数据科学小白系列,搞清相关性与因果性,从此吵架不亏理

用相关性和因果关系的例子在生活中、工作中时有发生。也许是其他数据科学的概念看起来更专业、更高深,所以日常讲理、辩论、争吵的过程中很少被人用到。有不少看似合理的推理得到的往往是错误的因果性结论,这个情形不分行业、不分场合、不分地点的出现。为了避免出现“秀才遇见兵,有理说不清”的遭遇,为了轻松识破泼妇、流氓和无赖的“因果性”套路,彻底杜绝“人善被人欺,马善被人骑” 的尴尬,请拿起科学的武器维护自己的基本权利,一次性搞清相关性与因果性的本质。如果考虑将数据科学的思维牢牢扎根在自己的脑回路里,可以私下里多复习几遍本文的内容。
1(一)媒体报道里的失误
英国媒体报道了一项关于某地区青少年日常行为的调研,调研包括其父母是否吸烟。调查结果显示:父母吸烟的孩子更有可能表现出违法行为。调研结果似乎显示了两个变量之间的相关性,因此报纸上大写加粗的标题为“父母吸烟会导致孩子行为不端”。参与调查的教授表示,香烟包装应该带有关于社会问题的警告和突出的健康警告并列在一起。
很明显,这种假设存在许多问题。搞清相关性与因果性的第一招,相关性通常可以反过来重新思考。例如,由于看管和照顾熊孩子中的极品,其父母承受巨大压力,他们完全有可能因此而染上烟瘾。此外,可能是经济原因带来的相关性。经济状况较差的人群可能更容易吸烟,贫穷的家庭可能疏于管教孩子,导致儿童违法。因此,父母吸烟和孩子犯罪可能是贫困问题,也可能与他们的家庭之间完全没有联系,以上推理漏洞百出。我们需要注意的是:不是所有错误的因果关系的分析都没有意义,天文学家带来了另一种观点。
2(二)错了没有关系吗?
天文学家在20世纪60年代发现来自太空的高能伽马射线爆发。然而并不知道原因是什么,但是发现这些爆发的空间分布与各向同性模型(isotropic model)很相关,也就是说,爆发并非来自天空中随便任意的方向。尽管信息量如此有限,这个相关性依然推动了天体物理理论的改进,新的技术加上强大的科学仪器,再加上科学家的持之以恒,几十年的观察后,在20世纪90年代终于发现了原因。原因来自一颗巨大的恒星爆炸,然后坍缩成黑洞,这种情况在整个宇宙中偶然发生。因此,相关性推进了物理模型和太空天文仪器的改进,哪怕没有理解最初的原因。找到因果关系固然一步到位,一劳永逸,但在许多情况中,由相关性贡献价值,进而找到努力的方向也非常的重要。相关性没有因果性那么出色,但依然给科学理论和技术理论不断贡献力量。我们思考这样一个问题,如果错误理解潜在的因果关系,结果将会如何?

3(三)相关性是推荐算法的屠龙刀
同样可以看到信息搜索和在线购物中,推荐算法不仅擅长推荐,而且还非常善于为互联网创造价值。电商发现客户购买模式从而让推荐算法向用户呈现有意义的相关产品。百度搜索算法发现用户点击行为中的相关性,进而向搜索用户提供给有用的信息。这些算法模型没有直接给出用户偏好产品A和产品B的原因,但如果历史上的浏览数据和购买数据显示是相关的,算法采取行动确实是根据这种相关性,哪怕因果性完全没有帮上一点忙,全程缺席。
所以,我们需要了解因果性,数据科学家和算法工程师应该在寻找根本原因的路上不断努力,不要放弃,继续专注于在强大的预测分析中发现相关性、用好相关性、爱上相关性。
4(四)排除彻底虚假的因果关系
虚假的因果关系的套路可以理解为 “因为这个,所以因为那个”。这种错误的假设就是当两个事件一起发生时,必然会引起另一个事件。请牢记:相关性并不意味着因果关系。例如,过去150年来全球气温稳步上升,海盗数量则逐步下降。没有人会认为海盗数量的减少导致全球变暖或海盗数据增多会扭转全球变暖。通常,两个事件之间的相互关系诱使我们相信一个事件引起了另一件事件。如果有,那么这通常是巧合,或者是存在第三中因素导致你所看到的两种效应。在我们的海盗和全球变暖的例子中,全球变暖原因是工业化。虚假的因果性如果是简单的还比较容易判断,但是判断复杂情况中的虚假因果性则是一种考验。
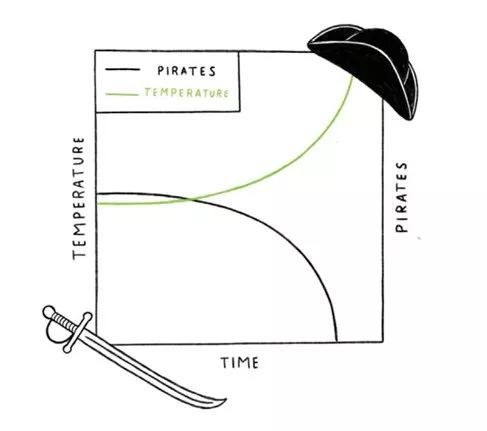
5(五)“指望不上”的随机实验
如何建立因果模型来回答诸如以下问题:
1)人为的导致全球变暖的可能性有多大?
2)是基因突变引起肺癌,还是吸烟过多诱发肺癌?
3)编程培训对程序员工资的影响是什么?
这些问题恐怕不是一句两句话能够交代清楚。需要进行因果性的分析。随机实验(random experiment)可能是进行因果性的分析最好用的方法之一。但是,随机实验往往指望不上。为什么?因为在许多情况下,实验是不可行的或不道德的,也可能是卑鄙的。现实中,会有很多障碍阻止你。
第一,钱的问题,做测试需要大量开销。假如实验是需要给消费者提供免费的新款苹果手机,那么苹果公司当然会很高兴,但是为实验出钱的人未必高兴。在不清楚因果关系时,就耗巨资做测试,很不明智。
第二,道德不允许。假设抽烟的人精神压力比不抽烟的人大。抽烟是导致压力的原因吗?如果想知道抽烟是否对精神压力产生影响,需要让正常人抽烟,这样的变态实验合适吗?

再例如历史上臭名昭著的Tuskegee梅毒实验,实验中399名患有梅毒的贫困黑人男子都没有得到及时的治疗,这样做的目的就是为了追踪疾病的进展。再例如在二战中可恶的德国纳粹对集中营的俘虏也做过类似的事情,挑选几百对双胞胎进行医学实验。部分受害者今天依然在世,带着伤病和仇恨。在今天,科技伦理规定了科技工作者应恪守的价值观念、社会责任和行为规范,阻止和防范发生如此恶劣的行为。
6(六)三招正面迎战因果关系

当随机对照试验不可能实现或者变身碎钞机的时候,因果模型如何能够提供另一种确定因果关系的方法?如何使利用观测数据而不是测试数据分析因果关系?以下三本武林秘籍供你参考。
第一招、普通回归(Ordinary regression)
如果在时间上,不可观测到的维度是不变的,可以从不可观测到的维度上分离出偏差。举一个名牌高校毕业和毕业后薪水的例子,这两个事件(X和Y)之间是否存在因果关系。

第二招、模拟实验(Simulated Control)
要模拟相关性,可以简单地构建一个因果模型,如果需要,可以添加潜在变量,进行模拟,结果数据将具有所需的相关性。具有不同因果解释的几个模型可以提供需要的相关性分析。
例如,随机对照试验(RCT)被认为是医学领域相关性分析的倚天剑。患者被随机分配接受干预或对照。可以通过比较组之间的结果来估计干预的效果,其预期因素。在估计观测数据的因果效应时,希望尽可能近似随机实验。通过从原始控制组中选择一个子样本来实现,将治疗组与观察到的协变量的分布相匹配(observed covariates)。协变量在实验的设计中是一个独立变量,或者是解释变量,不为实验者所操纵,但仍影响实验结果。有时最初的对照组不能提供足够的治疗组的匹配,需要找到一种方法来获取多个控制组的匹配结果。除了对差异进行调整观察组间的协变量,还需要区分对照组,抓住其他未观察到的控制组之间的差异。
还有一个要考虑的重点是,模拟实验中的观测数据可能缺少可对照的观测单位。这句话有些难懂,简单来说,就是最基本的观测单位(data point),比如学历调查中的一个学生,全球环境保护调查中的一个国家。很难找到前后不同的对照。同一个学生不可能有学历又没有学历,一个国家不可能既被污染,又没有被污染。更简单的说,同一个人不能同时既是抽烟者又是不抽烟者。这种情况下,最普遍的方法是使用近邻算法、k-d树算法。条件是能够在得到处理的数据中找到与在未经处理的数据组中看起来很相像的数据,然后在相似数据之间进比较。例如,在健身房找到两个爱健身的男生,A帅哥和B帅哥,同岁、相同收入,相同学历……。A帅哥抽烟,B帅哥不抽烟。假设其它条件均没有变化,比较两帅哥在一段时间内的工作压力。那么就可以得到想分析的。
第三招、工具变量(IV)
这是高级别的招式,需多加练习小心发挥,使用步骤如下,
第一步、确定配成对的因果关系(cause – effect pair)。
第二步、确定与原因相关的特征,特征是独立的,与找到的配成对的因果关系的回归分析而获得的误差无关。这个变量就是要找的工具变量。
第三步、用工具变量估计原因变量(estimate the cause variables)。
第四步、尝试用回归分析估计那对因果关系来计算实际的因果关系系数。

7(七)因果分析的应用
市场营销中的因果分析:
1.变量之间的关系并不总是线性的。例如,低于某一点,广告支出的增加可能没有影响销量。但是超过这一点,销售额可能会猛增。
2.因果关系也可以是相互作用。例如,A影响B,则B影响A,品牌经常以类似的方式相互作用。
3.存在滞后效应。例如,新广告系列的影响可能会过段时间反应在销量中。着急分析可能会得到一个非常扭曲的市场状况。

社会学中的因果分析:
1. 客观性对于社会学家有时也会强人所难,特别是当他们研究的社会现象也是自己生活的一部分时。
2. 人类行为是复杂的,特别是在个人层面预测行为很难,甚至不可能。
3. 定量社会学方法倾向于使用特定的数据收集和假设检验方法,相信科学证明因果关系的可能性。例如,探索现有的发现并推断可能在新数据中测试潜在假设。

8(八)请牢记相关性不是因果关系
相关性和因果性对于普罗大众来说很重要,对于科学家或研究者来说特别重要。可以理解为一种应该被掌握的数据思维。读完了上文,恭喜你从一大堆的理论和例子中脱身。最后,重申一下我们的口号:
相关性不是因果关系(correlation is not causation)。

亲爱的数据
出品:谭婧
美编:陈泓宇
