程特性。相反, worker_threads 通过运行应用使用多个相互隔离的 JavaScript workers 来实现并发,而 workers 和父 worker 之间的通信由 Node 提供。听懵了吗? ♂️
在 Node.js 中,每一个 worker 将拥有其自己的 V8 实例及事件循环(Event Loop)。但和 child_process 不同的是,workers 不共享内存。
以上概念会在后面解释。我们首先来大致看一眼如何使用 Worker 线程。一个原生的用例看起来是这样的:
// worker-simple.js
const {Worker, isMainThread, parentPort, workerData} = require('worker_threads');
if (isMainThread) {
const worker = new Worker(__filename, {workerData: {num: 5}});
worker.once('message', (result) => {
console.log('square of 5 is :', result);
})
} else {
parentPort.postMessage(workerData.num * workerData.num)
}在上例中,我们向每个单独的 workder 中传入了一个数字以计算其平方值。在计算之后,子 worker 将结果发送回主 worker 线程。尽管看上去简单,但 Node.js 新手可能还是会有点困惑。
Worker 线程是如何工作的?
JavaScript 语言没有多线程特性。因此,Node.js 的 Worker 线程以一种异于许多其它高级语言传统多线程的方式行事。
在 Node.js 中,一个 worker 的职责就是去执行一段父 worker 提供的代码(worker 脚本)。这段 worker 脚本将会在隔绝于其它 workers 的环境中运行,并能够在其自身和父 worker 间传递消息。worker 脚本既可以是一个独立的文件,也可以是一段可被 eval 解析的文本格式的脚本。在我们的例子中,我们将 __filename 作为 worker 脚本,因为父 worker 和子 worker 代码都在同一个脚本文件中,由 isMainThread 属性决定其角色。
每个 worker 通过 message channel 连接到其父 worker。子 worker 可以使用 parentPort.postMessage() 函数向消息通道中写入信息,父 worker 则通过调用 worker 实例上的 worker.postMessage() 函数向消息通道中写入信息。看一下图 1:
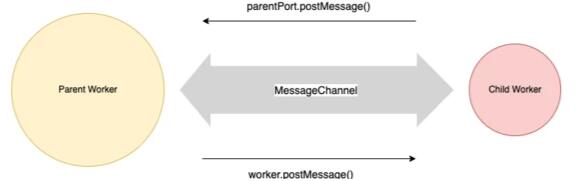
一个 Message Channel 就是一个简单的通信渠道,其两端被称作 ‘ports’。在 JavaScript/NodeJS 术语中,一个 Message Channel 的两端就被叫做 port1 和 port2
Node.js 的 workers 是如何并行的?
现在关键的问题来了,JavaScript 并不直接提供并发,那么两个 Node.js workers 要如何并行呢?答案就是 V8 isolate 。
一个 V8 isolate 就是 chrome V8 runtime 的一个单独实例,包含自有的 JS 堆和一个微任务队列。这允许了每个 Node.js worker 完全隔离于其它 workers 地运行其 JavaScript 代码。其缺点在于 worker 无法直接访问其它 workers 的堆数据了。
扩展阅读: JS在浏览器和Node下是如何工作的?
由此,每个 worker 将拥有其自己的一份独立于父 worker 和其它 workers 的 libuv 事件循环的拷贝。
跨越 JS/C++ 的边界
实例化一个新 worker、提供和父级/同级 JS 脚本的通信,都是由 C++ 实现版本的 worker 完成的。在成文时,该实现为 worker.cc (https://github.com/nodejs/node/blob/921493e228/src/node_worker.cc)。
Worker 的实现通过 worker_threads 模块被暴露为用户级的 JavaScript 脚本。该 JS 实现被分割为两个脚本,我将之称为:
-
初始化脚本 worker.js— 负责初始化 worker 实例,并建立初次父子 worker 通信,以确保从父 worker 传递 worker 元数据至子 worker。(https://github.com/nodejs/node/blob/921493e228/lib/internal/worker.js)
-
执行脚本 worker_thread.js— 根据用户提供的 workerData 数据和其它父 worker 提供的元数据执行用户的 worker JS 脚本。(https://github.com/nodejs/node/blob/921493e228/lib/internal/main/worker_thread.js)
图 2 以更清晰的方式解释了这个过程:
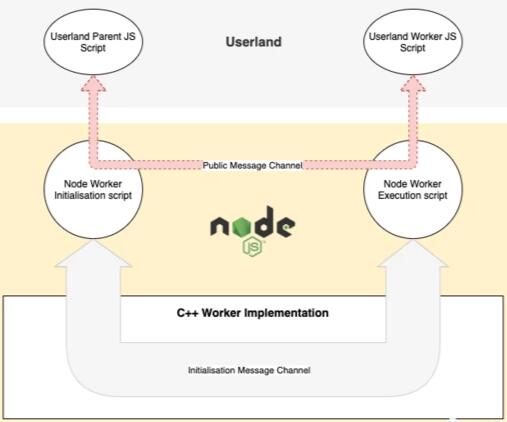
基于上述,我们可以将 worker 设置过程划分为两个阶段:
-
worker 初始化
-
运行 worker
来看看每个阶段都发生了什么吧:
初始化步骤
-
用户级脚本通过使用 worker_threads 创建一个 worker 实例
-
Node 的父 worker 初始化脚本调用 C++ 并创建一个空的 worker 对象。此时,被创建的 worker 还只是个未被启动的简单的 C++ 对象
-
当 C++ worker 对象被创建后,其生成一个线程 ID 并赋值给自身
-
同时,一个空的初始化消息通道(让我们称之为 IMC )被父 worker 创建。图 2 中灰色的 “Initialisation Message Channel” 部分展示了这点
-
一个公开的 JS 消息通道(称其为 PMC )被 worker 初始化脚本创建。该通道被用户级 JS 使用以在父子 worker 之间传递消息。图 1 中主要描述了这部分,也在图 2 中被标为了红色。
-
Node 父 worker 初始化脚本调用 C++ 并将需要被发送到 worker 执行脚本中的 初始元数据 写入 IMC 。
什么是初始元数据?即执行脚本需要了解以启动 worker 的数据,包括脚本名称、worker 数据、PMC 的 port2 ,以及其它一些信息。
按我们的例子来说,初始化元数据如:
:phone: 嘿!worker 执行脚本,请你用 {num: 5} 这样的 worker 数据运行一下 worker-simple.js 好吗?也请你把 PMC 的 port2 传递给它,这样 worker 就能从 PMC 读取数据啦。
下面的小片段展示了初始化数据如何被写入 IMC:
const kPublicPort = Symbol('kPublicPort');
// ...
const { port1, port2 } = new MessageChannel();
this[kPublicPort] = port1;
this[kPublicPort].on('message', (message) => this.emit('message', message));
// ...
this[kPort].postMessage({
type: 'loadScript',
filename,
doEval: !!options.eval,
cwdCounter: cwdCounter || workerIo.sharedCwdCounter,
workerData: options.workerData,
publicPort: port2,
// ...
hasStdin: !!options.stdin
}, [port2]);代码中的 this[kPort] 是初始化脚本中 IMC 的端点。尽管 worker 初始化脚本向 IMC 写入了数据,但 worker 执行脚本仍无法访问该数据。
运行步骤
此时,初始化已告一段落;接下来 worker 初始化脚本调用 C++ 并启动 worker 线程。
-
一个新的 V8 isolate 被创建并被分配给 worker。前面讲过,一个 “v8 isolate” 就是 chrome V8 runtime 的一个单独实例。这使得 worker 线程的执行上下文隔离于应用代码中的其它部分。
-
libuv被初始化。这确保了 worker 线程保有其自己独立于应用中的其它部分事件循环。
-
worker 执行脚本被执行,并且 worker 的事件循环被启动。
-
worker 执行脚本调用 C++ 并从 IMC 中读取初始化元数据。
-
worker 执行脚本执行对应文件或代码(在我们的例子中就是 worker-simple.js ),以作为一个 worker 开始运行。
看看下面的代码片段,worker 执行脚本是如何从 IMC 读取数据的:
const publicWorker = require('worker_threads');
// ...
port.on('message', (message) => {
if (message.type === 'loadScript') {
const {
cwdCounter,
filename,
doEval,
workerData,
publicPort,
manifestSrc,
manifestURL,
hasStdin
} = message;
// ...
initializeCJSLoader();
initializeESMLoader();
publicWorker.parentPort = publicPort;
publicWorker.workerData = workerData;
// ...
port.unref();
port.postMessage({ type: UP_AND_RUNNING });
if (doEval) {
const { evalScript } = require('internal/process/execution');
evalScript('[worker eval]', filename);
} else {
process.argv[1] = filename; // script filename
require('module').runMain();
}
}
// ...是否注意到以上片段中的 workerData 和 parentPort 属性被指定给了 publicWorker 对象呢?后者是在 worker 执行脚本中由 require('worker_threads') 引入的。
这就是为何 workerData 和 parentPort 属性只在子 worker 线程内部可用,而在父 worker 的代码中不可用了。
如果尝试在父 worker 代码中访问这两个属性,都会返回 null 。
充分利用 worker 线程
现在我们理解 Node.js 的 worker 线程是如何工作的了,这的确能帮助我们在使用 Worker 线程时获得最佳性能。当编写比 worker-simple.js 更复杂的应用时,需要记住以下两个主要的关注点:
-
尽管 worker 线程比真正的进程更轻量,但如果频繁让 workers 陷入某些繁重的工作仍会开销巨大。
-
使用 worker 线程承担并行 I/O 操作仍是不划算的,因为 Node.js 原生的 I/O 机制是比从头启动一个 worker 线程去做同样的事更快的方式。
为了克服第 1 点的问题,我们需要实现“worker 线程池”。
worker 线程池
Node.js 的 worker 线程池是一组正在运行且能够被后续任务利用的 worker 线程。当一个新任务到来时,它可以通过父子消息通道被传递给一个可用的 worker。一旦完成了这个任务,子 worker 能将结果通过同样的消息通道回传给父 worker。
一旦实现得当,由于减少了创建新线程带来的额外开销,线程池可以显著改善性能。同样值得一提的是,因为可被有效运行的并行线程数总是受限于硬件,创建一堆数目巨大的线程同样难以奏效。
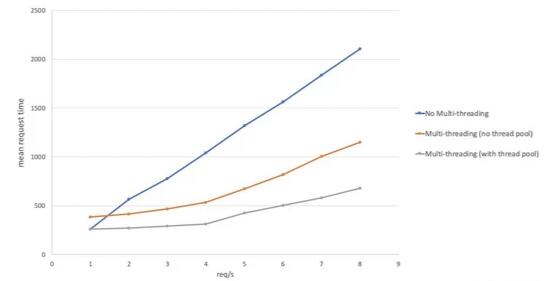
下图是对三台 Node.js 服务器的一个性能比较,它们都接收一个字符串并返回做了 12 轮加盐处理的一个 Bcrypt 哈希值。三台服务器分别是:
-
不用多线程
-
多线程,没有线程池
-
有 4 个线程的线程池
一眼就能看出,随着负载增长,使用一个线程池拥有显著小的开销。
但是,截止成文之时,线程池仍不是 Node.js 开箱即用的原生功能。因此,你还得依赖第三方实现或编写自己的 worker 池。
希望你现在能深入理解了 worker 线程如何工作,并能开始体验并利用 worker 线程编写你的 CPU 密集型应用。