高德算法大赛亚军战队经验分享:将图像信息转化为多模态理解解题
高德地图联合阿里云天池平台举办的AMAP-TECH算法大赛已经落幕。本次大赛以“基于车载视频图像的动态路况分析”为赛题,赛题来源于高德真实的业务场景。路况信息不仅影响用户选择出行路线、出行方式、预估到达的时间,对于交通管理部门和城市规划部门也有重要的价值。
相关内容
燃爆视频!高德地图首届算法大赛落幕 为未来创造更多可能!
阿里巴巴高德地图AMAP-TECH算法大赛开赛!
来自15个国家和地区的880支战队经过数轮激烈角逐后,五强战队杀入决赛。我们将把五强战队的解题思路和方案分享给大家。本次要分享的是最终获得亚军的AKAMAI有颜值战队的方案。

(北京大学教授,机器感知与智能教育部重点实验室主任查红彬为获奖团队颁奖)
战队由三位同学组成,从上图中左边第二位到第四位分别是来自西安交通大学的冉宪东,西安电子科技大学的王一杰,南京大学的仲伟渊。
核心任务
本次比赛的内容是通过车载视频图像对当前道路状况进行分类,道路状况初赛中有三类:畅通、缓行与拥堵。复赛中分为四类,增加了一类封闭。以复赛指标为例,采用的是加权F1指标。畅通、缓行、拥堵和封闭分别对应0.1,0.2,0.3,0.4的权重。
挑战和难点
本次比赛的难点与挑战我们认为有以下几点:
本次比赛的数据量较少,初赛时我们用于训练的样本数量仅有7k,其次道路场景复杂且样本不均衡,封闭与畅通占据了样本总数的86.9%,缓行和拥堵分别占了3.7%和9%。
本次比赛中可以看到畅通与缓行,缓行与拥堵其实有很大的相似之处,存在一些难样本,神经网络模型并不容易直接找到分类边界。如何更加充分利用图像序列信息是关键。
比赛分为AB榜,如何让模型在小数据场景下有更好的稳定性是十分重要的。其次,模型的扩展性(如未来添加更多的道路信息等)需要有所保障以应对更加复杂的道路场景与需求。
具体的,我们首先对数据进行探索,主要有以下几点发现:

上述三幅图中包含了天桥或商铺等,道路本身为畅通却很容易被识别为封闭。NN分类并不能很好的解决,需要检测器辅助判断。

上述两幅图虽然是畅通,但受到客观环境因素以及拍摄模糊等影响肉眼都比较难判别路况,需要做更好的数据增强与更细致的图像特征提取。

这三幅图片中路况十分相似,十分容易混淆。如这张“拥堵”图片,乍一看很像畅通,但其实远处车辆已经出现了拥堵。这种情况单张图片让模型直接分类还是比较困难的,我们需要利用序列变化信息来更好的对图片进行分类。
算法概要
综上所述,我们认为本次比赛不是一个单纯CV问题,可以认为是一个多模态理解问题。虽然是图片,但我们可以通过目标检测生成一个包含车辆数量、车辆坐标、行人等信息的表。这样数据就包含了图片信息与表格信息,所以我们认为也可以称为多模态。例如区分拥堵和缓行,序列中缓行前方车辆数目可能存在相对位置的变化,但“拥堵”前方车辆是十分固定的。这其实可以很好的通过序列特征提取做到。所以,我们整体的方案框架如下图:
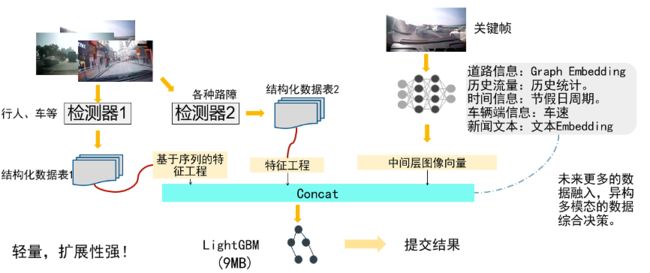
我们的最终方案采用的是用LightGBM做最终的分类器,分别通过Yolov5提取检测特征,并针对检测结果进行特征工程,提取序列刻画的统计特征,ResNeXT101_32x8d_wsl的中间层输出作为图片的Embedding特征。将上述两部分特征拼接作为lgb的输入。这种方案当未来有更多数据信息时可以很好的进行继续扩展提升模型的性能。具体处理如下。
图像特征向量提取
首先需要抽取关键帧图像的语义信息作为路况特征,这些高层的抽象信息有很好的鲁棒性,分类器利用它进行决策可以忽略不同域中车辆,行人等对象的差别,有利于模型的泛化。

具体来说,我们的方法是在数据集上训练了一个图像分类模型,并利用它的中间层输出提取了图像的语义表示向量。
数据增强
由于数据量小,场景差异大,噪声多。我们采用多样的图像增强方法,让模型更好的学习数据,减少对光照,街景等路况无关信息的拟合。其中我们专门对障碍物进行了拼贴增强,就可以让模型更好的理解封闭类本身的语义。

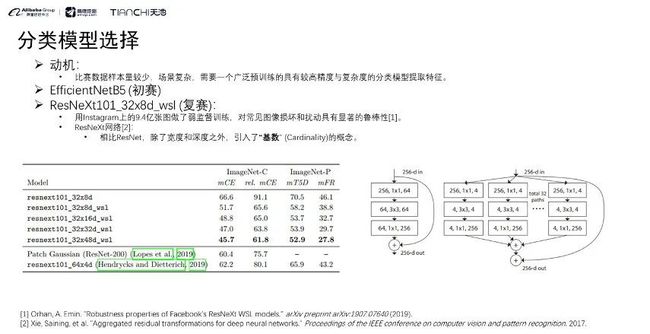
分类模型的选择
我们最终确定了ResNeXt101_32x8d_wsl作为分类的模型,它精度较高,且具有一定鲁棒性。
通过多种尝试,我们发现通过迁移学习,使用深度学习算法可以很好的提取单帧信息,但是对于序列上的信息融合,我们尝试了很多端到端的序列模型方案,算法很难在众多噪声中学习到关于路况的变化。所以针对这一维度的信息,我们决定人工构造特征来分析序列上的路况。最终我们确定了基于检测特征构造序列路况特征,以及关键帧的图像分类特征信息共同决策的方案。一举将成绩提升了几个百分点。

检测部分
检测器分为两个,第一种检测器主要检测车辆与行人等,我们直接采用Yolov5的coco预训练,并没有在比赛数据上进行任何标注微调(微调后肯定会有显著提升),由于coco原始数据中检测类别众多,所以会出现很多错误检测。我们只保留检测到的车辆、行人、卡车、自行车等交通中常见的。第二种检测器专门针对路障检测,复赛发放的数据中已经标注好了几种路障的类别,我们同样采用Yolov5进行训练。通过检测模型,我们可以输出得到每图片中检测目标的坐标信息、置信度。
检测特征工程部分

特征工程主要针对序列进行刻画,通过坐标、每张图车辆数目等在序列中的均值、方差可以有效的刻画车流的变化情况。针对路障检测我们只是用了置信度进行求和,因为路障检测与否直接取决于是否存在路障,若直接设定阈值进行count则相当于检测器对路障进行分类。而检测器本身的预测输出是存在误差的,为了防止累计误差,我们采用置信度进行求和。发现再添加特征其实效果并不好,因为特征其实都是依赖于检测器的输出,特征越多误差也被放大越多。
最后提交线上结果采用的是LightGBM五折交叉验证,因为NN同样是五折交叉验证,训练集中每一个Embedding特征都只有一种,而测试集可以预测五个Embedding,所以类似TTA的思想,我们对同一张图片用五种Embedding分别预测一遍取平均作为最终预测结果。根据加权F1给不同预测结果加权,经过线下验证得到最优权重进行提交。
